






1、初识数据库
数据库(Database)指长期存储在计算机内的、有组织的、可共享的数据集合。通俗的讲,数据库就是存储数据的地方。

数据库管理系统(DBMS)是数据库系统的核心软件之一,是位于用户与操作系统之间的数据管理软件,用于建立,使用和维护数据库。它的主要功能包括数据定义、数据操作、数据库的运行管理、数据库的建立和维护等几个方面。(Mysql、Oracle等等)。
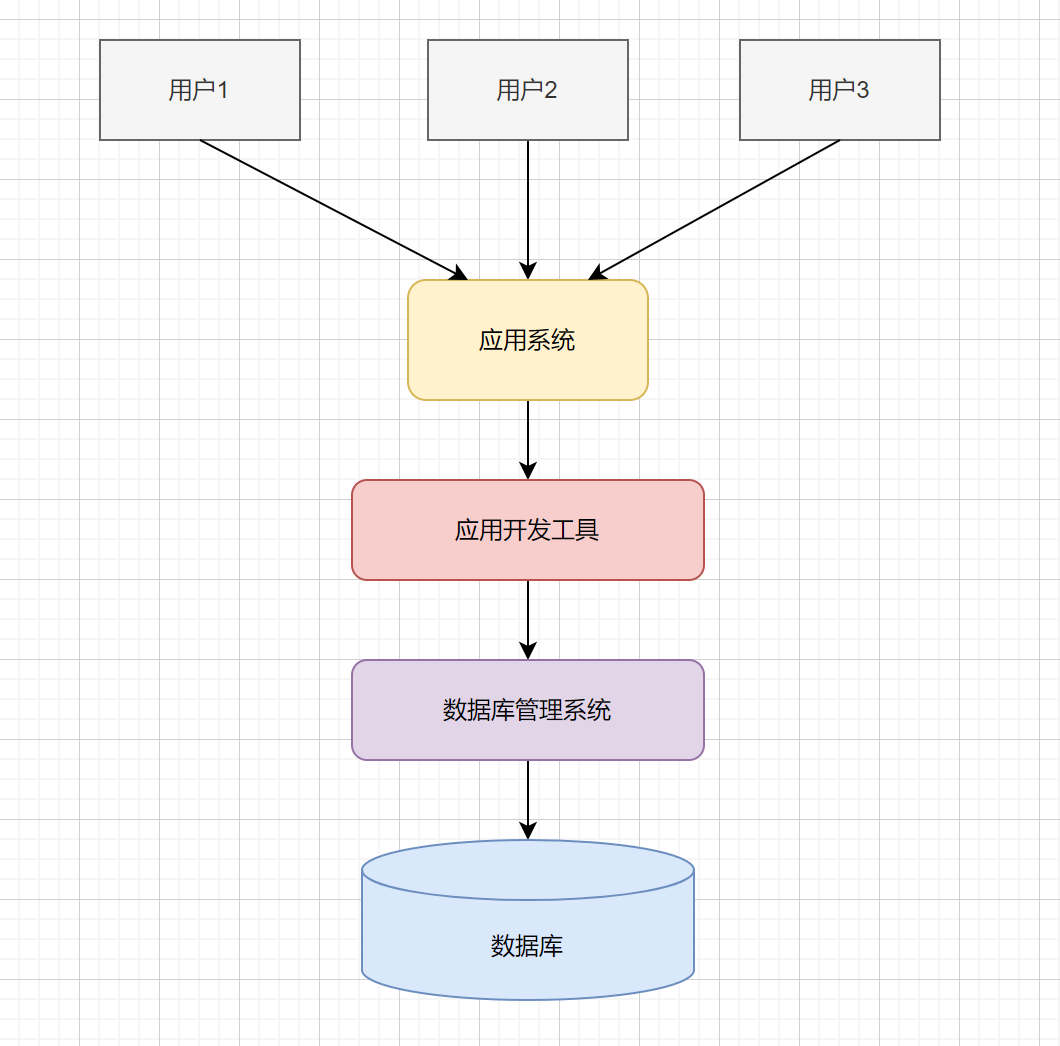
数据库系统(Database System,DBS)由硬件和软件共同构成。硬件主要用于存储数据库中的数据,包括计算机、存储设备等。软件部分主要包括数据库管理系统、支持数据库管理系统运行的操作系统,以及支持多种语言进行应用开发的访问技术等。
数据库系统(DBS) = 硬件 + 软件
数据库系统示例:
数据库的分类:
关系型数据库(Relational Database)
关系型数据库是一种基于关系模型(表格、行、列)来存储和管理数据的数据库。它使用结构化查询语言(SQL)来操作数据,数据按照表格的形式存储在数据库中,表与表之间可以通过外键(foreign key)来建立关联。
关系型数据库的特点:
- 结构化数据:数据被组织成表格,每个表由行和列组成。每一行代表一条记录,每一列代表该记录的某个属性。
- ACID特性:关系型数据库通常遵循ACID事务特性,确保数据的一致性、完整性和持久性。
- 强大的查询语言(SQL):通过SQL,可以进行复杂的查询、插入、更新和删除操作。
- 规范化:关系型数据库通过规范化过程来减少冗余数据,确保数据的完整性和一致性。
- 数据关系:表与表之间通过外键建立关系,能够轻松进行关联查询(JOIN)。
关系型数据库的类型:
- 单一数据库管理系统(如 MySQL、PostgreSQL、Oracle、SQL Server)
- 分布式数据库管理系统(如 Google Spanner)
关系型数据库的例子:
- MySQL:一种开源的关系型数据库管理系统,广泛应用于Web开发中,支持ACID事务和SQL查询。
- PostgreSQL:一个功能强大的开源数据库,支持复杂查询、数据完整性和标准SQL。
- Oracle:一款商业数据库系统,广泛应用于企业级应用中,提供强大的性能和可扩展性。
- SQL Server:由微软开发,广泛用于企业级数据库管理,支持高级的SQL查询和数据分析功能。
非关系型数据库(NoSQL)
非关系型数据库是一类不使用传统关系模型(如表格、行和列)来存储数据的数据库。它们通常设计为更灵活、可扩展,适用于大数据、实时数据处理、分布式系统等场景。与关系型数据库相比,非关系型数据库在数据结构、查询方式、扩展性等方面更具灵活性。
非关系型数据库的特点:
- 灵活的数据模型:非关系型数据库通常使用键值对、文档、列族或图形等不同的数据模型,能够存储结构化、半结构化或非结构化数据。
- 高扩展性:许多非关系型数据库支持水平扩展,可以通过增加更多的服务器来处理更大的数据量。
- 高性能:许多非关系型数据库在处理大规模数据时具有较高的性能,适合实时查询和快速读写。
- 不支持ACID事务:非关系型数据库通常不完全遵循传统的ACID(原子性、一致性、隔离性、持久性)事务模型,而是支持最终一致性(Eventual Consistency)。
非关系型数据库的类型:
- 键值数据库(Key-Value Stores):每个数据项都由一个唯一的键和与之相关联的值组成。常见的例子有 Redis 和 Riak。
- 文档数据库(Document Stores):存储文档格式的数据,通常是 JSON、BSON 或 XML 格式。常见的例子有 MongoDB 和 CouchDB。
- 列族数据库(Column-Family Stores):以列为单位存储数据,而不是传统的行。这类数据库适合处理大规模的分布式数据。常见的例子有 Apache Cassandra 和 HBase。
- 图形数据库(Graph Databases):用于存储和查询图形数据,特别适合处理关系复杂的数据,如社交网络中的关系。常见的例子有 Neo4j 和 ArangoDB。
非关系型数据库的例子:
- MongoDB:一个文档型数据库,数据以 BSON 格式存储,可以灵活地处理不同结构的数据。
- Cassandra:一个列族型数据库,适用于处理大规模分布式数据,特别是在实时数据分析和大数据存储中非常流行。
- Redis:一个键值型数据库,广泛用于缓存和会话管理。
2、Mysql是什么?
MySQL 是一个开源的关系型数据库管理系统(RDBMS),它使用 SQL(结构化查询语言)来管理和操作数据。MySQL 最早由瑞典 MySQL AB 公司开发,现已成为 Oracle 公司的一部分。
MySQL 的特点:
- 开源免费:MySQL 是一个开源项目,可以自由使用和修改,适合各种规模的项目。
- 支持SQL查询:MySQL 使用标准的 SQL 语法来管理数据,可以进行数据查询、插入、更新和删除等操作。
- 高性能:MySQL 采用了多种优化技术,提供了良好的性能,特别是在读取大量数据时。
- 事务支持:MySQL 支持事务,可以确保数据的一致性和完整性(ACID)。
- 跨平台支持:MySQL 可以运行在多种操作系统上,包括 Linux、Windows、macOS 等。
- 支持多种存储引擎:如 InnoDB、MyISAM 等,用户可以根据需求选择不同的存储引擎,优化数据库性能。
3、数据库的设计
1、数据库设计的步骤
1.需求分析:收集并分析应用程序的需求,确定需要存储和处理的数据。
2.概念设计:使用ER模型(实体-关系模型)来设计数据库的高层结构,定义实体、属性和关系。
3.逻辑设计:将概念模型转化为关系模型,设计表结构,确定主键、外键及字段属性。
4.物理设计:优化数据库的存储结构和访问性能,确定索引、分区等优化方案。
5.实施与编码:根据设计的结构创建数据库,并编写SQL语句来实现功能。
6.测试与优化:对数据库进行测试,确保其性能和正确性,优化查询和存储过程。
7.维护与更新:数据库投入使用后,持续进行监控、调整和更新,以应对变化的需求。
2、学校管理系统的数据库设计
1、需求分析
在这个学校管理系统中,我们需要管理学生的个人信息、他们所修读的课程以及他们的成绩。此外,每门课程由不同的老师授课,系统需要记录这些关系。
需求分析:
- 学生管理:
-
- 每个学生有唯一的学号(
s_id)。 - 记录学生的基本信息(姓名、年龄、性别等)。
- 每个学生有唯一的学号(
- 课程管理:
-
- 每门课程有课程编号(
c_id)、课程名称、学分、老师编号(t_id)等。 - 每门课程由一名或多名老师教授。
- 每门课程有课程编号(
- 成绩管理:
-
- 每个学生有多个成绩记录,关联到不同的课程。
- 每个成绩记录包括学生的成绩、课程和成绩日期等。
- 老师管理:
-
- 每个老师有唯一的工号(
t_id),并教授一门或多门课程。
- 每个老师有唯一的工号(
2、概念设计(E-R模型)
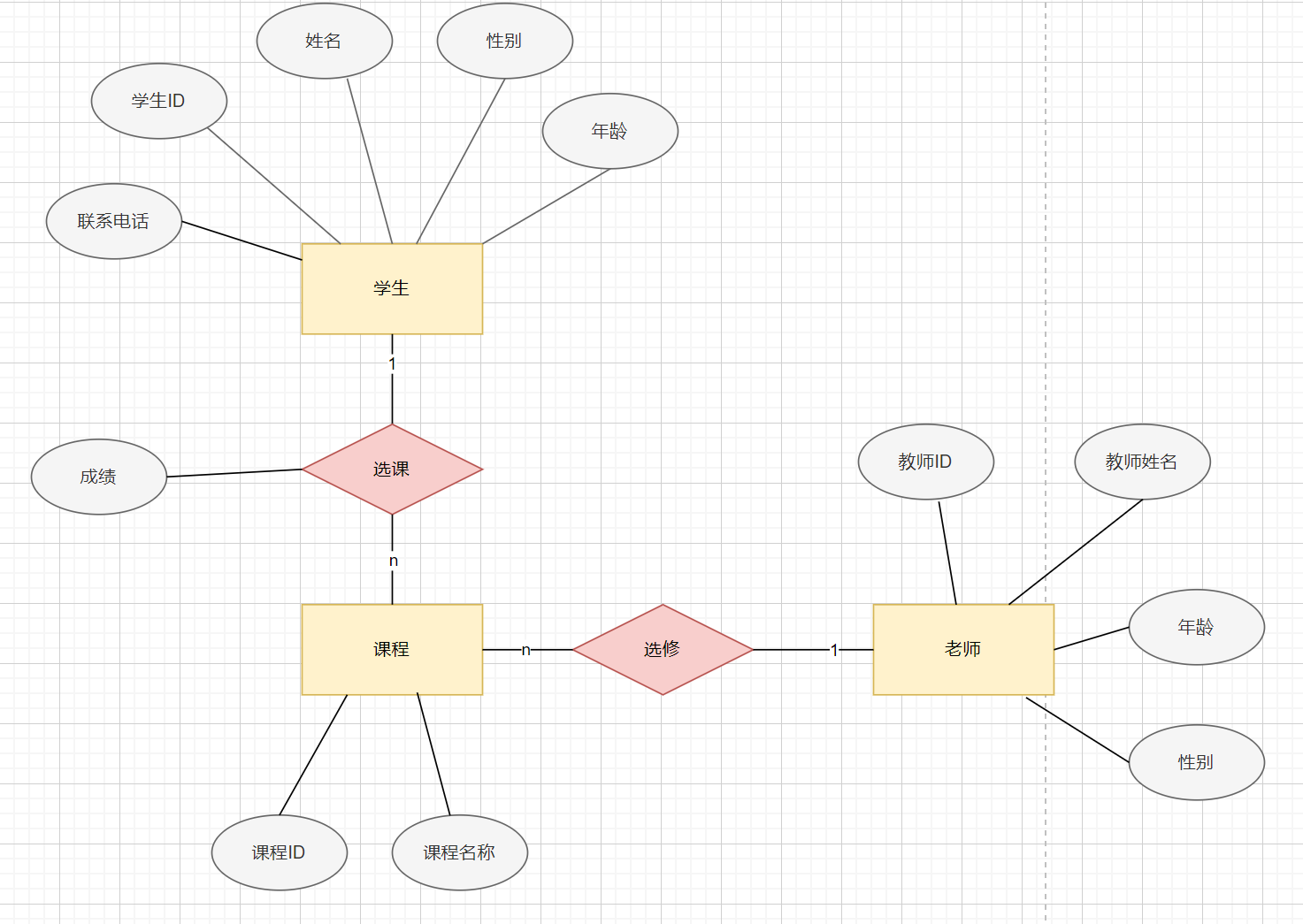
在理解业务后,使用 E-R(实体-关系)模型 进行建模,确定数据库中有哪些实体、属性,以及它们之间的关系。
- 实体(Entity):数据库中的核心对象,例如 学生、老师、课程。 用矩形表示
- 属性(Attribute):实体的特征,如用户的 姓名、年龄、性别。用椭圆表示
- 关系(Relationship):实体之间的关联,比如老师和课程是 一对多 关系。用菱形表示
什么是E-R图?
