




 本文深入讲解Python中的内置函数,如abs(), pow(), chr(), bin()等的使用方法,同时覆盖生成器函数、装饰器、闭包、高阶函数及推导式的概念与实践案例,帮助读者提升Python编程技能。
本文深入讲解Python中的内置函数,如abs(), pow(), chr(), bin()等的使用方法,同时覆盖生成器函数、装饰器、闭包、高阶函数及推导式的概念与实践案例,帮助读者提升Python编程技能。
1.内置函数
A:abs()、aiter()、all()、any()、anext()、ascii()
B:bin()、bool()、breakpoint()、bytearray()、bytes()
C:callable()、chr()、classmethod()、compile()、complex()
D:delattr()、dict()、dir()、divmod()
E:enumerate()、eval()、exec()
F:filter()、float()、format()、frozenset()
G:getattr()、globals()
H:hasattr()、hash()、help()、hex()
I:id()、input()、int()、isinstance()、issubclass()、iter()
L:len()、list()、locals()
M:map()、max()、memoryview()、min()
N:next()
O:object()、oct()、open()、ord()
P:pow()、print()、property()
R:range()、repr()、reversed()、round()
S:set()、setattr()、slice()、sorted()、staticmethod()、str()、sum()、super()
T:tuple()、type()
V:vars()
Z:zip()
_ :_ _ import _ _()
*第一组
abs绝对值
v1=abs(-10)
print(v1) #10
pow次方
v1=pow(2,5)
print(v1) #2的5次方
v2=2**5
sum求和
data=[11,22,33]
res=sum(data)
print(res)
divmod两个数字相除得到商和余数
divmod(98,10) #得到元组(9,8)
v1,v2=divmod(98,10) #v1=9 v2=8
分页时验证
round保留小数后几位
v1=round(3.1415926,2)
print(v1) #3.14
*第二组
min取最小值
v1=[11,22,33]
res=min(v1)
max最大值
all检测元素是否都是True
v1=[1,2,3,4,5]
res=all(v1) #True
v2=[1,2,0,4,5]
res=all(v2) #False
user=input("")
pwd=input("")
is_valid=all(is_valid)
if is_valid:
print("用户名和密码都不为空,输入正确")
print(user,pwd)
else:
print("用户或密码为空")
any只要有True就行
2=[0,0,0,0,5]
res=aany(v2) #True
*第三组
v1=90 #十进制
v2="0b101010" #二进制
v3="0o102" #八进制
v4="0x1ab" #十六进制
十进制——>二进制
v1=bin(90) #0b1011010
二进制——>十进制
v2=int("0b101010",base=2) #base=2二进制字符串
十进制——>八进制
v1=oct(90) #0o132
八进制——>十进制
v2=int("0b101010",base=b) #base=8八进制字符串
十进制——>十六进制
v1=hex(90)
十六进制——>十进制
v2=int("0b101010",base=2) #base=16十六进制字符串
给一个IP地址ip="192.168.11.23",将IP地址转换成二进制
192——>
168——>
11——>
23——>
再进行拼接,转成十进制数字
ip="192.168.11.23"
bin_str=""
for item in ip.split("."): #["192","168","11","23"]
v1=int(item)
v2=bin(v1)
v3=v2[2:] #bin_list.append(v3)
#bin_string="".join(bin_list)
#bin_str=bin_str+v3
bin_str+=v3
print(bin_str)
result=int(bin_str,base=2)
print(result)
*第四组
v1=ord("A")
print(v1) #得到字符串的十进制65
v2=chr(65)
print(v2) #得到对应的字符A
生成随机验证码
import random
data_list=[]
for i in range(5):
data=random.randint(65,90) #A-Z
char=chr(data)
data_list.append(char)
res=''.join(data_list)
print(res)
生成随机汉字
import random
data_list=[]
for i in range(20):
data=random.randint(20208,20495) #汉字区间
char=chr(data)
data_list.append(char)
res=''.join(data_list)
print(res)
*第五组
int
str
bool
list
dict
tuple
float
float(3.14)
bytes
bytes("张三",encoding='utf-8')
*第六组
len
print
input
open
range
