



 本文详细介绍了MCDF系统中模块的组织结构,包括package的使用、FIFO的设计、grant信号的生成逻辑,以及arbiter的仲裁机制。文中通过实验对比和代码分析,解释了不同配置如何影响系统行为,并展示了如何进行寄存器读写、数据一致性、通道开关和优先级测试。此外,还探讨了低带宽下行数据流对系统性能的影响。
本文详细介绍了MCDF系统中模块的组织结构,包括package的使用、FIFO的设计、grant信号的生成逻辑,以及arbiter的仲裁机制。文中通过实验对比和代码分析,解释了不同配置如何影响系统行为,并展示了如何进行寄存器读写、数据一致性、通道开关和优先级测试。此外,还探讨了低带宽下行数据流对系统性能的影响。
1、实验3到实验4为什么多了很多的package模块?
因为实验4的接口、模块变多了,所以针对他们有各自的package,设计文件也从MCDT转变为MCDF;
2、mcdf的文件夹编译有先有后,编译顺序为arbiter、formater、reg、salve_fifo,再编译mcdf模块。
3、可回顾实验0,各部分的功能。
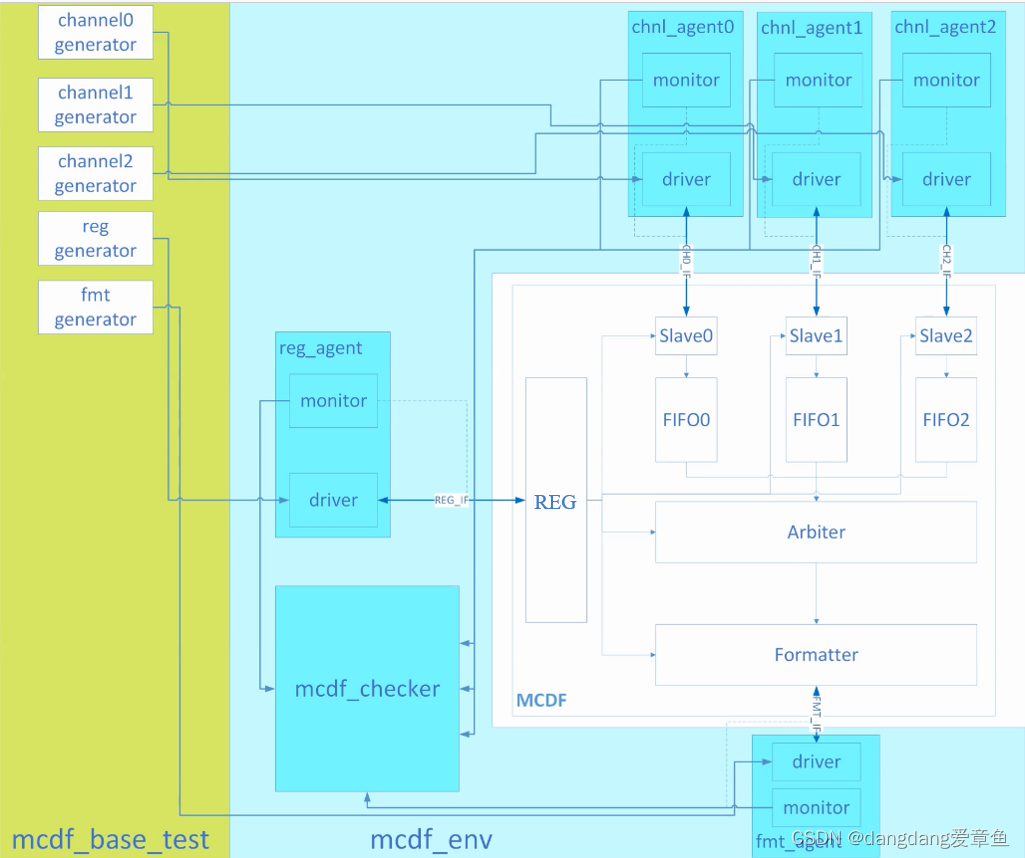
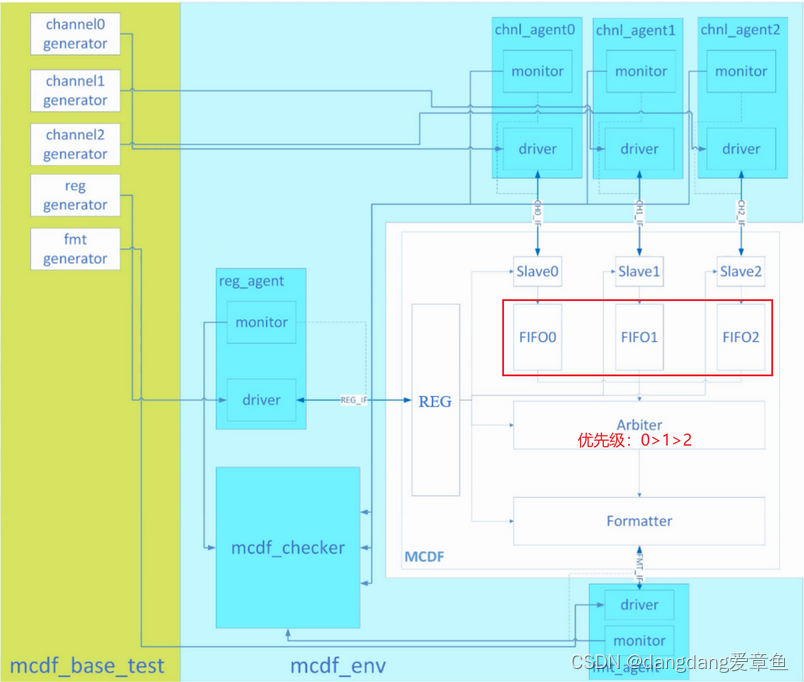
4、看tb文件的顺序为:1)DUT接口;2)环境中例化的接口,FMT_IF,REG_IF,CH_IF;3)各个pkg中的drv、mon等都是啥(定义2个时钟driver时钟和monitor时钟);4)顶层盒子env环境的结构,组件如何连接的;5)test是如何协调各个generater来工作的。
5、chnl和reg的driver是initiator,主动发起请求;而fmt的driver是responder,主动发起请求的是DUT里的formatter,信号是reg。
responder需要模块从端接收、消化数据的功能。而消化数据有快有慢,需要设立一个大小不同的FIFO的模拟。
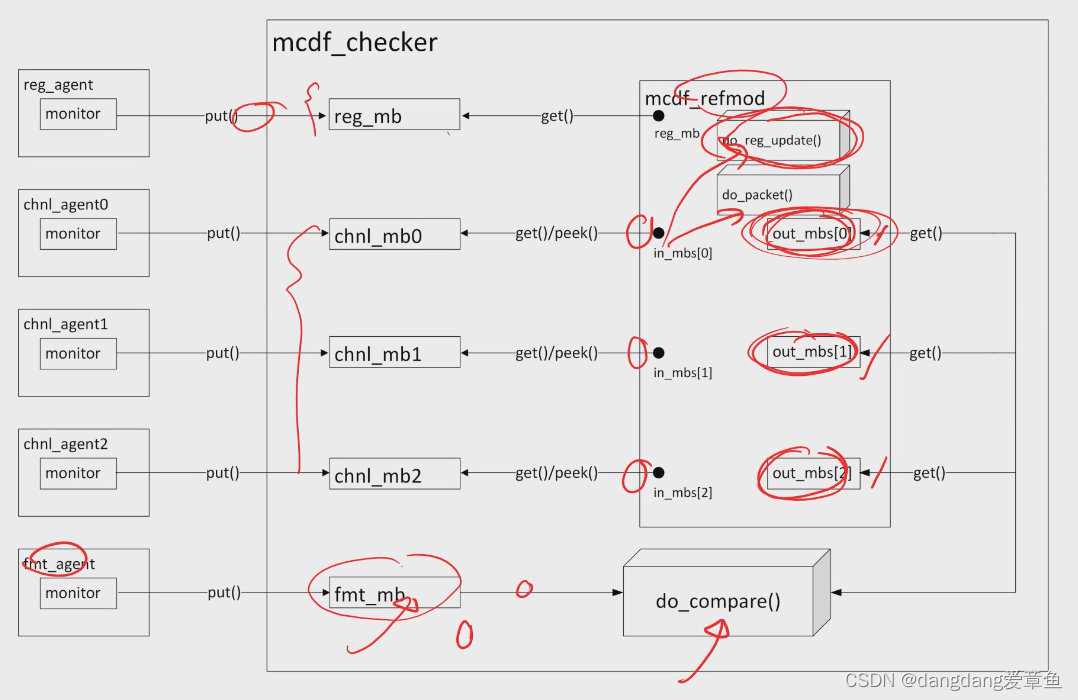
6、为何formatter里只有一个FIFO,而模仿formatter的mcdf_refmod里对应部分却有3个?
