




 本文详细介绍了如何使用Scrapy爬取腾讯招聘网站的岗位信息,并实现翻页功能。首先通过分析网页请求发现目标URL,然后通过观察规律实现翻页。在解析数据时,同时获取岗位ID,用于进一步获取岗位职责。最后,展示了如何在Scrapy中使用`meta`参数将数据传递给后续回调函数,完成岗位职责的抓取。代码示例清晰地展示了整个爬取过程。
本文详细介绍了如何使用Scrapy爬取腾讯招聘网站的岗位信息,并实现翻页功能。首先通过分析网页请求发现目标URL,然后通过观察规律实现翻页。在解析数据时,同时获取岗位ID,用于进一步获取岗位职责。最后,展示了如何在Scrapy中使用`meta`参数将数据传递给后续回调函数,完成岗位职责的抓取。代码示例清晰地展示了整个爬取过程。
需求:爬取腾讯招聘岗位 、翻页
https://careers.tencent.com/search.html?index=1
如下:
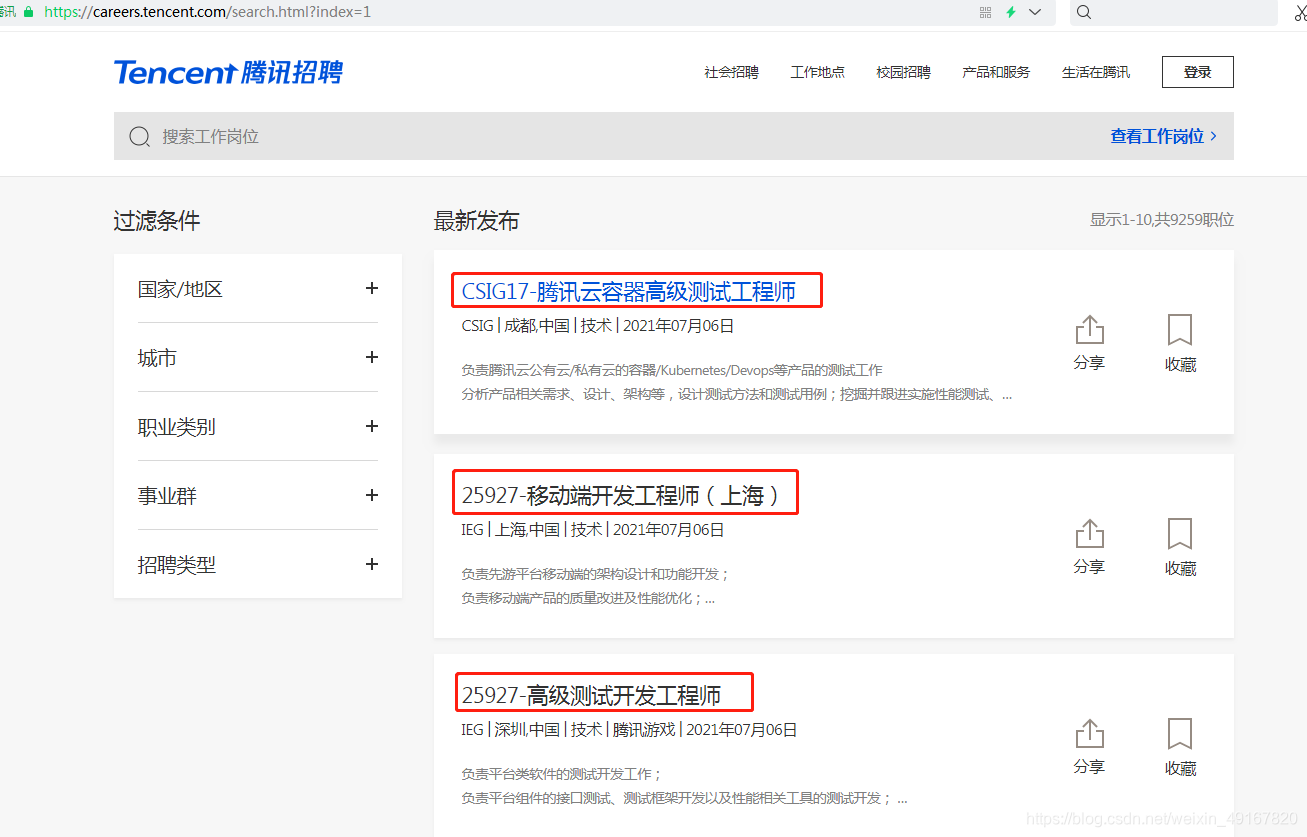
第一步 分析页面
1、数据在哪里获取?