E-R图,即实体-关系图(Entity-Relationship Diagram),是数据库建模的一种工具,用于表示实体类型、属性以及它们之间的关系。
在E-R图中,实体用矩形表示,属性用椭圆表示,而它们之间的关系用菱形表示。实体之间通过线连接,并在连接线上标明它们之间的基数关系,如1:1、1:n或n:m等。
3、逻辑设计
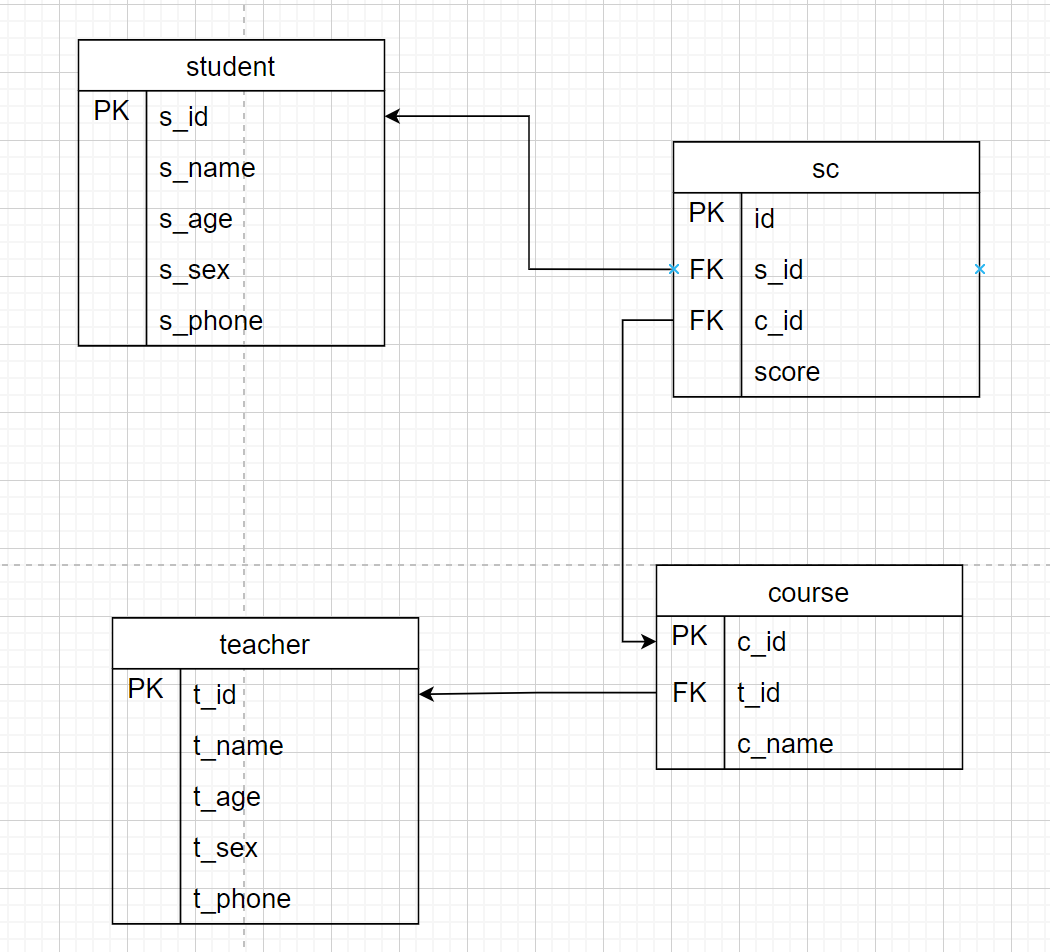
在逻辑设计阶段,ER图被转化为关系模型(Relational Model)。关系模型使用表(Table)来表示实体,字段(Field)来表示属性。
关系模型转换:
实体转表:每个实体被转换为数据库中的一张表。例如,“学生”实体会转化为“学生”表。
属性转列:每个属性会转化为表中的列。例如,“姓名”属性会转化为“学生”表中的一列。
关系转外键:如果有两个实体之间的关系,通常通过外键来表示。例如,“学生”和“课程”之间的“选修”关系,可以通过在“选课”表中加入“学生ID”和“课程ID”作为外键来实现。
转换为规范化的关系模型(关系模式):
学生(学生ID,姓名,性别,年龄,联系电话)
教师(教师ID, 姓名, 性别, 年龄)
课程(课程ID,教师ID, 课程名)
成绩(学生ID, 课程ID, 成绩)
模型图绘制:
3、数据库的设计规范
三大范式是 Mysql 数据库设计表结构所遵循的规范和指导⽅法,⽬的是为了减少冗余,建⽴结构合理的
数据库,从⽽提⾼数据存储和使⽤的性能。
三⼤范式之间是具有依赖关系的,⽐如第⼆范式是在第⼀范式的基础上建设的、第三范式是在第⼆范式
的基础上建设的。
当然 Mysql 数据库的范式不⽌三⼤范式,除了三⼤范式,还有巴斯-科德范式(BCNF)、第四范式
(4NF)、第五范式(5NF,⼜称“完美范式")。
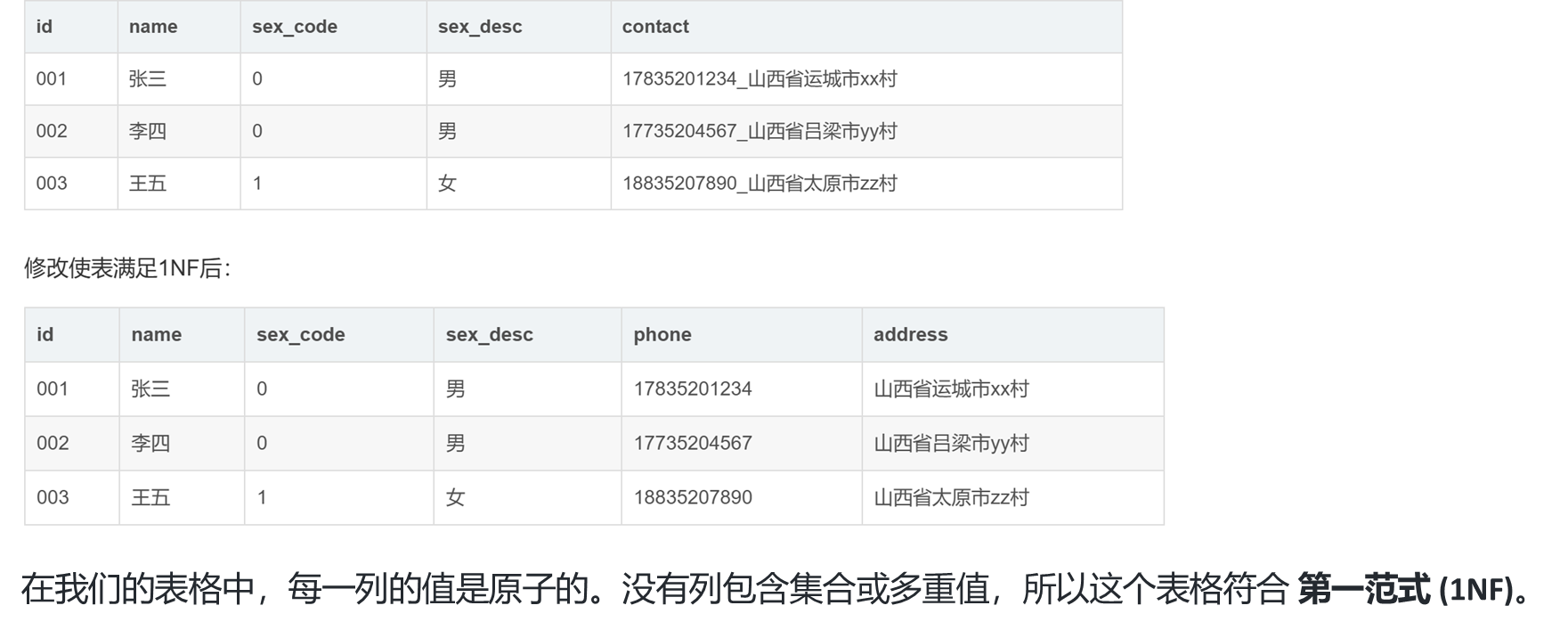
范式化:为了避免数据冗余和数据异常,关系模型通常会经过范式化(Normalization)。范式化过程包括将数据库表格拆分成多个表格,使得数据结构更加规范。
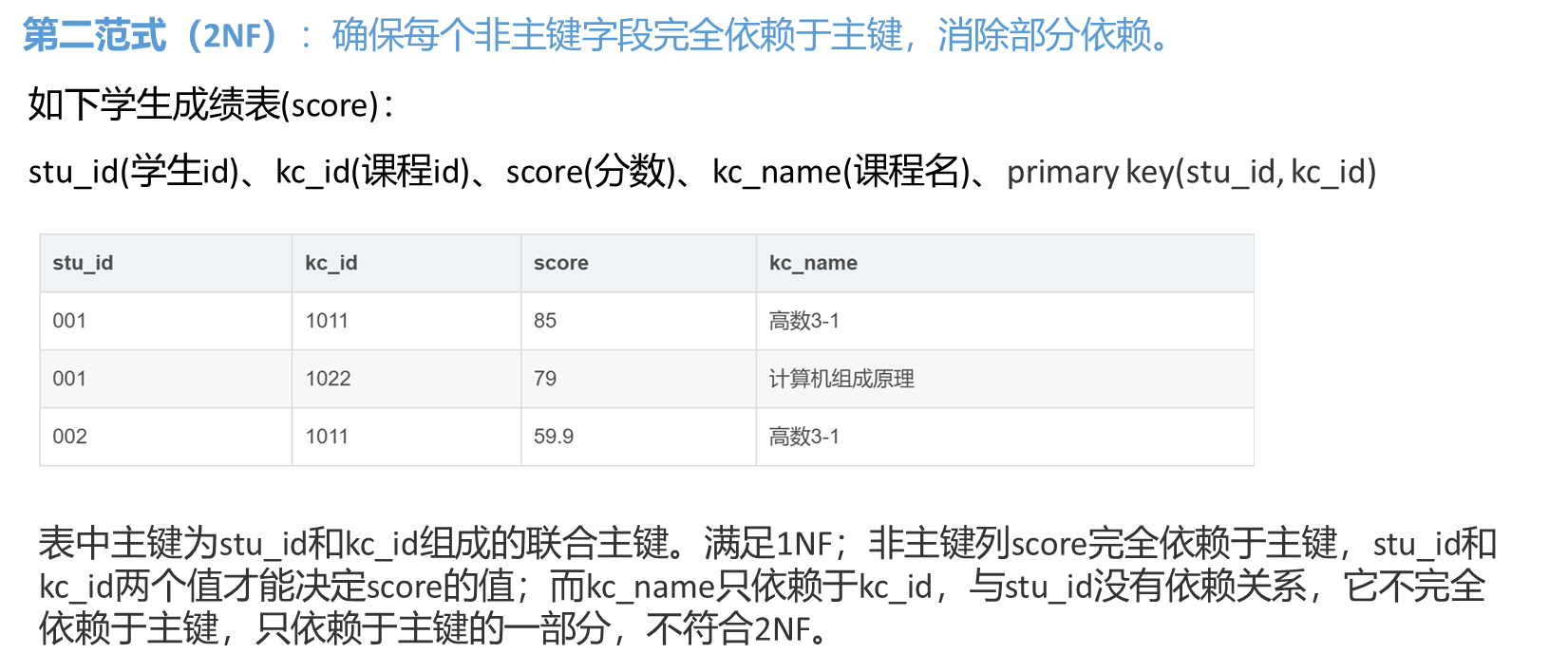
第一范式(1NF):确保每个字段都是原子性的,即每个字段只能存储单一值,不能有重复组。
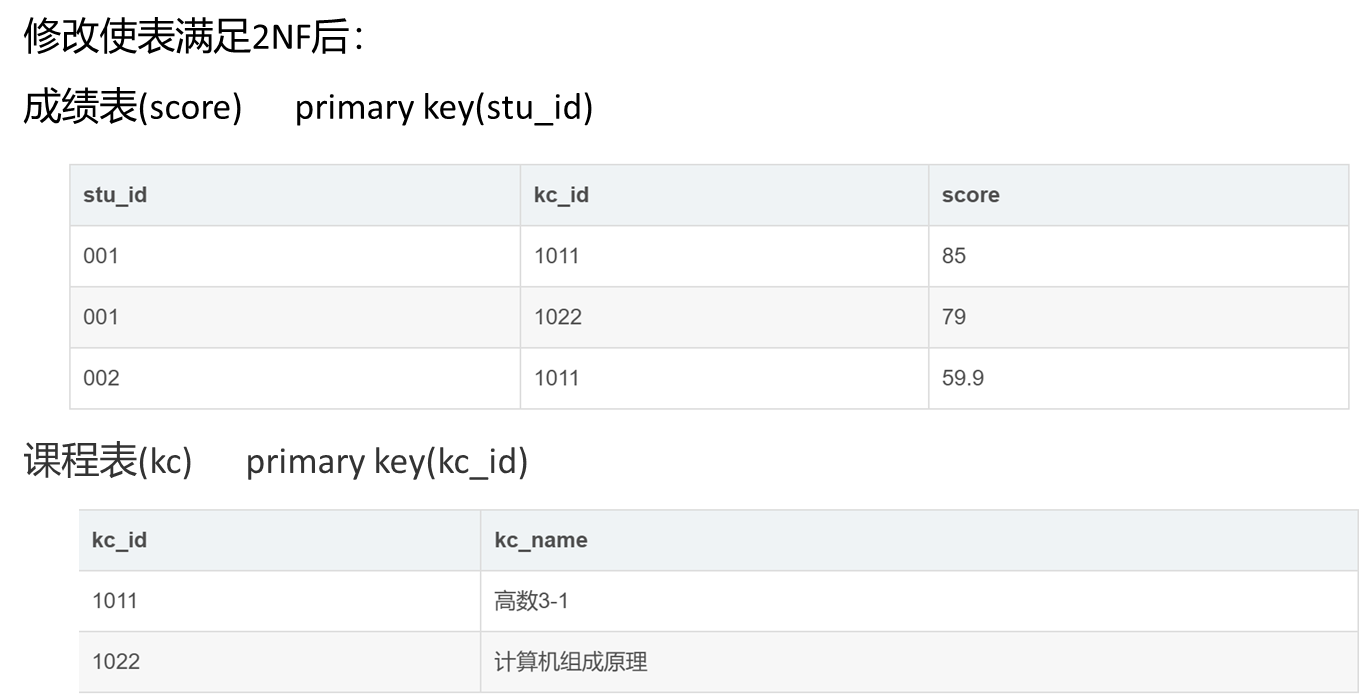
第二范式(2NF):确保每个非主键字段完全依赖于主键,消除部分依赖。
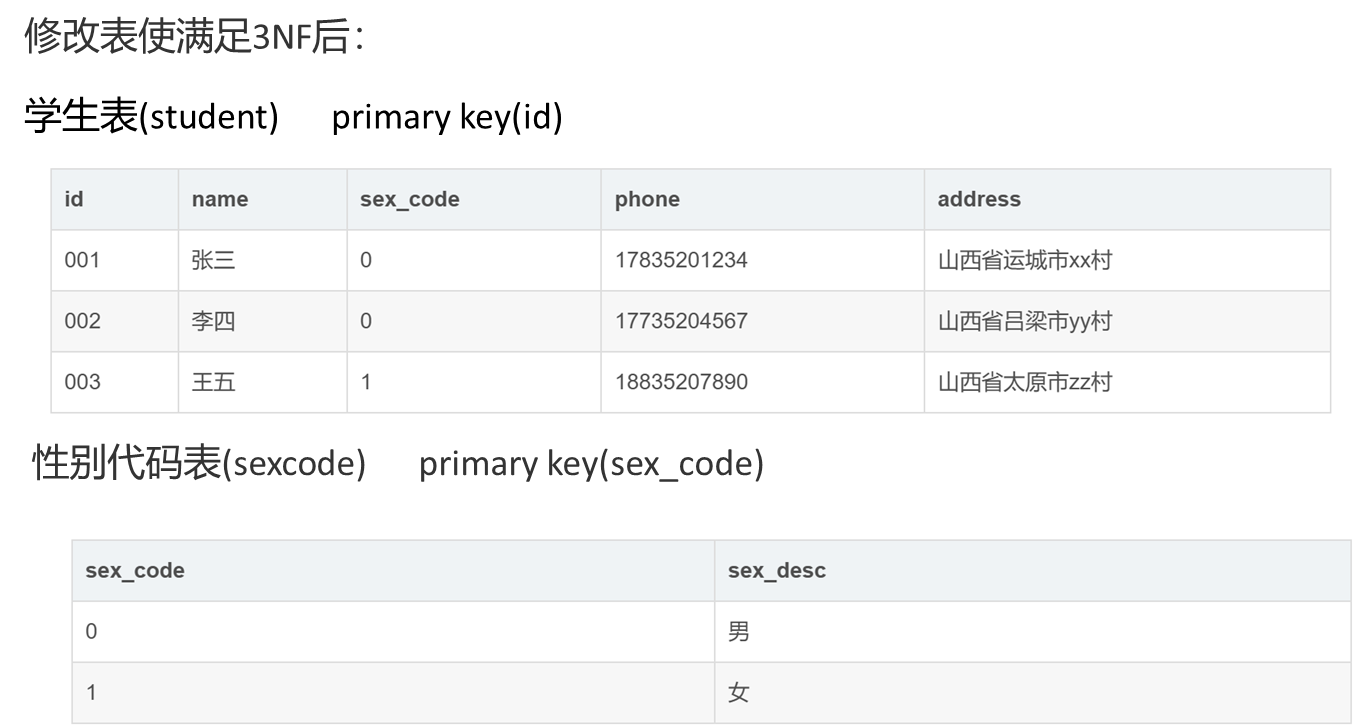
第三范式(3NF):确保每个非主键字段不依赖于其他非主键字段,消除传递依赖。
第一范式(1NF):关系模型中的每个字段必须是原子性的(不可再分解),即每个字段只能包含单一值。

4、了解主外键
- 主键(Primary Key)
主键是表中的一个字段(或多个字段的组合),其主要作用是唯一标识表中的每一行记录。主键具有以下特性:
唯一性:主键字段的值在整个表中必须唯一。没有两条记录可以有相同的主键值。
非空:主键字段的值不能为 NULL。每个记录都必须有一个有效的主键值。
唯一标识记录:通过主键字段,可以快速且唯一地识别表中的一条记录。 - 外键(Foreign Key)
外键是表中的一个字段,它指向另一张表中的主键。外键用于建立和维护表与表之间的关系,确保数据的一致性和完整性。
外键具有以下特性:
参照完整性:外键约束确保外键字段的值在目标表的主键字段中存在。即,外键所引用的字段值必须是目标表主键的有效值。
可以为空:外键字段的值可以是 NULL,表示当前记录不与任何目标记录相关联。
多对一关系:外键通常用于实现一对多关系(例如,一个学生可以选择多门课程,但每门课程只能关联一个教师)。
4、数据库的基本操作
用来创建或删除数据库以及表等对象,主要包含以下几种命令:
DROP:删除数据库和表等对象
CREATE:创建数据库和表等对象
ALTER:修改数据库和表等对象的结构
2)数据操作语言(Data Manipulation Language,DML)
用来变更表中的记录,主要包含以下几种命令:SELECT:查询表中的数据
INSERT:向表中插入新数据
UPDATE:更新表中的数据
DELETE:删除表中的数据
3)数据查询语言(Data Query Language,DQL)
用来查询表中的记录,主要包含 SELECT 命令,来查询表中的数据。
4)数据控制语言(Data Control Language,DCL)
用来确认或者取消对数据库中的数据进行的变更。除此之外,还可以对数据库中的用户设定权限。主要包含以下几种命令:
GRANT:赋予用户操作权限
REVOKE:取消用户的操作权限
COMMIT:确认对数据库中的数据进行的变更
ROLLBACK:取消对数据库中的数据进行的变更
MYSQL数据库操作
1、查看数据库
SHOW DATABASES [LIKE '数据库名'];
-- 查看数据库
SHOW DATABASES;
-- 查看指定数据库,例如:以‘s’开头的数据库
SHOW DATABASES LIKE 's%';
2、创建数据库
CREATE DATABASE [IF NOT EXISTS] <数据库名>
[[DEFAULT] CHARACTER SET <字符集名>]
[[DEFAULT] COLLATE <校对规则名>];
-- 创建数据库
CREATE DATABASE IF NOT EXISTS my_database
DEFAULT CHARACTER SET utf8mb4
DEFAULT COLLATE utf8mb4_general_ci;
3、修改数据库
ALTER DATABASE [数据库名] {
[ DEFAULT ] CHARACTER SET <字符集名> |
[ DEFAULT ] COLLATE <校对规则名>}
-- 将校对规则改为 utf8mb4_unicode_ci
ALTER DATABASE my_database
CHARACTER SET utf8
COLLATE utf8_unicode_ci;
-- 查看当前数据库的字符集和排序规则
SHOW CREATE DATABASE my_database;
4、删除数据库
DROP DATABASE [ IF EXISTS ] <数据库名>
-- 删除数据库
DROP DATABASE my_database;
5、使用数据库
-- 使用数据库
USE <数据库名>
-- 使用数据库
USE my_database;
6、列出当前数据库中所有的表
-- 列出当前数据库中所有的表
SHOW TABLES;7、查询当前数据库的版本
-- 查询当前数据库的版本
SELECT VERSION();5、Mysql的数据类型
1) 数值类型
整数类型包括 TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT,浮点数类型包括 FLOAT 和 DOUBLE,定点数类型为 DECIMAL。
2) 日期/时间类型
包括 YEAR、TIME、DATE、DATETIME 和 TIMESTAMP。
3) 字符串类型
包括 CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM 和 SET 等。
4) 二进制类型
包括 BIT、BINARY、VARBINARY、TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB。
1、整数类型
| 类型名称 | 说明 | 存储需求 |
| TINYINT | 很小的整数 | 1个字节 |
| SMALLINT | 小的整数 | 2个宇节 |
| MEDIUMINT | 中等大小的整数 | 3个字节 |
| INT | 普通大小的整数 | 4个字节 |
| BIGINT | 大整数 | 8个字节 |
2、小数类型
MySQL 中使用浮点数和定点数来表示小数。
浮点类型有两种,分别是单精度浮点数(FLOAT)和双精度浮点数(DOUBLE);
定点类型只有一种,就是 DECIMAL。
浮点类型和定点类型都可以用(M, D)来表示,其中`M`称为精度,表示总共的位数;`D`称为标度,表示小数的位数。
浮点数类型的取值范围为 M(1~255)和 D(1~30,且不能大于 M-2),分别表示显示宽度和小数位数。M 和 D 在 FLOAT 和DOUBLE 中是可选的,FLOAT 和 DOUBLE 类型将被保存为硬件所支持的最大精度。DECIMAL 的默认 D 值为 0、M 值为 10。
| 类型名称 | 说明 | 存储需求 |
| FLOAT | 单精度浮点数 | 4 个字节 |
| DOUBLE | 双精度浮点数 | 8 个字节 |
| DECIMAL (M, D),DEC | 压缩的“严格”定点数 | M+2 个字节 |
在 MySQL 中,定点数以字符串形式存储,在对精度要求比较高的时候(如货币、科学数据),使用 DECIMAL 的类型比较好,另外两个浮点数进行减法和比较运算时也容易出问题,所以在使用浮点数时需要注意,并尽量避免做浮点数比较。
3、日期和时间类型
| 类型名称 | 日期格式 | 日期范围 | 存储需求 |
| YEAR | YYYY | 1901 ~ 2155 | 1 个字节 |
| TIME | HH:MM:SS | -838:59:59 ~ 838:59:59 | 3 个字节 |
| DATE | YYYY-MM-DD | 1000-01-01 ~ 9999-12-3 | 3 个字节 |
| DATETIME | YYYY-MM-DD HH:MM:SS | 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 | 5 个字节/8个字节 |
| TIMESTAMP | YYYY-MM-DD HH:MM:SS | 1970-01-01 00:00:01’UTC ~‘2038 01-19 03:14:07’UTC | 4 个字节 |
DATETIME 类型与 TIMESTAMP 类型的区别:
DATETIME 类型用于需要同时包含日期和时间信息的值,在存储时需要 5字节(MySQL 5.6.4之前为8字节)。日期格式为 'YYYY-MM-DD HH:MM:SS',其中 YYYY 表示年,MM 表示月,DD 表示日,HH 表示小时,MM 表示分钟,SS 表示秒。
DATETIME的取值范围:1000-01-01 00:00:00 ~ 9999-12-31 23:59:59
DATETIME:不受时区影响,存储的时间是具体的日期和时间,不会进行自动转换,按实际输入的格式存储,即输入什么就存储什么,与时区无关。
TIMESTAMP 的显示格式与 DATETIME 相同,显示宽度固定在 19 个字符,日期格式为 YYYY-MM-DD HH:MM:SS,在存储时需要 4 个字节。
TIMESTAMP 的取值范围:1970-01-01 00:00:01’ UTC 到 ‘2038 01-19 03:14:07’UTC
TIMESTAMP:受时区影响,存储时会转换为UTC,取出时会根据连接的时区进行转换,适合处理跨时区的数据。
4、字符串类型
字符串类型用来存储字符串数据,还可以存储图片和声音的二进制数据。字符串可以区分或者不区分大小写的串比较,还可以进行正则表达式的匹配查找。
Mysql中的字符串类型有 CHAR、VARCHAR、TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXT、ENUM、SET等。
| 类型名称 | 说明 | 存储需求 |
| CHAR(M) | 固定长度非二进制字符串 | M 字节,1<=M<=255 |
| VARCHAR(M) | 变长非二进制字符串 | L+1字节,在此,L< = M和 1<=M<=255 |
| TINYTEXT | 非常小的非二进制字符串 | L+1字节,在此,L<2^8 |
| TEXT | 小的非二进制字符串 | L+2字节,在此,L<2^16 |
| MEDIUMTEXT | 中等大小的非二进制字符串 | L+3字节,在此,L<2^24 |
| LONGTEXT | 大的非二进制字符串 | L+4字节,在此,L<2^32 |