- 实际上,目前的mcdf_refmod的功能是不完整的,它模拟了reg的配置功能以及对chnl数据的打包,但是没有模拟REG让哪些chnl开关的功能以及arbiter的仲裁功能。
- 所以mcdf_refmod目前假定arbiter没有丢数,而且优先级的功能正常。这样的mcdf_refmod只能检查打包数据的完整性,但无法检查数据的顺序(优先级不同,顺序不同)。如何检查跟着实验要求之后说。
- 比较的逻辑:fmt_mb里的数据是监测formatter的,只有一个fifo(fifo的特点是先进先出),放着全部的数据。而各个out_mbs放着对应自己chnl的数据。比较时,先从fmt_mb里拿一个数据,知道对应的id后就直接去对应的out_mbs里取数,如果正常的话,取出来的就是和fmt_mb里的数据一样。
验证框图:
代码细品
A.fmt_grant可否像通道从端接口时序里的ready一样设为1,等没准备好时再设为0?**
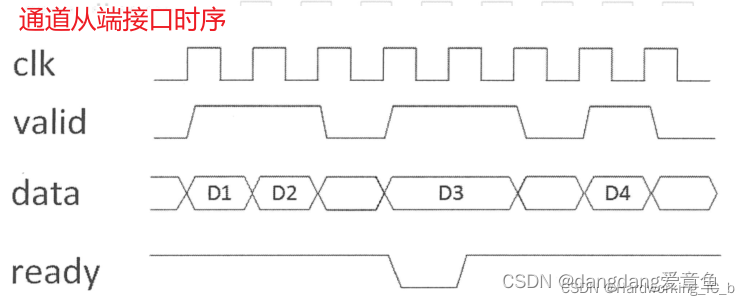
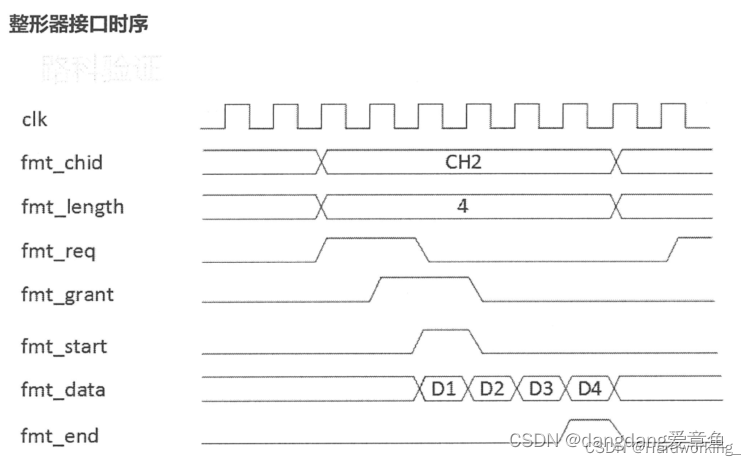
不可以!
(1)首先通道从端的部分chna_agent是属于initiator,主动发起请求。我们在写它的时候侧重点在于发送数据是否有效,相比于fmt_agent多了一个valid信号;而fmt_agent的driver是responder,属于被动响应,侧重点在于模仿formatter的下行,需要关注因为下行的差异导致的grant信号发送速度的快慢。
(2)fmt_agent模仿formatter的下行,那么下行的FIFO空间不固定,有大有小;FIFO空间大可以快速拉高grant信号;而下行对数据的消化速度也是不一样的,有快有慢,较快的消化速度有助于及时拉高grant;
因此,下行准备好的时间不是固定的,grant信号的拉高时间也是有快有慢的。如果直接将grant信号默认设为1,就无法达到模拟效果。
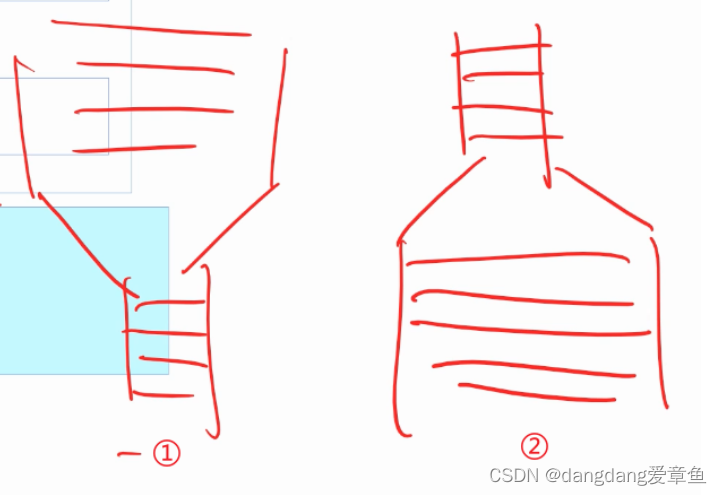
①FIFO的空间比较小,消化数据比较慢,那么grant信号的拉高就比较慢;就像上图①中的管道一样,上面(formatter)的流量很大,但是下半段空间小,那么水也只能慢慢流出;
②FIFO的空间比较大,消化数据比较快,那么grant的回复就比较快,也就是可以在req发出来后的第二个时钟周期,grant就拉高;就像上图②中的管道一样,上面(formatter)的流量很小,而下半段管道很粗,那么从上面来的水就可以马上流出。
B.在fmt_driver里,既然在do_config里会对fifo例化,那么为什么还要在new函数里先例化?而且还给fifo的容量设置了4096这么大的空间?
function new(string name = "fmt_driver");
this.name = name;
this.fifo = new(); //例化
this.fifo_bound = 4096;
this.data_consum_peroid = 1;
endfunction
task do_config();
fmt_trans req, rsp;
forever begin
this.req_mb.get(req);
case (req.fifo)
SHORT_FIFO: this.fifo_bound = 64;
MED_FIFO: this.fifo_bound = 256;
LONG_FIFO: this.fifo_bound = 512;
ULTRA_FIFO: this.fifo_bound = 2048;
endcase
this.fifo = new(this.fifo_bound); //重新例化,开辟空间
case(req.bandwidth)
LOW_WIDTH: this.data_consum_peroid = 8;
MED_WIDTH: this.data_consum_peroid = 4;
HIGH_WIDTH: this.data_consum_peroid = 2;
ULTRA_WIDTH: this.data_consum_peroid = 1;
endcase
rsp = req.clone();
rsp.rsp = 1;
this.rsp_mb.put(rsp);
end
endtask
P1. 在fmt_driver里,既然在do_config里会对fifo例化,那么为什么还要在new函数里先例化fifo?
