




Web是一种应用,HTTP是支持Web应用的协议。
Web 与 HTTP
一些术语
- Web页:由一些对象组成
- 对象可以是HTML文件、JPEG图像、Java小程序、声音剪辑文件等
- Web页含有一个基本的HTML文件,该基本HTML文件又包含若干对象的引用(链接)【互联网的对象都是通过链接的方式来指向的。HTML文件包含的是对象的链接,不是本身】
- 通过URL对每个对象进行引用
- 访问协议,用户名,口令字,端口等
- URL(通用资源定位符)格式:
【协议名】Prot://【用户:口令】user:psw@【主机名】www.someSchool.edu/【路径名】someDept/【文件名:端口】pic.gif:port
【如果不是特殊情况,不需要提供端口号,不提供时使用的是默认端口号】
HTTP概况
HTTP:超文本传输协议
- Web的应用层协议
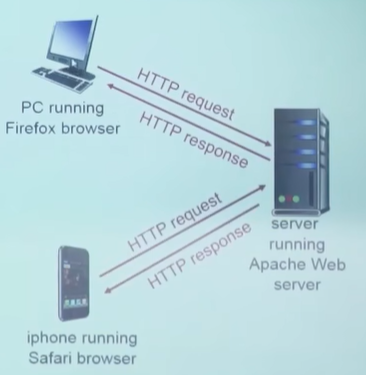
- 客户、服务器模式【浏览器和服务器首先要建立起TCP的连接,在这个连接之上,发送HTTP的请求,然后web服务器收到这个请求之后,再把客户端请求的对象封装成HTTP响应的报文,然后回转回来】
- 客户:请求、接收和显示Web对象的浏览器
- 服务器:对请求进行响应,发送对象的Web服务器
- HTTP 1.0:RFC 1945
- HTTP 1.1:RFC 2068
使用TCP:
- 客户发起一个与服务器的TCP连接(建立套接字),端口号为80
- 服务器接受客户的TCP连接
- 在浏览器(HTTP客户端)与web服务器(HTTP服务器server)交换HTTP报文(应用层协议报文)
- TCP连接关闭
HTTP是无状态的
- 服务器并不维护关于客户的任何信息【无状态的服务器】
维护状态的协议很复杂!
- 必须维护历史信息(状态)
- 如果服务器、客户端死机,它们的状态信息可能不一致,二者的信息必须是一致的
- 无状态的服务器能够支持更多的客户端
HTTP连接
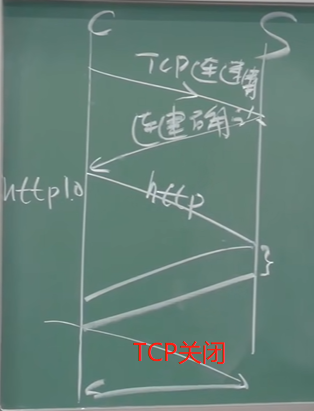
非持久HTTP
- 最多只有一个对象在TCP连接上发送
- 下载多个对象需要多个TCP连接
- HTTP/1.0使用非持久连接