| ENUM | 枚举类型,只能有一个枚举字符串值 | 1或2个字节,取决于枚举值的数目 (最大值为65535) |
| SET | 一个设置,字符串对象可以有零个或 多个SET成员 | 1、2、3、4或8个字节,取决于集合 成员的数量(最多64个成员) |
CHAR 和 VARCHAR的区别:
- 存储方式
CHAR:CHAR是固定长度的字符串类型。无论实际存储的字符串长度是多少,CHAR类型的字段都会占用固定的空间。例如,CHAR(10)类型的字段,无论存储的字符串是 "abc" 还是 "abcdefghij",都会占用 10 个字符的空间。如果存储的字符串长度小于定义的长度,MySQL 会在字符串的末尾填充空格以达到指定的长度。
VARCHAR:VARCHAR是可变长度的字符串类型。VARCHAR类型的字段根据实际存储的字符串长度来分配空间。例如,VARCHAR(10)类型的字段,存储 "abc" 只占用 3 个字符的空间(加上一个额外的字节用于存储字符串的长度)。VARCHAR类型的字段在存储时会记录实际字符串的长度,因此不会有额外的空格填充。
- 存储效率
CHAR:由于是固定长度,CHAR类型的字段在存储和检索时效率较高,特别适用于存储长度固定的字符串(如国家代码、邮政编码等)。但对于长度变化较大的字符串,CHAR类型可能会浪费大量的存储空间。
VARCHAR:VARCHAR类型的字段在存储空间上更节省,因为它只分配实际需要的空间。对于长度变化较大的字符串,VARCHAR类型更加合适。
- 性能
CHAR:由于固定长度,CHAR类型的字段在进行比较和检索时速度较快。适用于需要频繁查询和比较的字段。
VARCHAR:VARCHAR类型的字段在存储和检索时需要额外的长度信息,因此在某些情况下性能可能稍逊于CHAR。适用于长度不固定且不需要频繁比较的字段。
- 使用场景
CHAR:适用于存储长度固定的字符串,如固定长度的编码、标识符等。例如,存储国家代码(如 "USA"、"CHN")或邮政编码(如 "12345")。
VARCHAR:适用于存储长度可变的字符串,如姓名、地址、描述等。例如,存储用户的姓名、电子邮件地址或文章内容。
5、二进制类型
MySQL 中的二进制字符串有 BIT、BINARY、VARBINARY、TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB。
| 类型名称 | 说明 | 存储需求 |
| BIT(M) | 位字段类型 | 大约 (M+7)/8 字节 |
| BINARY(M) | 固定长度二进制字符串 | M 字节 |
| VARBINARY (M) | 可变长度二进制字符串 | M+1 字节 |
| TINYBLOB (M) | 非常小的BLOB | L+1 字节,在此,L<2^8 |
| BLOB (M) | 小 BLOB | L+2 字节,在此,L<2^16 |
| MEDIUMBLOB (M) | 中等大小的BLOB | L+3 字节,在此,L<2^24 |
| LONGBLOB (M) | 非常大的BLOB | L+4 字节,在此,L<2^32 |
6、MySQL的约束
4、检查约束 (CHECK):确保列中的数据符合特定条件。
5、非空约束 (NOT NULL):确保列不允许 NULL 值。
6、默认值约束 (DEFAULT):为列提供一个默认值,便于数据插入时自动填充。
约束的优点:
1、数据完整性:确保数据符合预定规则,防止无效数据。
2、数据一致性:确保不同表之间的数据关联正确。
3、减少冗余:避免数据重复,提高存储效率。
4、查询效率:通过自动索引提升查询性能。
5、减少错误:自动验证数据,减少程序错误。
6、提高安全性:防止非法数据的插入,保护数据安全。
7、简化维护:确保数据规范,简化数据管理。
8、支持可扩展性:保证数据质量,适应数据量增长。
9、提升设计质量:明确字段规则,确保数据库设计准确。
约束案例数据准备:
-- 部门表 (departments)
CREATE TABLE departments (
dept_id INT AUTO_INCREMENT PRIMARY KEY COMMENT '部门ID,主键',
dept_name VARCHAR(50) NOT NULL UNIQUE COMMENT '部门名称,非空且唯一',
location VARCHAR(100) DEFAULT '总部' COMMENT '部门位置,默认值',
budget DECIMAL(12,2) COMMENT '部门预算'
) COMMENT '部门信息表';
-- 员工表 (employee)
CREATE TABLE employee (
emp_id INT AUTO_INCREMENT PRIMARY KEY COMMENT '员工ID,主键',
emp_name VARCHAR(50) NOT NULL COMMENT '员工姓名,非空',
emp_age INT COMMENT '员工年龄',
gender CHAR(1) DEFAULT 'M' COMMENT '性别(M男/F女/O其他)',
salary DECIMAL(10,2) COMMENT '薪资',
hire_date DATE NOT NULL COMMENT '入职日期,非空',
dept_id INT COMMENT '所属部门ID,外键',
-- 外键约束
CONSTRAINT fk_dept FOREIGN KEY (dept_id) REFERENCES departments(dept_id),
-- 唯一约束(工号+姓名组合唯一)
CONSTRAINT uk_emp_code_name UNIQUE (emp_id, emp_name)
) COMMENT '员工信息表';查看表中的所有约束
-- 查看表的所有约束
SELECT CONSTRAINT_NAME, CONSTRAINT_TYPE
FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS
WHERE TABLE_NAME = 'employee';1、主键约束 (PRIMARY KEY)
主键分为单字段主键和多字段联合主键
主键应注意以下几点:
- 每个表只能定义一个主键。
- 主键值必须唯一标识表中的每一行,且不能为 NULL,即表中不可能存在有相同主键值的两行数据。这是唯一性原则。
- 一个字段名只能在联合主键字段表中出现一次。
- 联合主键不能包含不必要的多余字段。当把联合主键的某一字段删除后,如果剩下的字段构成的主键仍然满足唯一性原则,那么这个联合主键是不正确的。这是最小化原则。
-- 建表时创建
CREATE TABLE table1 (
id INT PRIMARY KEY
);
-- 建表后添加
ALTER TABLE employee ADD PRIMARY KEY (emp_id);ALTER TABLE employee DROP PRIMARY KEY;2、外键约束 (FOREIGN KEY)
MYSQL 外键约束(FOREIGN KEY)是表的一个特殊字段,经常与主键约束一起使用。对于两个具有关联关系的表而言,相关联字段中主键所在的表就是主表(父表),外键所在的表就是从表(子表)。
主表删除某条记录时,从表中与之对应的记录也必须有相应的改变。一个表可以有一个或多个外键,外键可以为空值,若不为空值,则每一个外键的值必须等于主表中主键的某个值。
-- 建表时创建
CREATE TABLE table1 (
dept_id INT,
FOREIGN KEY (dept_id) REFERENCES departments(dept_id)
);
-- 建表后添加
ALTER TABLE employee
ADD CONSTRAINT fk_dept
FOREIGN KEY (dept_id) REFERENCES departments(dept_id);ALTER TABLE employee DROP FOREIGN KEY fk_dept;3、唯一约束 (UNIQUE)
唯一约束(Unique Key)是指所有记录中字段的值不能重复出现。
-- 建表时创建
CREATE TABLE table1 (
email VARCHAR(100) UNIQUE
);
-- 建表后添加
ALTER TABLE employee ADD CONSTRAINT uk_emp_name UNIQUE (emp_name);ALTER TABLE employee DROP INDEX uk_emp_name;4、检查约束 (CHECK) - MySQL 8.0.16+
检查约束(CHECK)是用来检查数据表中字段值有效性的一种手段,可以通过 CREATE TABLE 或 ALTER TABLE 语句实现。设置检查约束时要根据实际情况进行设置,这样能够减少无效数据的输入。
-- 建表时创建
CREATE TABLE table1 (
age INT CHECK (age >= 18)
);
-- 建表后添加
ALTER TABLE employee
ADD CONSTRAINT chk_age CHECK (emp_age >= 18);ALTER TABLE employee DROP CHECK chk_age;5、非空约束 (NOT NULL)
非空约束(NOT NULL)指字段的值不能为空。对于使用了非空约束的字段,如果用户在添加数据时没有指定值,数据库系统就会报错。可以通过 CREATE TABLE 或 ALTER TABLE 语句实现。在表中某个列的定义后加上关键字 NOT NULL 作为限定词,来约束该列的取值不能为空。
-- 建表时创建
CREATE TABLE table1 (
name VARCHAR(50) NOT NULL
);
-- 建表后添加
ALTER TABLE employee MODIFY COLUMN emp_name VARCHAR(50) NOT NULL;
ALTER TABLE employee CHANGE COLUMN emp_name emp_name VARCHAR(50) NOT NULL;ALTER TABLE employee MODIFY COLUMN emp_name VARCHAR(50) NULL;
ALTER TABLE employee CHANGE COLUMN emp_name emp_name VARCHAR(50) NULL;6、默认值约束 (DEFAULT)
默认值(Default)的完整称呼是“默认值约束(Default Constraint)”,用来指定某列的默认值。在表中插入一条新记录时,如果没有为某个字段赋值,系统就会自动为这个字段插入默认值。
-- 建表时创建
CREATE TABLE table1 (
status INT DEFAULT 0
);
-- 建表后添加
ALTER TABLE employee
ALTER COLUMN gender SET DEFAULT 'M';ALTER TABLE employee
ALTER COLUMN gender DROP DEFAULT;7、数据定义语言-DDL
数据定义语言(DDL)来创建或删除数据库以及表等对象,主要包含以下几种命令:
CREATE:创建数据库和表等对象
ALTER:修改数据库和表等对象的结构
DROP:删除数据库和表等对象
1、创建数据表
数据表的创建:
-- 创建学生表
CREATE TABLE student (
s_id INT PRIMARY KEY COMMENT '学生ID,主键',
s_name VARCHAR(50) NOT NULL COMMENT '学生姓名',
s_age INT COMMENT '学生年龄',
s_sex CHAR(2) COMMENT '学生性别',
s_phone VARCHAR(20) COMMENT '学生电话'
) COMMENT '学生信息表';
-- 创建教师表
CREATE TABLE teacher (
t_id INT PRIMARY KEY COMMENT '教师ID,主键',
t_name VARCHAR(50) NOT NULL COMMENT '教师姓名',