- 这个问题有个假设,就是do_config需要存在,也就是你需要一开始就进行配置。但这个假设并不是一直成立。若没有do_config,比如一些组件作为slave,他不可能每次接收master的数据都是先配置。
- 这种情况下,你就没有办法通过req_mb得到req,也就不知道req.fifo,没法得到fifo_bound,因此也就无法根据fifo_bound的大小来对fifo进行new,那么fmt_pkg也就不工作了,没法模拟下行。
- 事先例化fifo,其实就相当于一个初始值,让fmt_pkg在没有配置的时候也能工作。
P2. 为什么初始化时还给fifo的容量设置了4096这么大的空间?
- fifo_bound需要给初始值,否则默认为0,那么下面语句给fifo设置空间也会出问题。
this.fifo = new(this.fifo_bound);
- 此处fifo_bound设置为4096,以及data_consum_peroid设置为1,只是为了让FIFO的空间比较大,消化数据比较快,那么当fmt发送req时,fmt_pkg模拟的下行能够更快地让grant拉高。
- 也就是说,这里将fifo_bound设置成4096并不是一个硬性的要求,也可以是其他的数值,比如64、256等等,目的都是为了更快地让grant拉高。
- 不探究fifo_bound和data_consum_peroid的影响时,就选一个最好的值就行了。等需要探究了,再特地改变他们的值。(比如下行从端低带宽测试就是探究低带宽带来的影响)
C. 如何理解reg_pkg中reg_driver里的reg_write的这两句:repeat(2) @(negedge intf.clk); t.data = intf.cmd_data_s2m;
task reg_write(reg_trans t);
@(posedge intf.clk iff intf.rstn);
case(t.cmd)
`WRITE:begin
intf.drv_ck.cmd_addr <= t.addr;
intf.drv_ck.cmd <= t.cmd;
intf.drv_ck.cmd_data_m2s <= t.data;
end
`READ:begin
intf.drv_ck.cmd_addr <= t.addr;
intf.drv_ck.cmd <= t.cmd;
repeat(2) @(negedge intf.clk);
t.data = intf.cmd_data_s2m; //是=,没有drv_ck
end
`IDLE:begin
this.reg_idle();
end
default: $error("command %b is illegal", t.cmd);
endcase
$display("%0t reg_driver [%s] sent addr %2x, cmd %2b, data %8x", $time, name, t.addr, t.cmd, t.data);
endtask
解析:
其实也是为了避免采样的竞争问题。
若cmd为READ,DUT会在下一个周期将数据驱动到接口cmd_data_s2m处;如下图所示:
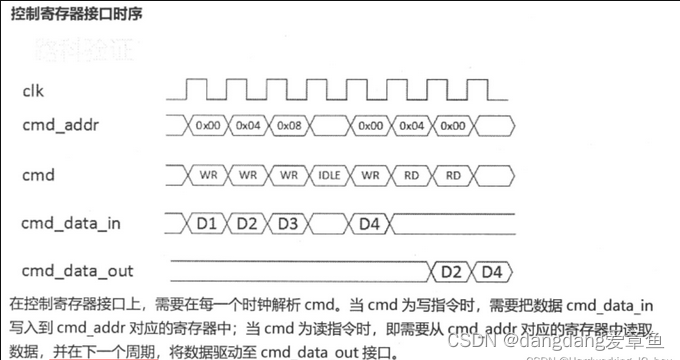
①如果TB进行采样时,直接选择在下个周期的上升沿采,可能采不到正确的值。因为此处用的是阻塞赋值“=”,存在竞争冒险情况,此时采样可能采不到要读的数据。
②而如果在当前周期再过两个下降沿去采数据,就能避免上述问题。第一个下降沿还在当前周期,第二个下降沿就在下一个周期了。此时数据已经驱动到接口cmd_data_s2m处了,这时去采样接口处的数据就一定是要读的数据。
C1. 为什么reg_write里的赋值有时用“=”有时用“<=”?
