




DDIM中遇到的Score-based SDE
这里采用表示神经网络的预测值,用
表示
。同时
等价于

DDPM回顾
贝叶斯公式
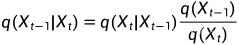
原始公式
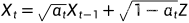
前向过程
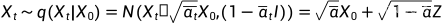
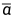 表示连乘
表示连乘
反向过程

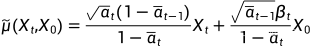
由前向过程可知: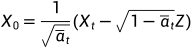
所以: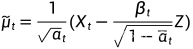
正态分布: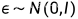
重参数技巧:
反向过程: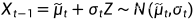
优化目标:
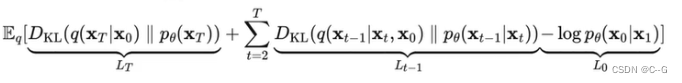
对于两个单一变量的高斯分布 p 和 q而言,KL散度为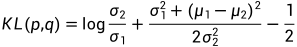
最终简化为: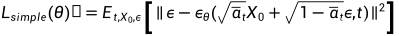
经验贝叶斯估计
根据经验贝叶斯估计,对于应该高斯变量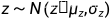 ,有以下结论:
,有以下结论:
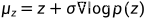
将上式代入前向过程可得
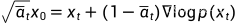
前向过程展开后为: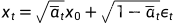 ,对
,对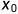 做等价变换
做等价变换
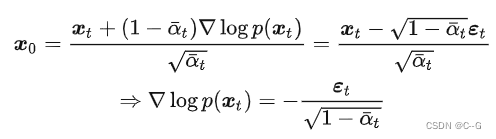
同样的,在DDPM中推导优化目标的时候,是需要先建模出 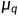 ,然后再用一个神经网络来学习近似它,当时推导的结论是:
,然后再用一个神经网络来学习近似它,当时推导的结论是:
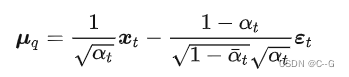
替换 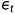 即可以得到一个新的建模方式
即可以得到一个新的建模方式
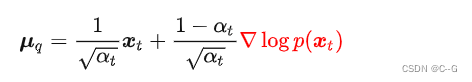
将逆向估计过程建模成
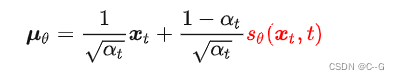
重新推导DDPM中的优化目标
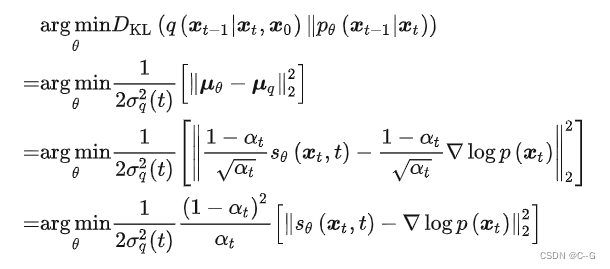
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