t_age INT COMMENT '教师年龄',
t_sex CHAR(2) COMMENT '教师性别',
t_phone VARCHAR(20) COMMENT '教师电话'
) COMMENT '教师信息表';
-- 创建课程表
CREATE TABLE course (
c_id INT PRIMARY KEY COMMENT '课程ID,主键',
t_id INT COMMENT '授课教师ID,外键',
c_name VARCHAR(100) NOT NULL COMMENT '课程名称',
FOREIGN KEY (t_id) REFERENCES teacher(t_id)
) COMMENT '课程信息表';
-- 创建学生选课表(SC)
CREATE TABLE SC (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '选课记录ID,主键',
s_id INT COMMENT '学生ID,外键',
c_id INT COMMENT '课程ID,外键',
score DECIMAL(5,2) COMMENT '考试成绩',
FOREIGN KEY (s_id) REFERENCES student(s_id),
FOREIGN KEY (c_id) REFERENCES course(c_id)
) COMMENT '学生选课及成绩表';2、修改数据库表
-- 1. 创建初始测试表
CREATE TABLE employee (
emp_id INT PRIMARY KEY AUTO_INCREMENT,
emp_name VARCHAR(50) NOT NULL,
emp_age INT,
emp_gender CHAR(1) DEFAULT 'M',
hire_date DATE,
salary DECIMAL(10,2),
department VARCHAR(30)
) COMMENT '员工信息表';
-- 2. 添加新列
ALTER TABLE employee ADD COLUMN email VARCHAR(100) COMMENT '员工邮箱';
-- 3. 修改列名和列类型
ALTER TABLE employee CHANGE COLUMN emp_gender gender CHAR(1) DEFAULT 'U' COMMENT '性别(M/F/U)';
-- 4. 修改列类型
ALTER TABLE employee MODIFY COLUMN department VARCHAR(50);
-- 5. 设置默认值
ALTER TABLE employee ALTER COLUMN salary SET DEFAULT 0.00;
-- 6. 删除默认值
ALTER TABLE employee ALTER COLUMN salary DROP DEFAULT;
-- 7. 删除列
ALTER TABLE employee DROP COLUMN email;
-- 8. 重命名表
ALTER TABLE employee RENAME TO staff;
-- 9. 修改字符集和校对规则(MySQL示例)
ALTER TABLE staff CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
-- 10. 添加多列
ALTER TABLE staff
ADD COLUMN phone VARCHAR(20) COMMENT '联系电话',
ADD COLUMN address VARCHAR(200) COMMENT '家庭住址';
-- 11. 添加约束 mysql8.0.16以上生效
ALTER TABLE staff ADD CONSTRAINT chk_age CHECK (emp_age >= 18);
-- 12. 删除约束(MySQL示例) mysql8.0.16以上生效
ALTER TABLE staff DROP CHECK chk_age;
-- 13. 添加外键(假设有部门表)
-- 先创建部门表
CREATE TABLE department (
dept_id INT PRIMARY KEY,
dept_name VARCHAR(50) NOT NULL
);
-- 然后添加外键
ALTER TABLE staff
ADD COLUMN dept_id INT,
ADD CONSTRAINT fk_dept FOREIGN KEY (dept_id) REFERENCES department(dept_id);
-- 14. 删除外键
ALTER TABLE staff DROP FOREIGN KEY fk_dept;
-- 15. 修改表注释
ALTER TABLE staff COMMENT '公司员工信息表';
3、删除数据库表
-- 删除 staff 表
DROP TABLE IF EXISTS staff;
-- 删除 department 表
DROP TABLE IF EXISTS department;
-- 同时删除 staff 和 department 表
DROP TABLE IF EXISTS staff, department;4、查看表结构
-- 创建初始测试表
CREATE TABLE employee (
emp_id INT PRIMARY KEY AUTO_INCREMENT,
emp_name VARCHAR(50) NOT NULL,
emp_age INT,
emp_gender CHAR(1) DEFAULT 'M',
hire_date DATE,
salary DECIMAL(10,2),
department VARCHAR(30)
) COMMENT '员工信息表';
-- 查看表结构
DESCRIBE employee;
-- 或简写
DESC employee;
SHOW COLUMNS FROM employee;
-- 查看完整建表语句
SHOW CREATE TABLE employee;
-- 查询 information_schema 数据库(最全面)
SELECT
COLUMN_NAME AS '列名',
COLUMN_TYPE AS '数据类型',
IS_NULLABLE AS '允许空',
COLUMN_DEFAULT AS '默认值',
COLUMN_COMMENT AS '注释'
FROM
information_schema.COLUMNS
WHERE
TABLE_SCHEMA = 'sql_case_new'
AND TABLE_NAME = 'employee';
-- 查看表状态信息
SHOW TABLE STATUS LIKE 'employee';
-- 查看索引信息
SHOW INDEX FROM employee;8、Mysql运算符
算术运算符
+:加法
-:减法
*:乘法
/:除法
%:求余(模运算)
比较运算符
| 运算符 | 描述 |
| = | 等于 |
| <> 或 != | 不等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
逻辑运算符
AND:与
OR:或
NOT:非
位运算符
&:按位与
|:按位或
^:按位异或
~:按位取反
<<:左移
>>:右移
9、Mysql的函数
MySQL 数值型函数
| 函数名称 | 作 用 |
| 求绝对值 | |
| 求二次方根 | |
| 求余数 | |
| 两个函数功能相同,都是返回不小于参数的最小整数,即向上取整 | |
| 向下取整,返回值转化为一个BIGINT | |
| 生成一个0~1之间的随机数,传入整数参数是,用来产生重复序列 | |
| 对所传参数进行四舍五入 | |
| 返回参数的符号 | |
| 两个函数的功能相同,都是所传参数的次方的结果值 | |
| 求正弦值 | |
| 求反正弦值,与函数 SIN 互为反函数 | |
| 求余弦值 | |
| 求反余弦值,与函数 COS 互为反函数 | |
| 求正切值 | |
| 求反正切值,与函数 TAN 互为反函数 | |
| 求余切值 |
-- 创建数值测试表
CREATE TABLE math_values (
id INT PRIMARY KEY AUTO_INCREMENT,
value1 DECIMAL(10,2),
value2 DECIMAL(10,2),
angle DECIMAL(10,6) COMMENT '角度值,单位度'
);
-- 插入测试数据
INSERT INTO math_values (value1, value2, angle) VALUES
(15.75, -4.32, 30.0),
(-8.95, 3.14, 45.0),
(12.50, 7.89, 60.0),
(9.99, -2.45, 90.0),
(0.00, 5.67, 180.0);
-- ABS - 绝对值
SELECT
value1,
ABS(value1) AS absolute_value
FROM math_values;
-- SQRT - 平方根
SELECT
value1,
SQRT(ABS(value1)) AS square_root
FROM math_values
WHERE value1 >= 0; -- 负数平方根返回NULL
-- MOD - 取余数
SELECT
value1,
value2,
MOD(value1, value2) AS remainder
FROM math_values
WHERE value2 != 0; -- 避免除以零错误
-- CEIL/CEILING - 向上取整
SELECT
value1,
CEIL(value1) AS ceiling_value,
CEILING(value1) AS ceiling_value2
FROM math_values;
-- FLOOR - 向下取整
SELECT
value1,
FLOOR(value1) AS floor_value
FROM math_values;
-- RAND - 随机数
-- 生成0-1随机数
SELECT RAND() AS random1;
-- 生成1-100随机整数 FLOOR 函数 向下取整
SELECT FLOOR(1 + RAND() * 100) AS random_int;
-- 使用种子生成可重复随机序列
SELECT RAND(42) AS seeded_random1, RAND(42) AS seeded_random2;
-- ROUND - 四舍五入
SELECT
value1,
ROUND(value1) AS rounded_default,
ROUND(value1, 1) AS rounded_1decimal
FROM math_values;
-- SIGN - 符号函数
SELECT
value1,
SIGN(value1) AS sign_value -- 返回1(正), 0(零), -1(负)
FROM math_values;
-- POW/POWER - 幂运算
SELECT
value1,
value2,
POW(value1, 2) AS squared,
CASE
WHEN value1 = 0 AND value2 <= 0 THEN NULL -- 处理0的0次方或负次方
WHEN ABS(value1) > 1 AND value2 > LOG(1.7976931348623157e+308)/LOG(ABS(value1)) THEN 1.7976931348623157e+308
WHEN ABS(value1) > 1 AND value2 < -LOG(1.7976931348623157e+308)/LOG(ABS(value1)) THEN 0
WHEN value1 < 0 AND value2 <> FLOOR(value2) THEN NULL -- 负数的小数次方
ELSE POWER(value1, value2)
END AS power_result
FROM math_values;
-- 三角函数
-- SIN - 正弦
SELECT
angle,