【TCP建立连接的时间+http请求报文时间(报文相对于对象小很多,所以一般可以忽略不计)+http响应对象传输时间+TCP连接关闭时间】
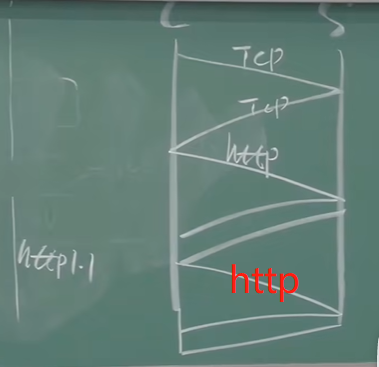
持久HTTP
- 多个对象可以在一个(在客户端和服务器之间)TCP连接上传输
- HTTP/1.1默认使用持久连接
【持久HTTP,在TCP连接建立后进行HTTP报文连接请求,对象回来,传输完之后,TCP连接不关,在这个连接上如果还有其他http报文的连接请求,对象回来,可以继续进行】
【Web浏览器和Web服务器在建立连接的时候,需要下层的协议实体进行一次交互才能完成】
非持久HTTP


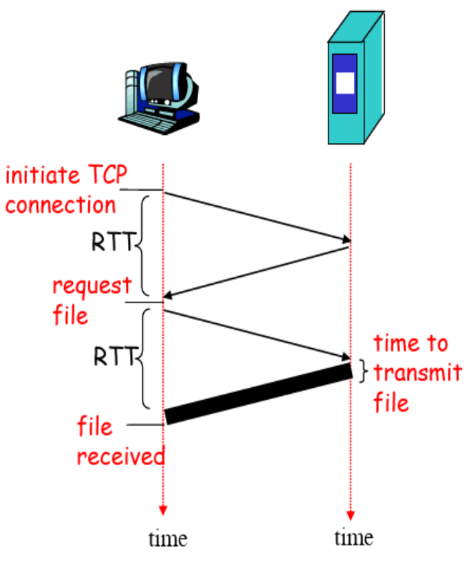
非持久HTTP的响应时间
往返时间RTT(round-trip time):一个小的分组从客户端到服务器,在回到客户端的时间(传输时间忽略)【因为是小的分组,字节数很少,所以忽略不计,传输不许时间,传播需要时间】
响应时间:
- 一个RTT用来发起TCP连接
- 一个RTT用来HTTP请求并等待HTTP响应
- 文件传输时间
共:2RTT+传输时间【是响应时间,所以没算TCP关闭的时间】
持久HTTP
非持久HTTP的缺点:
- 获取每个对象需要2个RTT
- 每个TCP连接需要消耗操作系统资源
- 浏览器需要打开多个TCP连接,以获取引用对象
持久HTTP
- 服务器在发送响应后,仍保持TCP连接
- 同一对客户-服务器之间的后续HTTP报文可以在该链接上传输
- 客户端在遇到一个引用对象的时候,就可以尽快发送该对象的请求
非流水方式的持久HTTP:
-
- 客户仅当收到前一个响应后再发送新的请求
- 请求每个对象用时1个RTT
流水方式的持久HTTP:
-
- HTTP/1.1的默认模式
- 客户端遇到一个引用对象就立即产生一个请求
- 所有引用(小)对象只花费一个RTT是可能的
HTTP请求报文
- 两种类型的HTTP报文:请求、响应
- HTTP请求报文
- ASCII(人能阅读)

【GET:客户端从服务器请求东西;(头和body都要)
POST:上载
HEAD:请求头部(搜索引擎拿到头建索引)】
【Host:代表主机名;User-agent:用户代理的程序,浏览器的第几个版本;Connection:连接是否关闭;】