hash #计算一个值得到哈希值
type #查看数据类型
callable #判断是否可执行——>函数名
v1="root"
data=callable(v1) #False
enumerate循环过程中自动生成一列值
goods=["手机","电脑"]
for i,item in enumerate(goods,1) #从序号1 开始排序
print(i,item)
sorted排序
num_list = [10, 2, 45, 789, 3] #字符串和汉字按照万国表排序
# 生成新的值从小到大排序
v1 = sorted(num_list)
print(v1)
# 生成新的值从大到小排序
v2 = sorted(num_list,reverse = True)
print(v2))
num_list=["1.基础","2.进阶","10.升级"]
1 2 10
def ff(x)
return int(x.split(".")[0]) #ff=lambda x:int(x.split(".")[0])
v1 = sorted(num_list,key=ff) #传一个参数key等于函数
练习
找到某个路径下所有的文件
import os
res=os.listdir(r"文件路径") #得到一个列表
name_list=sorted(num_list,key=lambda x:int(x.split(".")[0]))
for i in name_list:
print(i)
2.生成器函数yield
##定义函数时,函数中出现了yield关键字,此函数为生成器函数
def func()
print(123)
yield 1
print(456)
yield 2
print(789)
yield 3
##执行生成器函数,返回一个生成器对象
obj=func()
##生成器对象.__next__就会进入函数去执行,一旦遇到yield跳出
v1=obj.__next__()
print(v1) #1
##生成器对象.__next__就会进入函数去执行,从上一次位置开始继续执行
v2=obj.__next__()
print(v2)
##生成器对象.__next__就会进入函数去执行,从上一次位置开始继续执行
v3=obj.__next__()
print(v3)
##生成器对象.__next__就会进入函数去执行,从上一次位置开始继续执行
v4=obj.__next__()
print(v4) #报错,生成器函数执行结束
123
1
456
2
789
3
def func():
yield 1
yield 2
yield 3
obj=func():
for item in obj():
print(item)
创建一些数字,不真创建,代码逻辑后续逐一生成数字,循环获取
def gen_big_data(limit):
num=0
while num<limit:
yield num
num+=1
big=gen_big_data()
for item in big:
print(item) # 0 1 2 ...
v1=range(10000000000000) #类似生成器的原理
3.高阶函数&闭包
高阶函数
def func():
print(123)
def s():
print(999)
return s
v1=func() #123 s()
v1() #999
闭包,通过函数嵌套机制,先将数据封装到作用域中(包),后续再执行内部函数时,再去获取之前封装进去的值即可
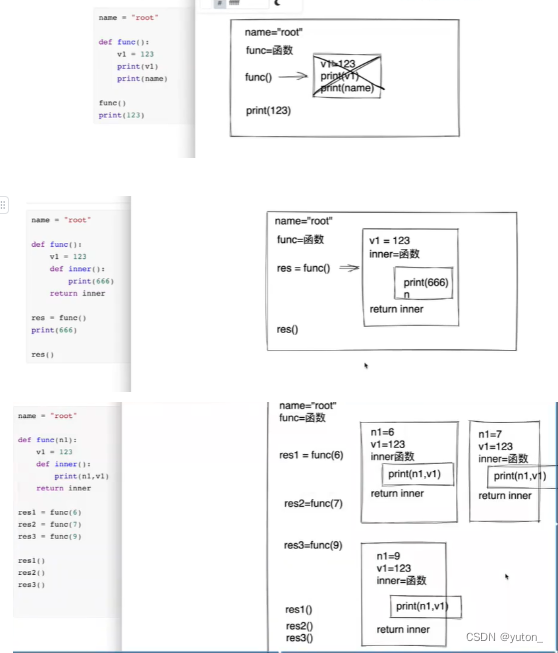
线程池
import time
from concurrent.futures import ThreadPoolExecutor
def task():
print("开始了")
time.sleep(4)
#线程池中最多创建5个线程
pool=ThreadPoolExecutor(5)
#10个任务
for i in range(10):
pool.submit(task)
4.装饰器
不修改原代码内容的情况下,进行功能的扩展
本质上利用了嵌套,闭包,@语法,构建出来一个功能,满足在不修改原函数内部代码的前提下,可以在函数执行前和执行后扩展我们的自定义功能
#创建外部函数,默认有一个参数
def outer(func):
def inner():
#
res=func()
#
return res
return inner
@outer #func=outer(func)
def show():
print(123)
return 999
show()
print(v1) #999
现在有一个函数,执行函数前和执行函数后,自定义功能:输出before和after
def func():
print("我是func函数")
value = "中国联通"
return value
def xx(a1):
#a1=原来的那个fuc函数
def inner():
print("brfore")
result =a1()
print('after')
return result
return inner()
func = xx(func)
res = func()
优化
def func1(a1):
def inner():
pass
return inner
#执行func()函数,将@下面的函数,当成函数名传递进去,即func1(func2),将的到的值赋值给func2
#即执行func2=func1(func2)得到的返回值
@func1
def func2():
print("我是func函数")
value = "中国联通"
return value
res = func2()
需求:现在有三个函数,应用到这三个函数上,在装饰器上计算函数运行时间
import time
def timer(func):
def inner():
satrt = time.time()
res=func()
end = time.time()