SIN(RADIANS(angle)) AS sine_value -- 需先将角度转为弧度
FROM math_values;
-- ASIN - 反正弦
SELECT
value1,
ASIN(value1/100) AS arc_sine -- 参数需在-1到1之间
FROM math_values
WHERE ABS(value1/100) <= 1;
-- COS - 余弦
SELECT
angle,
COS(RADIANS(angle)) AS cosine_value
FROM math_values;
-- ACOS - 反余弦
SELECT
value1,
ACOS(value1/100) AS arc_cosine
FROM math_values
WHERE ABS(value1/100) <= 1;
-- TAN - 正切
SELECT
angle,
TAN(RADIANS(angle)) AS tangent_value
FROM math_values;
-- ATAN - 反正切
SELECT
value1,
ATAN(value1) AS arc_tangent
FROM math_values;
-- COT - 余切
SELECT
angle,
COT(RADIANS(angle)) AS cotangent_value
FROM math_values
WHERE angle % 180 != 0; -- 避免tan(90°)无定义的情况
MySQL 字符串函数
常见的字符串函数分类:
1、大小写转换函数:
UPPER(str):将字符串转换为大写。
LOWER(str):将字符串转换为小写。
2、字符处理函数:
CONCAT(str1, str2, ...):连接多个字符串。
LENGTH(str):返回字符串的字节长度。
SUBSTRING(str, start, length):提取子字符串。
TRIM(str):删除字符串两端的空格。
REPLACE(str, old, new):替换字符串中的指定内容。
| 函数名称 | 作 用 |
| 计算字符串长度函数,返回字符串的字节长度 | |
| 合并字符串函数,返回结果为连接参数产生的字符串,参数可以使一个或多个 | |
| 替换字符串函数 | |
| 将字符串中的字母转换为小写 | |
| 将字符串中的字母转换为大写 | |
| 从左侧字截取符串,返回字符串左边的若干个字符 | |
| 从右侧字截取符串,返回字符串右边的若干个字符 | |
| 删除字符串左右两侧的空格 | |
| 字符串替换函数,返回替换后的新字符串 | |
| 截取字符串,返回从指定位置开始的指定长度的字符换 | |
| 字符串反转(逆序)函数,返回与原始字符串顺序相反的字符串 |
-- 字符串函数案例
-- 创建用户信息表
CREATE TABLE users (
user_id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50) NOT NULL,
email VARCHAR(100),
phone VARCHAR(20),
address VARCHAR(200),
notes TEXT
);
-- 插入测试数据
INSERT INTO users (username, email, phone, address, notes) VALUES
('JohnDoe', 'JOHN.doe@example.com', '13800138000', ' 123 Main St, New York ', 'Preferred contact by email'),
('Alice_Smith', 'alice.smith@test.org', '13912345678', '456 Oak Ave, Boston', 'VIP customer'),
('BobJohnson', 'bob.johnson@demo.net', '13755556666', ' 789 Pine Rd, Chicago ', 'Needs follow-up'),
('mary_wilson', 'Mary.Wilson@sample.com', '13600001111', '321 Elm Blvd, Los Angeles', ''),
('TEST_USER', 'test_user@fake.org', '13512349876', '159 Maple Dr, Seattle ', 'Temporary account');
-- LENGTH - 计算字符串字节长度
-- 计算用户名的字节长度
SELECT
username,
LENGTH(username) AS name_length
FROM users;
-- 查找用户名超过10字节的用户
SELECT username FROM users WHERE LENGTH(username) > 10;
-- CONCAT - 合并字符串
-- 创建用户全联系信息
SELECT
user_id,
CONCAT(username, ' (', email, ') - ', phone) AS contact_info
FROM users;
-- 带分隔符合并地址信息 TRIM() 函数用于去除字符串两端的空格或指定字符
UPDATE users
SET address = CONCAT(TRIM(address), ', USA');
-- INSERT - 替换字符串
-- 隐藏手机号中间四位
SELECT
username,
phone,
INSERT(phone, 4, 4, '****') AS masked_phone
FROM users;
-- 格式化日期字符串 (从YYYYMMDD到YYYY-MM-DD)
SELECT INSERT(INSERT('20230815', 5, 0, '-'), 8, 0, '-') AS formatted_date;
-- LOWER/UPPER - 大小写转换
-- 查询邮箱转换为小写
SELECT username, LOWER(email) AS email FROM users;
-- 用户名转换为大写
SELECT username, UPPER(username) AS uppercase_name FROM users;
UPDATE users SET email = LOWER(email);
-- LEFT/RIGHT - 截取字符串
-- 获取用户名的前3个字符作为缩写
SELECT
username,
LEFT(username, 3) AS name_abbr
FROM users;
-- 提取手机号后4位
SELECT
phone,
RIGHT(phone, 4) AS last_four_digits
FROM users;
-- 创建用户名+手机尾号的临时密码
SELECT
username,
CONCAT(LEFT(username, 3), RIGHT(phone, 4)) AS temp_password
FROM users;
-- TRIM - 去除空格
-- 查找地址中有前导/尾随空格的记录(清理前)
SELECT * FROM users WHERE address LIKE ' %' OR address LIKE '% ';
-- 带备注的用户信息(去除备注两侧空格)
SELECT
user_id,
username,
TRIM(notes) AS clean_notes
FROM users;
-- REPLACE - 字符串替换
-- 替换邮箱域名
SELECT
email,
REPLACE(email, '@example.com', '@company.com') AS new_email
FROM users;
-- SUBSTRING - 截取子串
-- 提取邮箱用户名部分(@之前的部分) LOCATE 函数是 MySQL 中用于查找子字符串在源字符串中首次出现位置的函数
SELECT
email,
SUBSTRING(email, 1, LOCATE('@', email) - 1) AS email_name
FROM users;
-- 获取地址中的城市名(最后一个逗号后的内容)
SELECT
address,
SUBSTRING(address, LOCATE(',', address) + 2) AS city
FROM users;
-- REVERSE - 字符串反转
-- 检查回文用户名
SELECT
username,
REVERSE(username) AS reversed_name,
CASE
WHEN username = REVERSE(username) THEN 'Yes'
ELSE 'No'
END AS is_palindrome
FROM users;
-- 创建简单的加密字符串
SELECT
username,
REVERSE(CONCAT(username, user_id)) AS encrypted_code
FROM users;
MySQL 日期和时间函数
| 函数名称 | 作 用 |
| DATE_FORMAT | 格式化指定的日期,根据参数返回指定格式的值 |
| STR_TO_DATE | 将字符串转换为日期 |
| CURDATE 和 CURRENT_DATE | 两个函数作用相同,返回当前系统的日期值 |
| CURTIME 和 CURRENT_TIME | 两个函数作用相同,返回当前系统的时间值 |
| NOW 和 SYSDATE | 两个函数作用相同,返回当前系统的日期和时间值 |
| UNIX_TIMESTAMP | 获取UNIX时间戳函数,返回一个以 UNIX 时间戳为基础的无符号整数 |
| FROM_UNIXTIME | 将 UNIX 时间戳转换为时间格式,与UNIX_TIMESTAMP互为反函数 |
| MONTH | 获取指定日期中的月份 |
| MONTHNAME | 获取指定日期中的月份英文名称 |
| DAYNAME | 获取指定曰期对应的星期几的英文名称 |
| DAYOFWEEK | 获取指定日期对应的一周的索引位置值 |
| WEEK | 获取指定日期是一年中的第几周,返回值的范围是否为 0〜52 或 1〜53 |
| DAYOFYEAR | 获取指定曰期是一年中的第几天,返回值范围是1~366 |
| DAYOFMONTH | 获取指定日期是一个月中是第几天,返回值范围是1~31 |
| YEAR | 获取年份,返回值范围是 1970〜2069 |
| TIME_TO_SEC | 将时间参数转换为秒数 |
| SEC_TO_TIME | 将秒数转换为时间,与TIME_TO_SEC 互为反函数 |
| DATE_ADD 和 ADDDATE | 两个函数功能相同,都是向日期添加指定的时间间隔 |
| DATE_SUB 和 SUBDATE | 两个函数功能相同,都是向日期减去指定的时间间隔 |
| ADDTIME | 时间加法运算,在原始时间上添加指定的时间 |
| SUBTIME | 时间减法运算,在原始时间上减去指定的时间 |
| DATEDIFF | 获取两个日期之间间隔,返回参数 1 减去参数 2 的值 |
| WEEKDAY | 获取指定日期在一周内的对应的工作日索引 |
-- 日期函数
-- 创建订单表
CREATE TABLE orders (
order_id INT PRIMARY KEY AUTO_INCREMENT,
customer_name VARCHAR(50),
order_date DATETIME,
delivery_date DATE,
process_time TIME,
timestamp_column TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 插入测试数据
INSERT INTO orders (customer_name, order_date, delivery_date, process_time) VALUES
('张三', '2023-05-15 10:30:00', '2023-05-20', '00:45:30'),