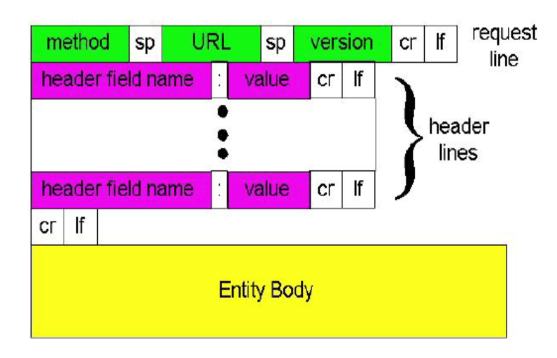
【POST的话,body就要包括需要上载的那些东西(表单)】
提交表单输入
POST方式:
- 网页通常包括表单输入
- 包含在实体主体(entity body)中的输入被提交到服务器
URL方式:
- 方法:GET
- 输入内容通过请求行的URL字段上载
HTTP方法
HTTP/1.0
- GET
- POST
- HEAD
- 要求服务器不返回对象,只用一个报文头响应(实体为空),常用于故障跟踪、建立索引、维护
HTTP/1.1
- GET, POST, HEAD
- PUT
- 将文件放在报文实体中,传到URL字段指定的路径,常用于网页的维护
- DELETE
- 删除URL字段指示的文件
HTTP响应报文
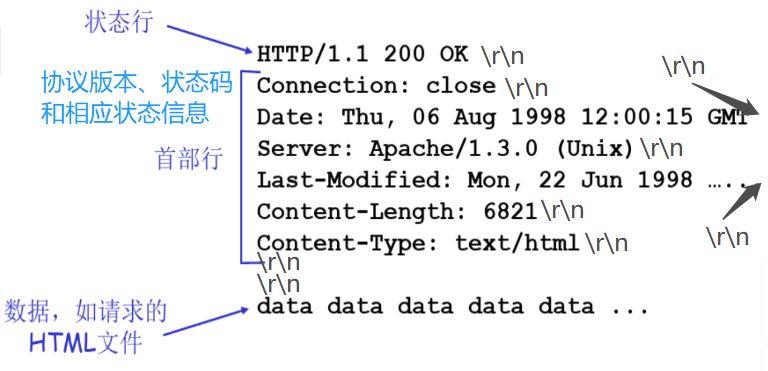
【Last-Modified:请求对象上一次的修改时间;Content-Length:内容的长度,首部行回车之后我要读多少个字节是HTTP响应的内容;】
【HTTP运行在TCP之上,TCP向上层提供的是字节流的服务,不维护上面报文交下来的的边界,所以需要应用层自己去区分哪里是应用报文的头,哪里是应用报文的结束,采用TCP协议,得自己维护报文和报文的界限】
HTTP响应状态码
位于服务器 ➡️ 客户端的响应报文中的首行
一些状态码的例子:
200 OK
-
- 请求成功,请求对象包含在响应报文的后续部分
301 Moved Permanently
-
- 请求的对象已经被永久转移了;新的URL在响应报文的Location:首部行中确定
- 客户端软件自动用新的URL去获取对象
400 Bad Request
-
- 一个通用的差错代码,表示该请求不能被服务器解读
404 Not Found
-
- 请求的文档在该服务上没有找到
505 HTTP Version Not Supported【服务器版本号不支持】
【HTTP是个无状态的协议,服务器不维护客户端的状态,每次客户端发送了请求后,服务器就封装对象发回去,不记录之前或者不管之后的请求,服务器不维护客户端的状态】——好处:简单,同样的服务器资源可以支持的客户端更多一点
用户-服务器状态:cookies
大多数主要的门户网络使用cookies
