



 本文指导如何在PyCharm中下载并使用fetch_20newsgroups数据集,通过TfidfVectorizer和MultinomialNB实现朴素贝叶斯算法对新闻进行分类,包括数据预处理和模型评估。
本文指导如何在PyCharm中下载并使用fetch_20newsgroups数据集,通过TfidfVectorizer和MultinomialNB实现朴素贝叶斯算法对新闻进行分类,包括数据预处理和模型评估。
下载地址 http://qwone.com/~jason/20Newsgroups/20news-bydate.tar.gz
先需要到以上的地址下载fetch_20newsgroups的压缩包
下载后的压缩包名字应该为20news-bydate.tar.gz
先将压缩包放入C:\\Users\\(自己的电脑名)\\scikit_learn_data\\20news_home\\的文件夹中
首先找到Pycharm右下角的这个解释器(Python3.11(每个人的地址可能不一样,有些人可能是默Python安装的默认地址)),点击它,进入interpreter Steeings里
进入后查看解释器所在的地址,先别着急进入地址,看下一步
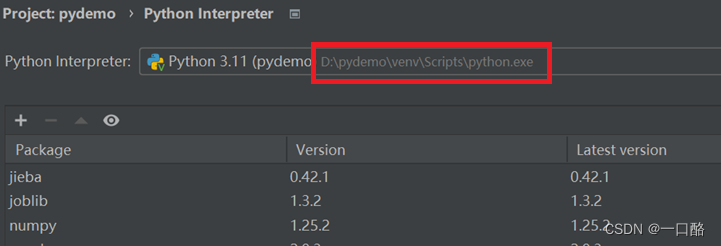
像我的在D盘,就是要找到这个地址里的Lib文件D:\pydemo\venv\Lib\site-packages\sklearn\datasets里面有一个 _twenty_newsgroups.py 文件,你自己可以对着自己的地址查找看看,只需要找到最后这个文件即可

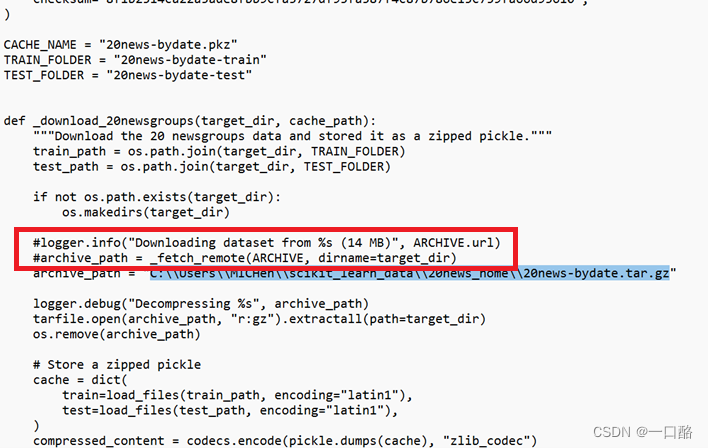
其次我们用记事本打开找到一个是(在代码开头往下很近的地方)def _download_20newsgroups(target_dir, cache_path):的函数,将这个红框里的注释掉(里边代码是下载的意思)
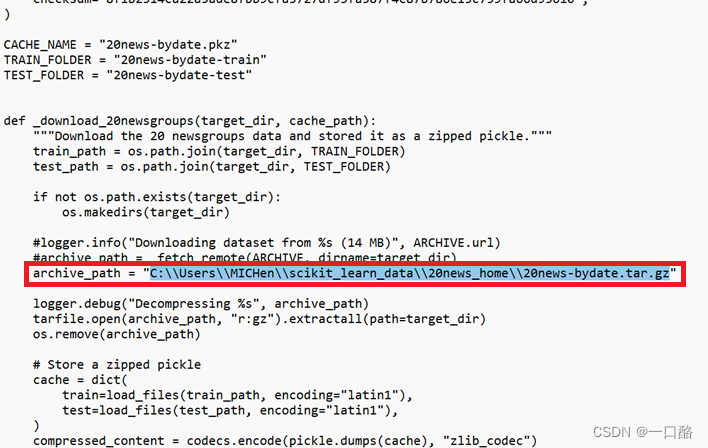
最后添加一行之前20news-bydate.tar.gz的地址,记得地址改成双斜杠!!!
最终去Pycharm里面调用即可,耐心等待,需要一会的时间,以后直接调用即可,文件会自动解压为默认路径的20news-bydate_py3.pzk文件(C:\Users\(自己的电脑名)\scikit_learn_data)

调用fetch_20newsgroups的朴素贝叶斯算法
#朴素贝叶斯算法运用代码
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
def nb_news():
#用朴素贝叶斯算法对新闻进行划分
#获取数据
news = fetch_20newsgroups(subset='all')
#划分数据集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target)
#特征工程:文本特征提取-tfidf
transfer = TfidfVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
#朴素贝叶斯算法预估器流程
estimatro = MultinomialNB()
estimatro.fit(x_train, y_train)
#模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimatro.predict(x_test)
print("y_predict\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确值
score = estimatro.score(x_test, y_test)
print("准确率为\n", score)
return None
if __name__=="__main__":
nb_news()


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