要给接口时钟块内的信号传递数据,就要用非阻塞<=,来模拟时序逻辑;
如果不用时钟块,那就是组合逻辑,就用阻塞=。
C2. 为何在reg_monitor里,对于READ命令,就选择在下一拍的clk上升沿进行采样,而不像reg_driver里等下一拍的下降沿才去采样?
task mon_trans();
reg_trans m;
forever begin
@(posedge intf.clk iff(intf.rstn && intf.mon_ck.cmd != `IDLE));//为IDLE无意义
m = new();
m.addr = intf.mon_ck.cmd_addr;
m.cmd = intf.mon_ck.cmd;
if(intf.mon_ck.cmd == `WRITE) begin
m.data = intf.mon_ck.cmd_data_m2s;
end
else if(intf.mon_ck.cmd == `READ) begin
@(posedge intf.clk); // 漏了,注意是下一拍写的数据才会给
m.data = intf.mon_ck.cmd_data_s2m;//注意,此处是通过mon_ck时钟块采的,和driver里不同
end
mon_mb.put(m);
$display("%0t %s monitored addr %2x, cmd %2b, data %8x", $time,this.name, m.addr, m.cmd, m.data);
end
endtask
其实这两种方式应该都可以,只是都是为了正确地采集到下一周期才输出到cmd_data_out的数据。区别在于有没有用时钟块。
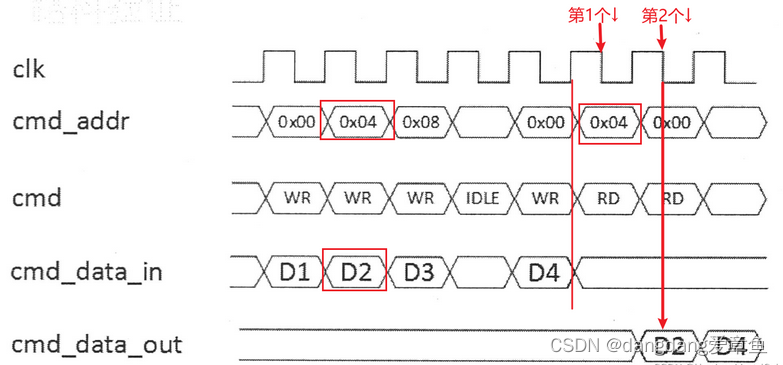
1、reg_driver里是不通过时钟块采样,就需要避免竞争问题。下图中0x04里的数据是D2。我们在READ信号来之后的第二个下降沿去采样cmd_data_out,是可以准确采到D2的。
task do_reg_update(); //对读写寄存器进行读操作没必要更新,因为此处最终是为了更新
reg_trans t; //你才把值写到读写寄存器里,所以你读它的数据,肯定是同一个
forever begin //既然是同一个了你还更新干嘛,所以没必要
this.reg_mb.get(t);
if(t.addr[7:4] == 0 && t.cmd == `WRITE) begin//读写寄存器&写操作
this.regs[t.addr[3:2]].en = t.data[0];
this.regs[t.addr[3:2]].prio = t.data[2:1];
this.regs[t.addr[3:2]].len = t.data[5:3];
end
else if(t.addr[7:4] == 1 && t.cmd == `READ) begin//只读寄存器&读操作
this.regs[t.addr[3:2]].avail = t.data[7:0];
end
end
endtask
- 首先要知道下面几点 我们根据addr[7:4]来区分读写/只读寄存器,如果是0就是读写寄存器,是1就表示只读寄存器。
- 根据addr[3:2]来区分寄存器的编号。
- regs[]是mcdf_refmod里用来模拟DUT里的寄存器的,会先读取DUT寄存器里的配置信息存储在regs里,然后就把这些信息更新到refmod里
- 对于只读寄存器,那么就只需要考虑READ命令就行。
那么问题来了,为什么对于读写寄存器,我们没有考虑读的情况呢?
if(t.addr[7:4] == 0 && t.cmd == `WRITE)
测试:
完整性测试
代码:
class mcdf_data_consistence_basic_test extends mcdf_base_test;
function new(string name = "mcdf_data_consistence_basic_test");
super.new(name);
endfunction
task do_reg();
bit[31:0] wr_val, rd_val;
// slv0 with len=8, prio=0, en=1
wr_val = (1<<3)+(0<<1)+1;
this.write_reg(`SLV0_RW_ADDR, wr_val);
this.read_reg(`SLV0_RW_ADDR, rd_val);
void'(this.diff_value(wr_val, rd_val, "SLV0_WR_REG"));
// slv1 with len=16, prio=1, en=1
wr_val = (2<<3)+(1<<1)+1;
this.write_reg(`SLV1_RW_ADDR, wr_val);
this.read_reg(`SLV1_RW_ADDR, rd_val);
void'(this.diff_value(wr_val, rd_val, "SLV1_WR_REG"));
// slv2 with len=32, prio=2, en=1
wr_val = (3<<3)+(2<<1)+1;
this.write_reg(`SLV2_RW_ADDR, wr_val);
this.read_reg(`SLV2_RW_ADDR, rd_val);
void'(this.diff_value(wr_val, rd_val, "SLV2_WR_REG"));
// send IDLE command
this.idle_reg();
endtask
task do_formatter();
void'(fmt_gen.randomize() with {fifo == LONG_FIFO; bandwidth == HIGH_WIDTH;});
fmt_gen.start();
endtask
task do_data();
void'(chnl_gens[0].randomize() with {ntrans==100; ch_id==0; data_nidles==0; pkt_nidles==1; data_size==8; });
void'(chnl_gens[1].randomize() with {ntrans==100; ch_id==1; data_nidles==1; pkt_nidles==4; data_size==16;});
void'(chnl_gens[2].randomize() with {ntrans==100; ch_id==2; data_nidles==2; pkt_nidles==8; data_size==32;});
fork
chnl_gens[0].start();
chnl_gens[1].start();
chnl_gens[2].start();
join
#10us; // wait until all data haven been transfered through MCDF
endtask
endclass
分析:
1、这里解释一下wr_val的意思,以slv2为例。
bit(5:3)对应数据包长度,序号和对应的长度解码表如下:
| 序号 | 对应长度 |
|---|---|
| 0 | 4 |
| 1 | 8 |
| 2 | 16 |
| 3 | 32 |
| 4-7 | 32 |
| 因为bit(5:3)、bit(2:1)、bit(0)分别为数据包长度、优先级、通道使能信号,可以通过移位的方式来表示wr_val。 | |
| 这里3<<3中的第一个3可以通过解码表知道其表示数据包长度为32,通过左移3位的方式移动到bit(5:3)。 |
2、在看波形的时候还发现了有趣的地方。从下面的波形上看,好像只是一开始的时候3个通道同时发送,但是过了某个时间之后,你会发现已经按通道0、1、2的顺序依次发送了。这是为啥?