4个组成部分:
- 在HTTP响应报文中有一个cookie的首部行
- 在HTTP请求报文含有一个cookie的首部行
- 在用户端系统中保留有一个cookie文件,由用户的浏览器管理
- 在Web站点有一个后端数据库
例子:
- Susan总是用同一个PC使用Internet Explore上网
- 她第一次访问了一个使用了Cookie的电子商务网站
- 当最初的HTTP请求到达服务器时,该Web站点产生一个唯一的ID,并以此作为索引在它的后端数据库中产生一个项
【第一次访问的时候,请求上没有cookie,服务端会生成一个cookie,返回给客户端,之后请求的时候,报文就会带上cookie,以此关联出用户的访问行为】
【cookie把HTTP无状态的协议变成一个维护状态的协议,记录客户端的状态】
Cookies:维护状态
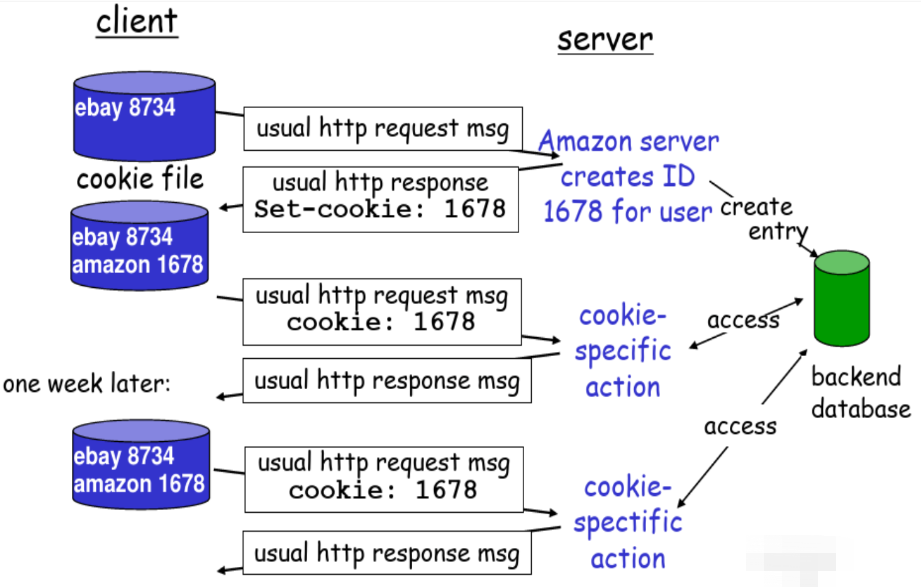
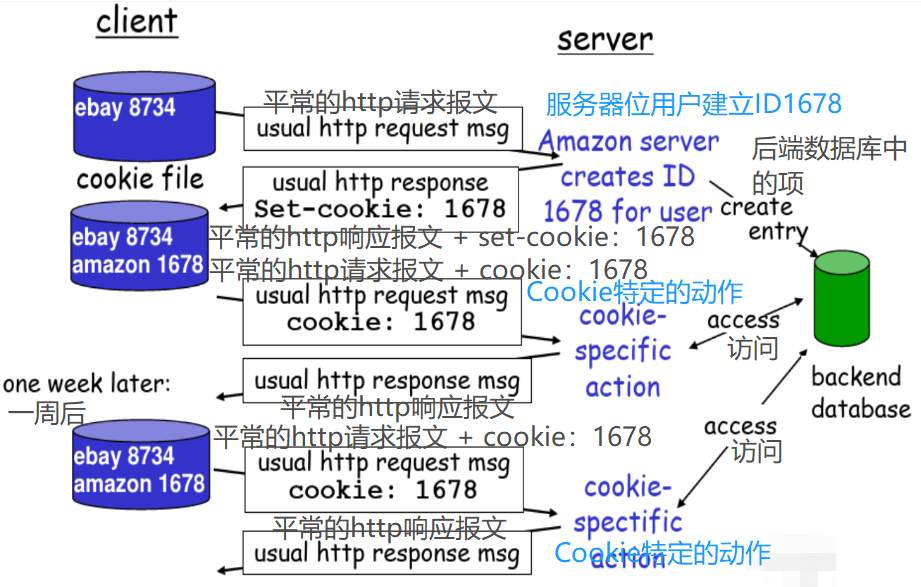
Cookies能带来什么:
- 用户验证
- 购物车
- 推荐
- 用户状态(Web e-mail)
如果维持状态:
- 协议端节点:在多个事务上,发送端和接收端维持状态
- cookies:http报文携带状态信息
Cookies与隐私:
- Cookies允许站点知道许多关于用户的信息
- 可能将它知道的东西卖给第三方
- 使用重定向和cookie的搜索引擎还能知道用户更多的信息
- 如通过某个用户在大量站点上的行为,了解其个人浏览方式的大致模式
- 广告公司从站点获取信息
Web缓存(代理服务器)[Web cache]
目标:不访问原始服务器,就满足客户的请求
代理服务器:代表原始服务器满足HTTP请求的网络实体,保存最近请求过的对象的拷贝。
- 用户设置浏览器:通过缓存访问Web
- 浏览器将所有的HTTP请求发给缓存
- 在缓冲中的对象:缓存直接返回对象【好处:快、服务器端负载更轻、网络的负担也减轻了】
- 如对象不在缓存,缓存请求原始服务器,然后再将对象返回给客户端
- 缓存既是客户端又是服务器
- 通常缓存是由ISP安装(大学、公司、居民区ISP)
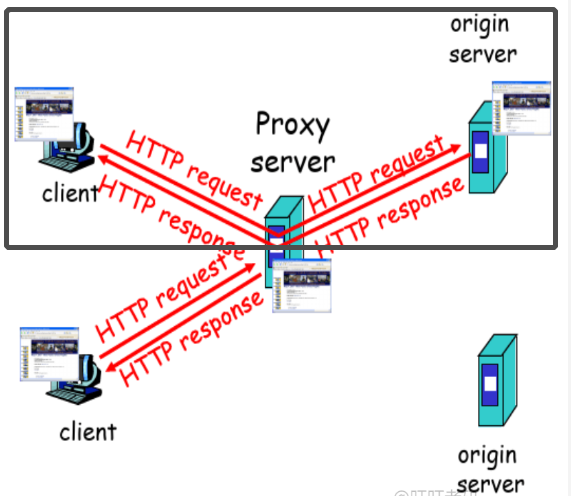
为什么要使用Web缓存?