interval = end - satrt
print("共耗时{}".format(interval))
return res
return inner
@timer
def f1():
count = 0
for i in range(1000):
count += 1
@timer
def f2():
v3 = 1000 + 10
@timer
def f3():
import requests
requests.get("url地址")
f1()
f2()
f3()
需求:有一个函数,装饰器实现,执行五次函数将值返回拼接到一个列表中,将列表返回
def repeat(func):
def inner():
result=[]
for i in range(5):
res=func()
result.append(res)
return result
return inner
@repeat
def f1():
print("执行函数")
return 8
v1=f1()
print(v1)
需求:定义一个函数,在函数内部打开读取文件.创建装饰器,在装饰器中实现,检查文件路径是否存在,存在则继续执行函数,不存在返回None
import os
def check_file(func):
def inner(file_path):
#检测文件是否存在
if os.path.exists(file_path):
return None
res = func(file_path)
return res
return inner
@check_file
def read_info(file_path):
f = open(file_path, mode='r', encoding='utf-8')
data = f.read()
f.close()
return data
value=read_info("db.txt")
print(value)
5.推导式
用更少的代码去实现某个特定功能
需求:创建列表,列表=["用户-0","用户-1","用户-2","用户-3"....]
data_liat=[]
for i in range(51):
datt_list.append("用户-{}".format(i))
列表推导式
data_list=[ i for i in range(51) ] #[0,1,2,3...50]
print(data_list)
data_list=[ 100 for i in range(51) ] #[100,100,100...]50个
print(data_list)
data_list=[ 100+i for i in range(51) ] #[101,102...]
print(data_list)
data_list=[ (10,i) for i in range(51) ] #[(10,0),(10,2)...]
print(data_list)
data_list=[ "用户-{}".format(i) for i in range(51) ] #[(10,0),(10,2)...]
print(data_list)
data_list=[ i for i in range(51) if i>9] #[10,11,12,13....]
print(data_list)
字典推导式
info={i:123 for i in range(10)} #{0:123,1:123.....}
print(info)
info={i:123 for i in range(10) if i>5} #{6:123,7:123.....}
print(info)
练习
拿到一个列表,将列表中的每个元素尾部的.mp4剔除
data_list=[
'1-1编译器.MP4'
'1-2作业.MP4'
'1-3答案.MP4'
'1-3练习.txt'
]
data_list1=[ i.rsplit(".",maxsplit=1)[0] for i in data_list if i.endswith(".mp4")]
print(data_list1)
有一组字符串,生成字典结构
data_str="name=张三&mail=xx@.com&age=12"
info={i.split("=")[0]:i.split("=")[1] for i in data_str.split("&")}
info={
"name":"张三",
"mail":"xx@.com",
"age":"12"
}
有一个字典,将字典构造成字符串
info={
"name":"张三",
"mail":"xx@.com",
"age":"12"
}
data_list=["{}={}".format(k,v) for k,v in info.items()]
data_str="&"join(data_list)
print(data_str)
print(data_list)
#data_list="&".join(["{}={}".format(k,v) for k,v in info.items()])
data_str="name=张三&mail=xx@.com&age=12"
微信支付,微信对API授权,加密校验过程,根据键从小到大排序最终获取字符串data_str="sing_type=MD5&appid=wx4678&total_fee=9901"
info={
"sing_type":"MD5",
"appid":"wx4678",
"total_fee":"9901"
}
data="&".join("{}={}".format(key,info[key])for key in sorted(info.keys())])
#排序后的结果['appid', 'sing_type', 'total_fee']

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