('李四', '2023-06-22 14:15:00', '2023-06-25', '01:20:15'),
('王五', '2023-07-10 09:05:00', '2023-07-15', '00:30:45'),
('赵六', '2023-08-03 16:40:00', '2023-08-10', '02:15:00'),
('钱七', NOW(), DATE_ADD(CURDATE(), INTERVAL 7 DAY), '00:55:20');
-- DATE_FORMAT - 日期格式化
-- 格式化订单日期为"年-月-日 时:分"格式
SELECT
order_id,
DATE_FORMAT(order_date, '%Y-%m-%d %H:%i') AS formatted_date
FROM orders;
-- 显示带星期几的日期
SELECT
customer_name,
DATE_FORMAT(order_date, '%W, %M %d %Y') AS order_day
FROM orders;
-- STR_TO_DATE - 字符串转日期
-- 将字符串转换为日期
SELECT
STR_TO_DATE('2023-12-25', '%Y-%m-%d') AS christmas,
STR_TO_DATE('25,12,2023', '%d,%m,%Y') AS christmas_europe;
-- CURDATE/CURRENT_DATE - 当前日期
-- 查询今天下的订单
SELECT
*,
CURRENT_DATE () AS 当前日期
FROM
orders
WHERE
DATE ( order_date ) = CURRENT_DATE ();
-- NOW/SYSDATE - 当前日期时间
-- 记录操作时间
UPDATE orders SET timestamp_column = NOW()
WHERE order_id = 1;
-- UNIX_TIMESTAMP - 获取时间戳
-- 获取订单时间戳
SELECT
order_id,
UNIX_TIMESTAMP(order_date) AS order_timestamp
FROM orders;
-- FROM_UNIXTIME - 时间戳转日期
-- 时间戳转可读日期
SELECT
FROM_UNIXTIME(1672502400) AS normal_date,
FROM_UNIXTIME(1672502400, '%Y-%m-%d') AS formatted_date;
-- MONTH/MONTHNAME - 月份
-- 按月统计订单
SELECT
MONTH(order_date) AS month_num,
MONTHNAME(order_date) AS month_name,
COUNT(*) AS order_count
FROM orders
GROUP BY month_num, month_name;
-- DAYNAME/DAYOFWEEK - 星期
-- 查询星期几的订单分布
SELECT
DAYNAME(order_date) AS weekday,
COUNT(*) AS order_count
FROM orders
GROUP BY weekday;
-- YEAR/QUARTER - 年和季度
-- 按年和季度分析
SELECT
YEAR(order_date) AS year,
QUARTER(order_date) AS quarter
FROM orders
GROUP BY year, quarter;
-- DATE_ADD/ADDDATE - 日期加法
-- 计算预计送达日期(3个工作日后)
SELECT
order_id,
order_date,
DATE_ADD(order_date, INTERVAL 3 DAY) AS estimated_delivery
FROM orders;
-- DATE_SUB/SUBDATE - 日期减法
-- 查询30天前的订单
SELECT * FROM orders
WHERE order_date >= DATE_SUB(CURDATE(), INTERVAL 30 DAY);
-- DATEDIFF - 日期差
-- 计算订单处理时长
SELECT
order_id,
DATEDIFF(delivery_date, DATE(order_date)) AS days_to_deliver
FROM orders;
-- TIME_TO_SEC - 时间差
-- 计算处理时间的秒数
SELECT
order_id,
process_time,
TIME_TO_SEC(process_time) AS process_seconds
FROM orders;
MySQL 聚合函数
| 函数名称 | 作用 |
| MAX | 查询指定列的最大值 |
| MIN | 查询指定列的最小值 |
| COUNT | 统计查询结果的行数 |
| SUM | 求和,返回指定列的总和 |
| AVG | 求平均值,返回指定列数据的平均值 |
-- 创建销售数据表
CREATE TABLE sales (
sale_id INT PRIMARY KEY AUTO_INCREMENT,
product_name VARCHAR(50) NOT NULL,
category VARCHAR(30),
sale_date DATE,
quantity INT,
unit_price DECIMAL(10,2),
region VARCHAR(30)
);
-- 插入测试数据
INSERT INTO sales (product_name, category, sale_date, quantity, unit_price, region) VALUES
('笔记本电脑', '电子产品', '2023-01-15', 5, 5999.00, '华东'),
('智能手机', '电子产品', '2023-01-18', 8, 3999.00, '华北'),
('智能手表', '电子产品', '2023-02-02', 12, 1299.00, '华南'),
('办公椅', '家具', '2023-02-10', 3, 899.00, '华东'),
('书桌', '家具', '2023-03-05', 2, 1599.00, '华北'),
('台灯', '家居用品', '2023-03-12', 10, 199.00, '华南'),
('笔记本电脑', '电子产品', '2023-03-20', 4, 6299.00, '华东'),
('鼠标', '电子产品', '2023-04-08', 20, 99.00, '华北');
-- MAX - 查询最大值
-- 查询最高单价产品
SELECT MAX(unit_price) AS max_price FROM sales;
-- 查询每个类别的最高单价
SELECT
category,
MAX(unit_price) AS max_price
FROM sales
GROUP BY category;
-- 查询最高单价产品的详细信息
SELECT * FROM sales
WHERE unit_price = (SELECT MAX(unit_price) FROM sales);
-- MIN - 查询最小值
-- 查询最低单价
SELECT MIN(unit_price) AS min_price FROM sales;
-- 查询每个区域的最低销售额(单价*数量)
SELECT
region,
MIN(unit_price * quantity) AS min_sales_amount
FROM sales
GROUP BY region;
-- 查询销量最低的产品信息
SELECT * FROM sales
WHERE quantity = (SELECT MIN(quantity) FROM sales);
-- COUNT - 统计行数
-- 统计总销售记录数
SELECT COUNT(*) AS total_sales FROM sales;
-- 统计有销售记录的类别数量
SELECT COUNT(DISTINCT category) AS category_count FROM sales;
-- 统计每个区域的销售记录数
SELECT
region,
COUNT(*) AS sales_count
FROM sales
GROUP BY region;
-- 统计单价超过1000的产品数量
SELECT COUNT(*) AS premium_products
FROM sales
WHERE unit_price > 1000;
-- SUM - 求和
-- 计算总销售额
SELECT SUM(unit_price * quantity) AS total_revenue FROM sales;
-- 计算每个产品的总销售额
SELECT
product_name,
SUM(unit_price * quantity) AS product_revenue
FROM sales
GROUP BY product_name
ORDER BY product_revenue DESC;
-- 计算第一季度(1-3月)的销售额
SELECT SUM(unit_price * quantity) AS q1_revenue
FROM sales
WHERE sale_date BETWEEN '2023-01-01' AND '2023-03-31';
-- AVG - 求平均值
-- 计算平均单价
SELECT AVG(unit_price) AS avg_price FROM sales;
-- 计算每个类别的平均销量
SELECT
category,
AVG(quantity) AS avg_quantity
FROM sales
GROUP BY category;
-- 计算各区域的平均订单金额
SELECT
region,
AVG(unit_price * quantity) AS avg_order_amount
FROM sales
GROUP BY region;
MySQL 流程控制函数
| 函数名称 | 作用 |
| IF | 判断,流程控制 |
| IFNULL | 判断是否为空 |
| CASE | 搜索语句 |
-- MySQL 流程控制函数
-- 创建学生成绩表
CREATE TABLE student_grades (
student_id INT PRIMARY KEY COMMENT '学生ID,主键',
student_name VARCHAR(50) NOT NULL COMMENT '学生姓名,非空',
math_score INT COMMENT '数学成绩,0-100分',
english_score INT COMMENT '英语成绩,0-100分',
science_score INT COMMENT '科学成绩,0-100分',
history_score INT COMMENT '历史成绩,0-100分',
art_score INT COMMENT '艺术成绩,0-100分',
has_scholarship BOOLEAN DEFAULT FALSE COMMENT '是否获得奖学金,默认FALSE',
attendance_rate DECIMAL(5,2) COMMENT '出勤率,百分比值(0.00-100.00)'
) COMMENT '学生成绩信息表,记录各科成绩和出勤情况';
-- 插入测试数据
INSERT INTO student_grades VALUES
(101, '张三', 85, 92, 78, 88, 90, TRUE, 95.50),
(102, '李四', 92, 89, 95, 76, 82, FALSE, 89.25),
(103, '王五', 78, 85, 80, 92, 75, TRUE, 92.75),
(104, '赵六', 65, 72, 68, 70, 80, FALSE, 85.00),
(105, '钱七', 88, 93, 91, 85, 94, TRUE, 97.25),