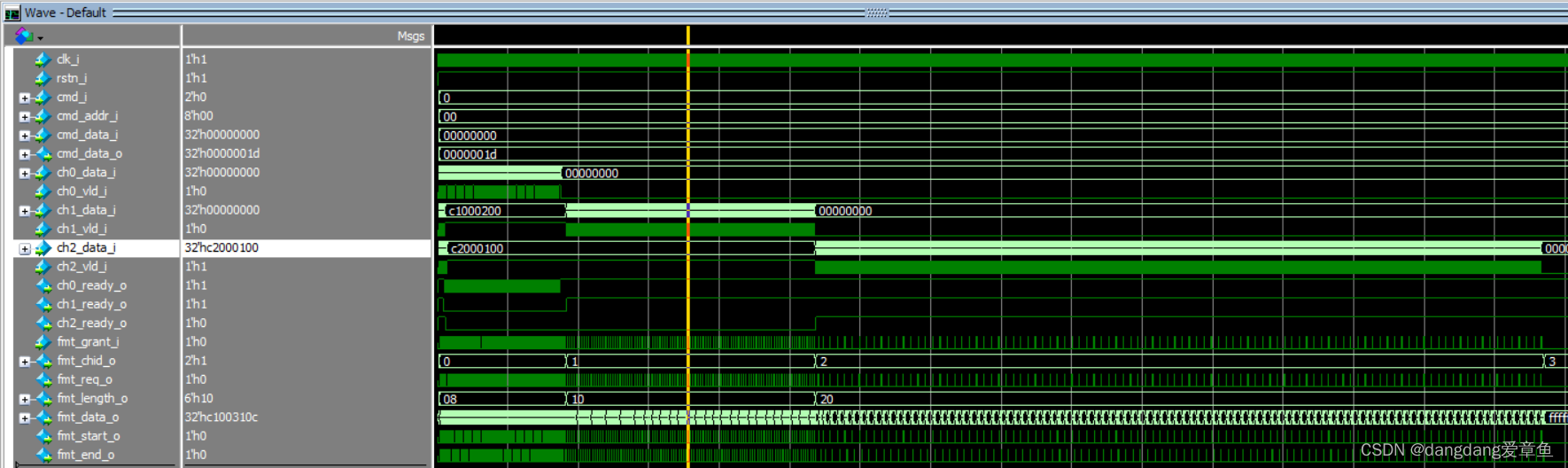
不是明明在class mcdf_env里写的是同时发送吗?