我们在网页源代码中找下,是否有目标数据:
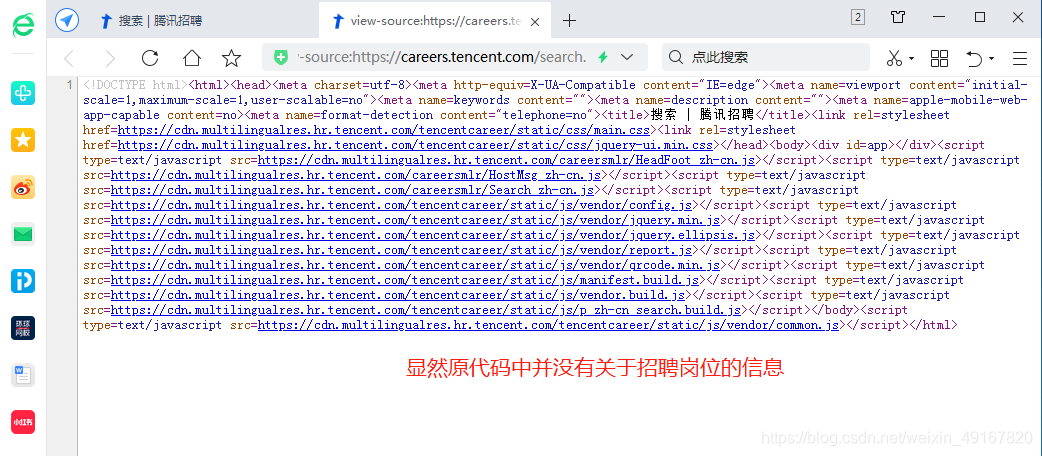
显然原代码中并没有关于招聘岗位的信息,所以我们不能对该url(https://careers.tencent.com/search.html?index=1)发起并获得响应,再替换page的数字来翻页,进而完成任务。
我们右键检查,在network-XHR中,可以发现下图右下角红框,点击看到response,ctrl+f搜索招聘岗位中的25927,发现了response中包含该数据。
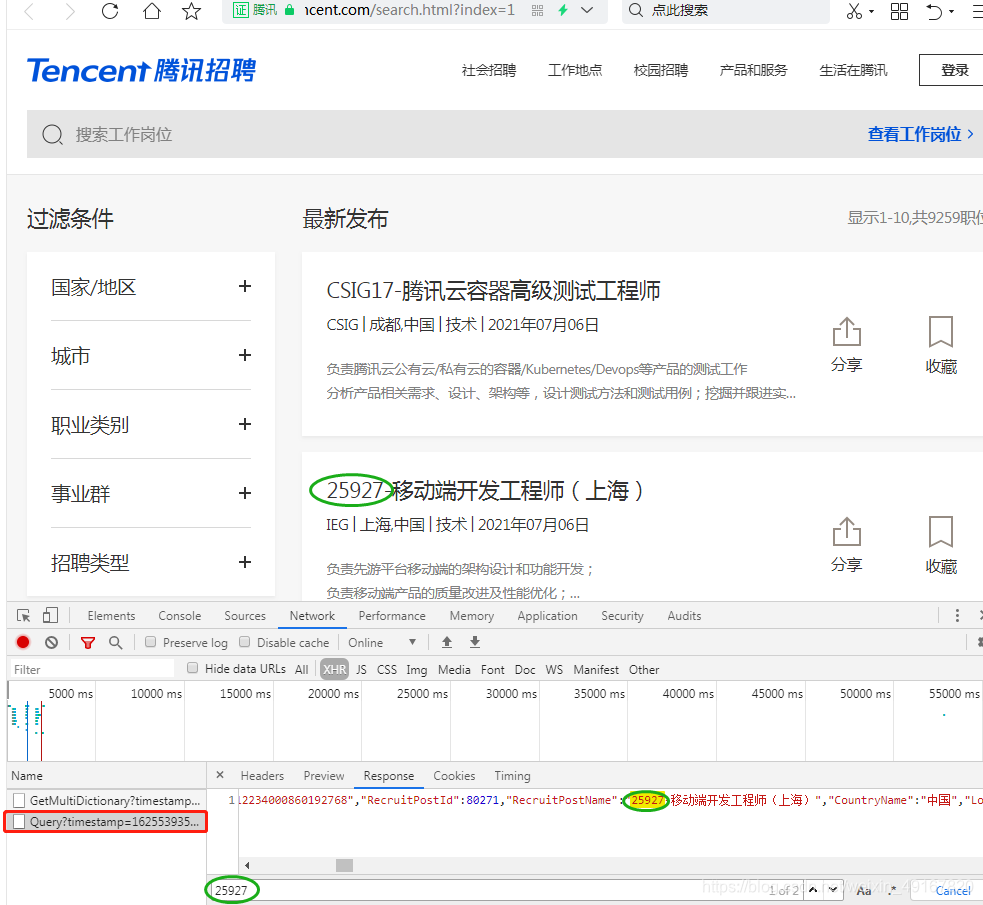
,就确认了我们要的目标url就在对应的Headers中,见下图。