- 降低客户端的请求响应时间
- 可以大大减少一个机构内部网络与Internet接入链路上的流量
- 互联网大量采用了缓存:可以使较弱的ICP也能够有效提供内容
缓存例子:安装本地缓存
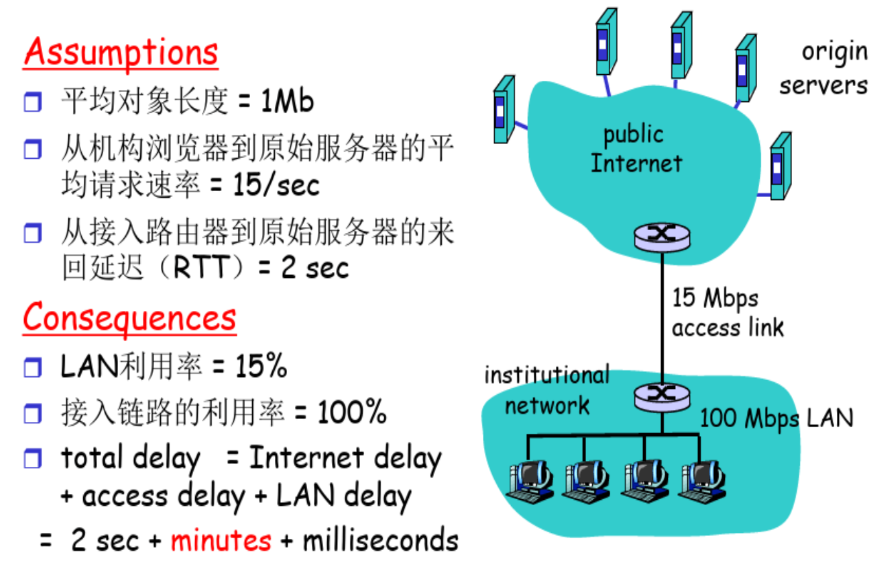
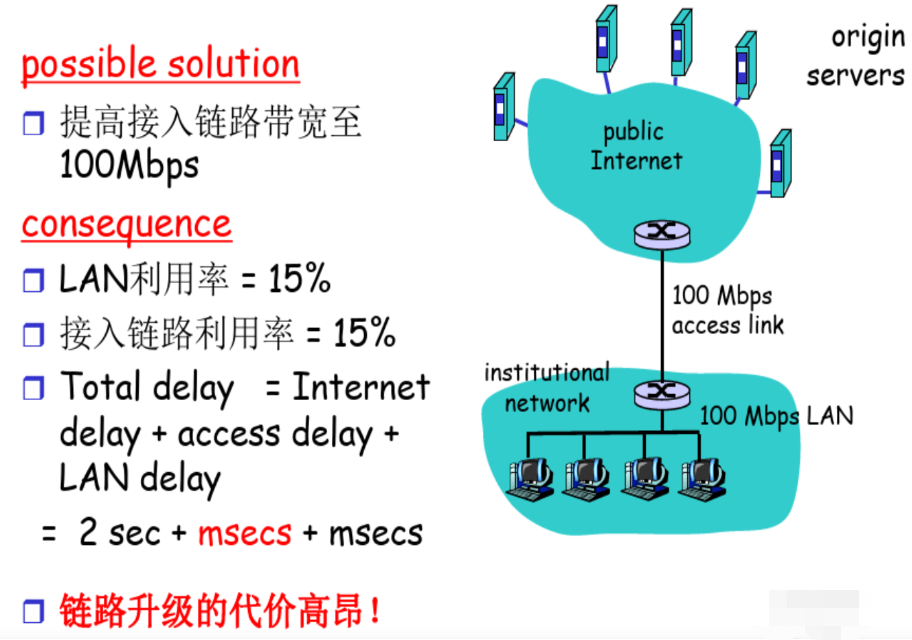
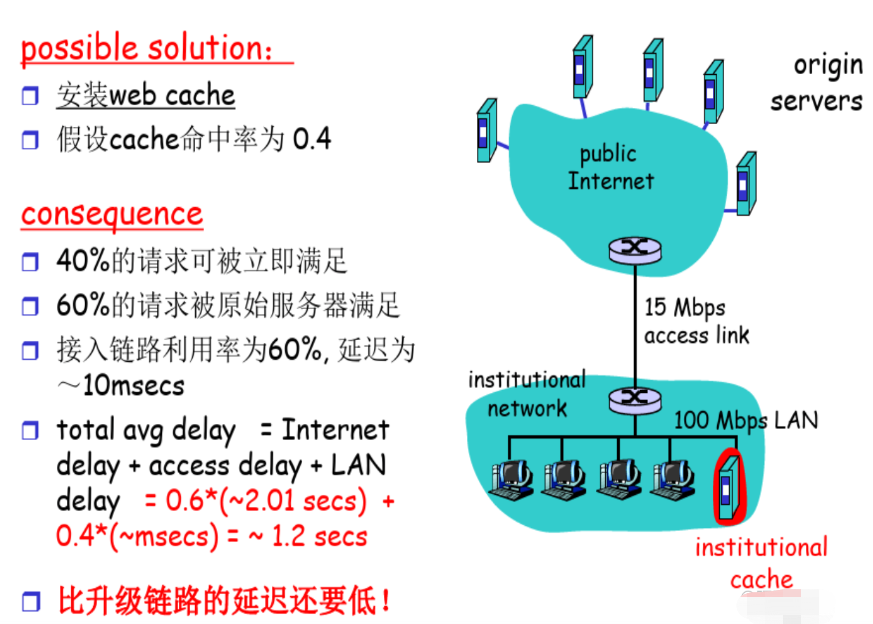
【本地缓存下来的对象,服务器那边可能变了】
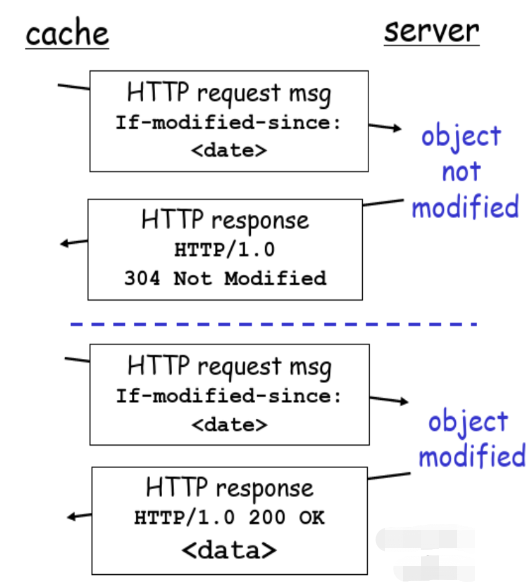
条件GET
代理服务器如何发现缓存的对象是不是新的?
- 目标:如果缓存器中的对象拷贝是最新的,就不要发送对象
- 缓存器:在HTTP请求中指定缓存拷贝的日期
- If-modified-since:
- 服务器:如果发现对象无更新,则响应报文没包含对象:
- HTTP/1.0 304 Not Modified
- 服务器:如果发现对象有更新,响应报文中包含对象

















 317
317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