virtual task run();
$display($sformatf("*****************%s started********************", this.name));
this.do_config();
fork
this.chnl_agts[0].run();
this.chnl_agts[1].run();
this.chnl_agts[2].run();
……
join
endtask
其实答案在于三个通道的优先级不同。
- 首先,三个chnl_agts同时向slave-fifo发送数据,而发送到通道0、1、2的data_size不一样,分别为8、16、32,这些数据暂时存在了FIFO0、FIFO1、FIFO2里。
- 由于我们在mcdf_data_consistence_basic_test 里定义了优先级排序是0>1>2,所以当三个通道同时申请仲裁时,先通过0的,再通过1的,最后才是2。因此就出现了上面的波形。
- 如果你在mcdf_data_consistence_basic_test 把优先级排序改成2>1>0,那么情况就反了。

寄存器读写测试:
这个测试项目很简单,就是将写进寄存器的配置读回来,然后比较一下看对不对。
代码:
class mcdf_reg_stability_test extends mcdf_base_test;
function new(string name = "mcdf_data_consistence_basic_test");
super.new(name);
endfunction
task do_reg();
bit[7:0] chnl_rw_addrs[] = '{`SLV0_RW_ADDR, `SLV1_RW_ADDR, `SLV2_RW_ADDR};
bit[7:0] chnl_ro_addrs[] = '{`SLV0_R_ADDR, `SLV1_R_ADDR, `SLV2_R_ADDR};
int pwidth = `PAC_LEN_WIDTH + `PRIO_WIDTH + 1;
bit[31:0] check_pattern[] = '{((1<<pwidth)-1), 0, ((1<<pwidth)-1)};
bit[31:0] wr_val, rd_val;
// RW register access and bits toggle
foreach(chnl_rw_addrs[i]) begin
foreach(check_pattern[i]) begin
wr_val = check_pattern[i];
this.write_reg(chnl_rw_addrs[i], wr_val);
this.read_reg(chnl_rw_addrs[i], rd_val);
void'(this.diff_value(wr_val, rd_val));
end
end
// RO register read access
foreach(chnl_ro_addrs[i]) begin
this.read_reg(chnl_ro_addrs[i], rd_val);
end
// send IDLE command
this.idle_reg();
endtask
endclass
代码解析:
bit[31:0] check_pattern[] = '{((1<<pwidth)-1), 0, ((1<<pwidth)-1)};
- check_pattern[]也就是要写进寄存器的数,(1<<pwidth)-1是32’b111111
- 所以此处的do_reg就是先把32’b111111写进reg,再读回来看是否一致;同样地,分别写进32’h0和32’b111111并读回来。
寄存器稳定性测试:
spec里提到了读写寄存器(31:6)是无法写入的,所以我们要测试一下是否真的无法写入。

class mcdf_reg_illegal_access_test extends mcdf_base_test;
function new(string name = "mcdf_reg_illegal_access_test");
super.new(name);
endfunction
task do_reg();
bit[7:0] chnl_rw_addrs[] = '{`SLV0_RW_ADDR, `SLV1_RW_ADDR, `SLV2_RW_ADDR};
bit[7:0] chnl_ro_addrs[] = '{`SLV0_R_ADDR, `SLV1_R_ADDR, `SLV2_R_ADDR};
int pwidth = `PAC_LEN_WIDTH + `PRIO_WIDTH + 1; //=6
bit[31:0] check_pattern[] = '{32'h0000_FFC0, 32'hFFFF_0000};
bit[31:0] wr_val, rd_val;
// RW register write reserved field and check
foreach(chnl_rw_addrs[i]) begin
foreach(check_pattern[j]) begin
wr_val = check_pattern[j];
this.write_reg(chnl_rw_addrs[i], wr_val);
this.read_reg(chnl_rw_addrs[i], rd_val);
void'(this.diff_value(wr_val & ((1<<pwidth)-1), rd_val));//将期望值和读出来的值对比
end
end
// RO register write reserved field and check (no care readable field
// value)
foreach(chnl_ro_addrs[i]) begin
wr_val = 32'hFFFF_FF00;
this.write_reg(chnl_ro_addrs[i], wr_val);
this.read_reg(chnl_ro_addrs[i], rd_val);
void'(this.diff_value(0 , rd_val & 32'hFFFFFF00));
end
// send IDLE command
this.idle_reg();
endtask
endclass
代码解析:
1、check_pattern[ ]怎么理解?
- pwidth = `PAC_LEN_WIDTH + `PRIO_WIDTH + 1 = 6
- (1<<pwidth)-1='b1000000-1='b0111111
- wr_val & ((1<<pwidth)-1)也就是wr_val &'b0111111,表示只取wr_val的低6位,这是我们期望读回来的值
- diff_value(wr_val & ((1<<pwidth)-1), rd_val)将期望值与读回来的值rd_val进行比较
2、为什么在写入时要分两次(也就是32’h0000_FFC0, 32’hFFFF_0000)来写bit[31:6],直接用32’hFFFF_FFC0一次性进行操作不就行了?
- 如果只是要检查保留域的话,用32’hFFFF_FFC0一次性写入没有问题
- 如果想要避免数据的粘连问题,分两次可能更佳。举个例子来加深对粘连问题的理解:
- 如果你想要对低6位进行写入,来测试每个bit位是否可以正常翻转,有A和B两种写法:
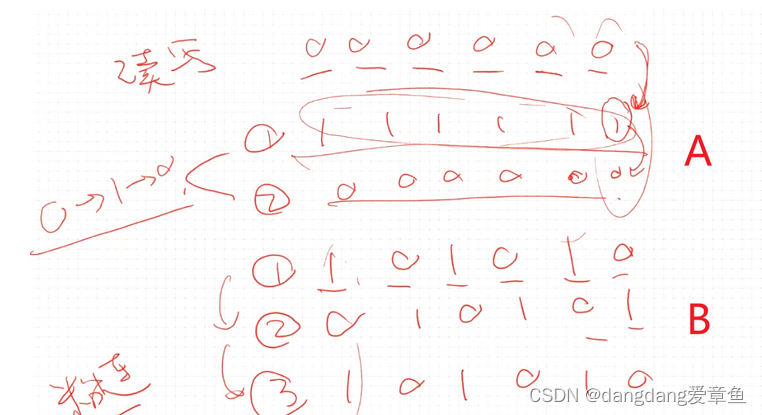
- 如果bit位之间不会相互干扰,那么可以直接通过操作A给数据进行测试。
- 但有时候可能设计疏忽了,导致对某一位进行操作时会影响到其他位,也就是说数据位之间存在粘连。那么就无法保证每一位都从0->1->0,此时操作B就可以避免这种问题。(其实还没有完全理解)
- UVM的bit_bash做的更精细,会单独地对每一位进行0->1->0的翻转,虽然测试更长,但是更准。
数据通道开关检查:
基本判断:
数据通道关闭时,mcdf_checker不会收到输入/出端的检测数据,因此也没有数据比较的信息。
测试通过标准:
1、此测试在最后的report中comparison count以及error count信息统计为0;
2、时序检查。当slave channel被关闭时,valid如果拉高,ready不应该出现拉高的情况,因为通道关闭,此时便不能接受数据,也就不应该给出可以接受数据的信号(ready)。
测试出现问题的可能原因:
- 数据可能没有被真正写入FIFO(?)