(106, '孙八', NULL, 78, 85, 80, 72, FALSE, 78.50),
(107, '周九', 72, 65, 70, 68, 75, FALSE, 81.25),
(108, '吴十', 95, 98, 92, 96, 90, TRUE, 99.00);
-- 基础IF判断
-- 判断数学成绩是否及格
SELECT
student_name,
math_score,
IF(math_score >= 60, '及格', '不及格') AS math_result
FROM student_grades;
--
-- 判断学生是否有资格参加数学竞赛(数学成绩>85且出勤率>90%)
SELECT
student_name,
math_score,
attendance_rate,
IF(math_score > 85 AND attendance_rate > 90, '符合资格', '不符合资格') AS competition_eligibility
FROM student_grades;
-- 处理NULL值
-- 处理缺失的数学成绩(显示为"未考试"而不是NULL)
SELECT
student_name,
IFNULL(math_score, '未考试') AS math_score_display
FROM student_grades;
-- 计算学生平均分(忽略NULL科目)
SELECT
student_name,
(IFNULL(math_score, 0) + IFNULL(english_score, 0) +
IFNULL(science_score, 0) + IFNULL(history_score, 0) +
IFNULL(art_score, 0)) /
((math_score IS NOT NULL) + (english_score IS NOT NULL) +
(science_score IS NOT NULL) + (history_score IS NOT NULL) +
(art_score IS NOT NULL)) AS average_score
FROM student_grades;
-- 简单CASE表达式
-- 根据分数范围评定等级
SELECT
student_name,
math_score,
CASE
WHEN math_score >= 90 THEN 'A'
WHEN math_score >= 80 THEN 'B'
WHEN math_score >= 70 THEN 'C'
WHEN math_score >= 60 THEN 'D'
WHEN math_score IS NULL THEN '未考试'
ELSE 'F'
END AS math_grade
FROM student_grades;
-- -- 综合评估学生整体表现
SELECT
student_id,
student_name,
CASE
WHEN has_scholarship = TRUE AND attendance_rate > 95 THEN '优秀学生'
WHEN (math_score + english_score + science_score)/3 > 85 THEN '学术优异'
WHEN (art_score + history_score)/2 > 85 THEN '文科特长'
WHEN attendance_rate < 80 THEN '需要关注出勤'
ELSE '普通学生'
END AS student_category
FROM student_grades;
-- 判断各科目是否达标
SELECT
student_name,
CASE WHEN math_score >= 75 THEN '达标' ELSE '未达标' END AS math_status,
CASE WHEN english_score >= 75 THEN '达标' ELSE '未达标' END AS english_status,
CASE WHEN science_score >= 75 THEN '达标' ELSE '未达标' END AS science_status,
CASE
WHEN math_score >= 75 AND english_score >= 75 AND science_score >= 75
THEN '全部达标'
ELSE '部分未达标'
END AS overall_status
FROM student_grades;
-- 学生成绩报告单
SELECT
student_name,
IFNULL(math_score, 0) AS math,
IFNULL(english_score, 0) AS english,
IFNULL(science_score, 0) AS science,
IFNULL(history_score, 0) AS history,
IFNULL(art_score, 0) AS art,
attendance_rate,
CASE
WHEN has_scholarship THEN '是'
ELSE '否'
END AS scholarship_status,
CASE
WHEN (IFNULL(math_score, 0) + IFNULL(english_score, 0) +
IFNULL(science_score, 0) + IFNULL(history_score, 0) +
IFNULL(art_score, 0)) /
((math_score IS NOT NULL) + (english_score IS NOT NULL) +
(science_score IS NOT NULL) + (history_score IS NOT NULL) +
(art_score IS NOT NULL)) >= 90 THEN '优秀'
WHEN (IFNULL(math_score, 0) + IFNULL(english_score, 0) +
IFNULL(science_score, 0) + IFNULL(history_score, 0) +
IFNULL(art_score, 0)) /
((math_score IS NOT NULL) + (english_score IS NOT NULL) +
(science_score IS NOT NULL) + (history_score IS NOT NULL) +
(art_score IS NOT NULL)) >= 80 THEN '良好'
WHEN (IFNULL(math_score, 0) + IFNULL(english_score, 0) +
IFNULL(science_score, 0) + IFNULL(history_score, 0) +
IFNULL(art_score, 0)) /
((math_score IS NOT NULL) + (english_score IS NOT NULL) +
(science_score IS NOT NULL) + (history_score IS NOT NULL) +
(art_score IS NOT NULL)) >= 60 THEN '及格'
ELSE '不及格'
END AS overall_grade
FROM student_grades
ORDER BY overall_grade DESC, student_name;
DROP TABLE student_grades;10、数据操作语言-DQL和DML
-- DQL+DML
-- 创建学生表
CREATE TABLE student (
s_id INT PRIMARY KEY COMMENT '学生ID,主键',
s_name VARCHAR(50) NOT NULL COMMENT '学生姓名',
s_age INT COMMENT '学生年龄',
s_sex CHAR(2) COMMENT '学生性别',
s_phone VARCHAR(20) COMMENT '学生电话'
) COMMENT '学生信息表';
-- 创建教师表
CREATE TABLE teacher (
t_id INT PRIMARY KEY COMMENT '教师ID,主键',
t_name VARCHAR(50) NOT NULL COMMENT '教师姓名',
t_age INT COMMENT '教师年龄',
t_sex CHAR(2) COMMENT '教师性别',
t_phone VARCHAR(20) COMMENT '教师电话'
) COMMENT '教师信息表';
-- 创建课程表
CREATE TABLE course (
c_id INT PRIMARY KEY COMMENT '课程ID,主键',
t_id INT COMMENT '授课教师ID,外键',
c_name VARCHAR(100) NOT NULL COMMENT '课程名称',
FOREIGN KEY (t_id) REFERENCES teacher(t_id)
) COMMENT '课程信息表';
-- 创建学生选课表(SC)
CREATE TABLE SC (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '选课记录ID,主键',
s_id INT COMMENT '学生ID,外键',
c_id INT COMMENT '课程ID,外键',
score DECIMAL(5,2) COMMENT '考试成绩',
FOREIGN KEY (s_id) REFERENCES student(s_id),
FOREIGN KEY (c_id) REFERENCES course(c_id)
) COMMENT '学生选课及成绩表';
-- 插入数据(INSERT)
-- 插入学生数据
INSERT INTO student (s_id, s_name, s_age, s_sex, s_phone) VALUES
(1, '张三', 20, '男', '13800138001'),
(2, '李四', 21, '女', '13800138002'),
(3, '王五', 19, '男', '13800138003'),
(4, '赵六', 22, '女', '13800138004'),
(5, '钱七', 20, '男', '13800138005');
-- 插入教师数据
INSERT INTO teacher (t_id, t_name, t_age, t_sex, t_phone) VALUES
(101, '张老师', 35, '男', '13900139001'),
(102, '李老师', 40, '女', '13900139002'),
(103, '王老师', 38, '男', '13900139003');
-- 插入课程数据
INSERT INTO course (c_id, t_id, c_name) VALUES
(1001, 101, '高等数学'),
(1002, 102, '大学英语'),
(1003, 103, '计算机科学'),
(1004, 101, '线性代数');
-- 插入选课数据
INSERT INTO SC (s_id, c_id, score) VALUES
(1, 1001, 85.5),
(1, 1002, 78.0),
(2, 1001, 92.0),
(2, 1003, 88.5),
(3, 1002, 76.0),
(3, 1004, 90.0),
(4, 1001, 81.0),
(4, 1002, 79.5),
(4, 1003, 85.0),
(5, 1004, 95.0);
-- 更新数据(UPDATE)
-- 更新学生信息
UPDATE student SET s_age = 21 WHERE s_id = 1;
-- 更新多个字段
UPDATE teacher SET t_age = 41, t_phone = '13900139022' WHERE t_id = 102;
-- 使用表达式更新
UPDATE SC SET score = score + 5 WHERE score < 80;