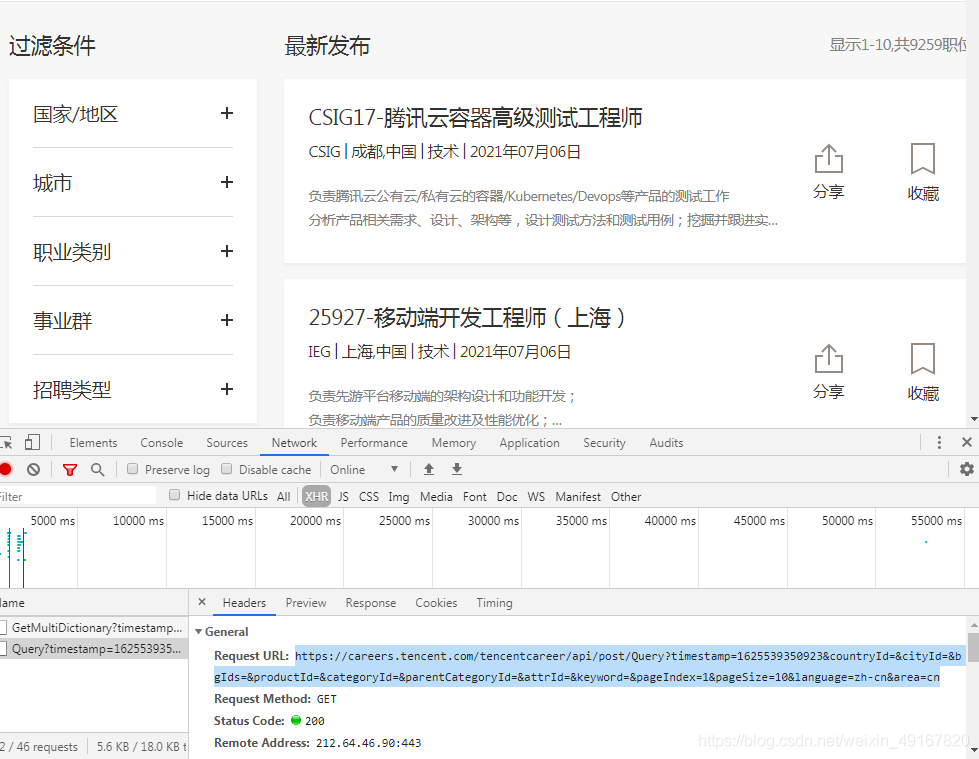
即目标url:
https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1625539350923&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&a
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 5536
5536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