-- 删除数据(DELETE)
-- 删除特定记录
DELETE FROM student WHERE s_id = 5;
-- 删除满足条件的记录
DELETE FROM SC WHERE score < 60;
-- 清空表(谨慎使用)
-- TRUNCATE TABLE SC;
-- 数据查询语言(DQL)
-- 基础查询(SELECT)
-- 查询所有学生信息
SELECT * FROM student;
-- 查询特定列
SELECT s_id, s_name, s_age FROM student;
-- 使用别名
SELECT s_id AS 学号, s_name AS 姓名, s_age AS 年龄 FROM student;
-- 使用DISTINCT去重
SELECT DISTINCT s_age FROM student;
-- 条件查询(WHERE)
-- 简单条件查询
SELECT * FROM student WHERE s_age > 20;
-- 多条件查询(AND/OR)
SELECT * FROM student WHERE s_age > 19 AND s_sex = '女';
-- IN运算符
SELECT * FROM student WHERE s_id IN (1, 3, 5);
-- BETWEEN运算符
SELECT * FROM student WHERE s_age BETWEEN 19 AND 21;
-- LIKE模糊查询
SELECT * FROM student WHERE s_name LIKE '张%';
-- IS NULL判断
SELECT * FROM student WHERE s_phone IS NULL;
-- 排序(ORDER BY)
-- 单列排序
SELECT * FROM student ORDER BY s_age;
-- 多列排序
SELECT * FROM student ORDER BY s_age DESC, s_id ASC;
-- 结合条件查询和排序
SELECT * FROM student WHERE s_sex = '男' ORDER BY s_age;
-- 分组(GROUP BY)和聚合函数
-- 基本分组
SELECT s_sex, COUNT(*) FROM student GROUP BY s_sex;
-- 使用HAVING筛选分组
SELECT c_id, AVG(score) as avg_score
FROM SC
GROUP BY c_id
HAVING avg_score > 80;
-- 常用聚合函数
SELECT
COUNT(*) AS total_students,
MAX(s_age) AS max_age,
MIN(s_age) AS min_age,
AVG(s_age) AS avg_age
FROM student;
-- 连接查询(JOIN)
-- 内连接(INNER JOIN)
SELECT s.s_name, c.c_name, sc.score
FROM student s
INNER JOIN SC sc ON s.s_id = sc.s_id
INNER JOIN course c ON sc.c_id = c.c_id;
-- 左连接(LEFT JOIN)
SELECT s.s_name, c.c_name
FROM student s
LEFT JOIN SC sc ON s.s_id = sc.s_id
LEFT JOIN course c ON sc.c_id = c.c_id;
-- 右连接(RIGHT JOIN)
SELECT t.t_name, c.c_name
FROM teacher t
RIGHT JOIN course c ON t.t_id = c.t_id;
-- 自连接
SELECT a.s_name AS student1, b.s_name AS student2
FROM student a, student b
WHERE a.s_age = b.s_age AND a.s_id < b.s_id;
-- 子查询
-- WHERE子句中的子查询
SELECT * FROM student
WHERE s_id IN (SELECT s_id FROM SC WHERE score > 90);
-- FROM子句中的子查询
SELECT s.s_name, sub.avg_score
FROM student s
JOIN (
SELECT s_id, AVG(score) as avg_score
FROM SC
GROUP BY s_id
) sub ON s.s_id = sub.s_id;
-- SELECT子句中的子查询
SELECT
s_name,
(SELECT COUNT(*) FROM SC WHERE SC.s_id = student.s_id) AS course_count
FROM student;
-- EXISTS和IN的区别
-- 使用IN
SELECT * FROM student
WHERE s_id IN (SELECT s_id FROM SC WHERE score > 85);
-- 使用EXISTS
SELECT * FROM student s
WHERE EXISTS (SELECT 1 FROM SC WHERE SC.s_id = s.s_id AND score > 85);
-- NOT IN和NOT EXISTS
-- 查询没有选课的学生
SELECT * FROM student
WHERE s_id NOT IN (SELECT s_id FROM SC);
-- 更安全的NOT EXISTS写法(避免NULL值问题)
SELECT * FROM student s
WHERE NOT EXISTS (SELECT 1 FROM SC WHERE SC.s_id = s.s_id);
-- 联合查询(UNION)
-- 合并两个查询结果
SELECT s_name AS name FROM student
UNION
SELECT t_name AS name FROM teacher;
-- UNION ALL保留重复记录
SELECT s_name AS name FROM student WHERE s_sex = '男'
UNION ALL
SELECT t_name AS name FROM teacher WHERE t_sex = '男';
-- 分页查询(LIMIT)
-- 基本分页
SELECT * FROM student LIMIT 3 OFFSET 0; -- 第一页
SELECT * FROM student LIMIT 3 OFFSET 3; -- 第二页
-- MySQL简写
SELECT * FROM student LIMIT 0, 3; -- 第一页
SELECT * FROM student LIMIT 3, 3; -- 第二页
-- 复杂综合查询示例
-- 查询每个学生选修的课程数量及平均分
SELECT
s.s_id,
s.s_name,
COUNT(sc.c_id) AS course_count,
AVG(sc.score) AS avg_score,
MAX(sc.score) AS max_score,
MIN(sc.score) AS min_score
FROM student s
LEFT JOIN SC sc ON s.s_id = sc.s_id
GROUP BY s.s_id, s.s_name
HAVING course_count > 0
ORDER BY avg_score DESC;
-- 查询每个老师教授的课程及选修人数
SELECT
t.t_id,
t.t_name,
c.c_name,
COUNT(sc.s_id) AS student_count,
AVG(sc.score) AS avg_score
FROM teacher t
JOIN course c ON t.t_id = c.t_id
LEFT JOIN SC sc ON c.c_id = sc.c_id
GROUP BY t.t_id, t.t_name, c.c_name
ORDER BY t.t_id, student_count DESC;
-- 查询成绩高于该课程平均分的学生
SELECT
s.s_name,
c.c_name,
sc.score,
sub.avg_score
FROM SC sc
JOIN student s ON sc.s_id = s.s_id
JOIN course c ON sc.c_id = c.c_id
JOIN (
SELECT c_id, AVG(score) as avg_score
FROM SC
GROUP BY c_id
) sub ON sc.c_id = sub.c_id
WHERE sc.score > sub.avg_score
ORDER BY sc.c_id, sc.score DESC;EXISTS 和 IN 的区别详解
EXISTS 和 IN 都是 MySQL 中用于子查询的操作符,但它们在工作原理和性能上有显著差异。
EXISTS 和 IN 的区别:
1、EXISTS 用于检查子查询是否返回至少一行数据,返回布尔值(TRUE 或 FALSE)
IN 用于检查一个值是否存在于一个给定的结果集合中。
2、EXISTS 通常在子查询的返回结果集很大时性能较好,尤其是当在子查询中进行判断后,发现某个条件是符合的,则会立刻返回结果,不会继续查找所有的行。
IN 的性能在子查询返回的结果集较小,且值的比较比较简单时表现更好,但如果有大量的返回值,可能会导致性能问题。
3、使用 IN 时,如果子查询返回 NULL,可能会影响结果。比如:
SELECT * FROM table1 WHERE id IN (1, 2, NULL);在这种情况下,如果 id 列中的某个值为 NULL,可能不会返回任何结果。
EXISTS 不受 NULL 的影响,因为它只是判断子查询是否有结果行。。
IN 运算符
- 用于检查某个值是否存在于子查询返回的结果集中
- 子查询先执行,返回一个值列表
- 然后主查询检查字段是否在这个列表中
-- 查询选修了特定课程的学生
SELECT * FROM student
WHERE s_id IN (SELECT s_id FROM SC WHERE c_id = 1001);EXISTS 运算符
- 用于检查子查询是否返回任何行
- 不关心返回的具体数据,只关心是否有数据返回
- 子查询通常与主查询相关联(相关子查询)
SELECT * FROM student s
WHERE EXISTS (SELECT 1 FROM SC WHERE SC.s_id = s.s_id);使用NOT IN(不安全):
SELECT * FROM student
WHERE s_id NOT IN (SELECT s_id FROM SC);使用NOT EXISTS(推荐):
SELECT * FROM student s
WHERE NOT EXISTS (SELECT 1 FROM SC WHERE SC.s_id = s.s_id);选择建议:
- 当子查询结果集小且主查询结果集大时,使用 IN
- 当主查询结果集小且子查询结果集大时,使用 EXISTS
- 对于 NOT EXISTS 和 NOT IN,优先使用 NOT EXISTS
- 对于关联子查询,通常 EXISTS 性能更好
- 可以使用 EXPLAIN 分析查询计划,选择最优方案
使用 EXPLAIN 可以查看两种方式的执行计划差异:
EXPLAIN SELECT * FROM student WHERE s_id IN (SELECT s_id FROM SC);
EXPLAIN SELECT * FROM student s WHERE EXISTS (SELECT 1 FROM SC WHERE SC.s_id = s.s_id);

















 1367
1367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