- slave channel没有被真正关闭
测试实现的思路:
用接口mcdf_intf来监测DUT里的通道使能信号en,将其传入mcdf_checker;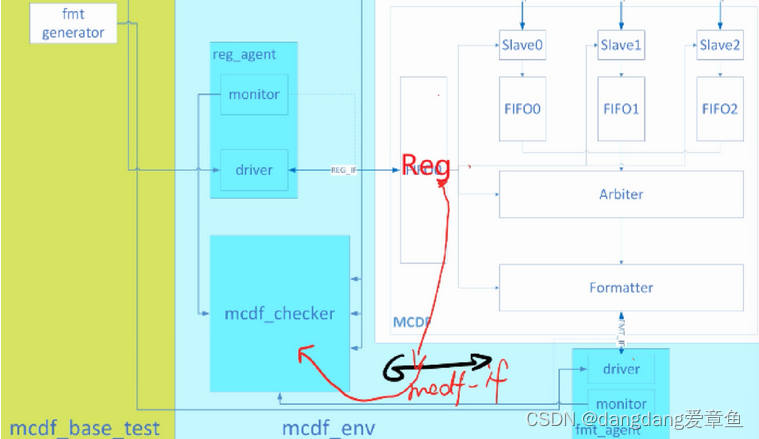
-
将chnl_intf中的valid、ready信号也传入mcdf_checker中。
-
通过观测valid、ready和en信号来完成此检查
代码实现:
task do_channel_disable_check(int id);
forever begin
@(posedge this.mcdf_vif.clk iff (this.mcdf_vif.rstn && this.mcdf_vif.mon_ck.chnl_en[id]===0));
if(this.chnl_vifs[id].mon_ck.ch_valid===1 && this.chnl_vifs[id].mon_ck.ch_ready===1)
rpt_pkg::rpt_msg("[CHKERR]",
$sformatf("ERROR! %0t when channel disabled, ready signal raised when valid high",$time),
rpt_pkg::ERROR,
rpt_pkg::TOP);
end
endtask
interface mcdf_intf(input clk, input rstn);
// USER TODO
// To define those signals which do not exsit in reg_if, chnl_if, arb_if or fmt_if
logic chnl_en[3];
clocking mon_ck @(posedge clk);
default input #1ns output #1ns;
input chnl_en;
endclocking
endinterface
//mcdf 接口抓取MCDF内部的en信号
assign mcdf_if.chnl_en[0] = tb.dut.ctrl_regs_inst.slv0_en_o;
assign mcdf_if.chnl_en[0] = tb.dut.ctrl_regs_inst.slv1_en_o;
assign mcdf_if.chnl_en[0] = tb.dut.ctrl_regs_inst.slv2_en_o;
其中,ctrl_regs_inst是DUT寄存器ctrl_regs的实例,里面有发送给各channel的通道使能信号slv0_en_o、slv1_en_o、slv2_en_o。将这些信号给到mcdf_if,配合valid、ready信号进行测试。
除了监测DUT内部的en信号,还可以调用mcdf_refmod里面的get_field_value()得到通道使能信号RW_EN。因为他们的数据都是一样的,都来自reg_agent。
只需将
@(posedge this.mcdf_vif.clk iff (this.mcdf_vif.rstn && this.mcdf_vif.mon_ck.chnl_en[id]===0));
改为:
@(posedge this.mcdf_vif.clk iff (this.mcdf_vif.rstn && refmod.get_field_value(id, RW_EN)===0);
当然,这样写是有前提的:
- 你的refmod的监测功能需要是正常的,也就是说refmod寄存器里更新的值要和监测到DUT寄存器里的信号是一样的。
注意:
不要轻易监测DUT内部信号,往往在你监测DUT内部信号时,一定存在着假设,也就是你要监测的内部信号的产生是合理的。
上述代码存在着假设:寄存器的配置、发送没有问题。也就是:
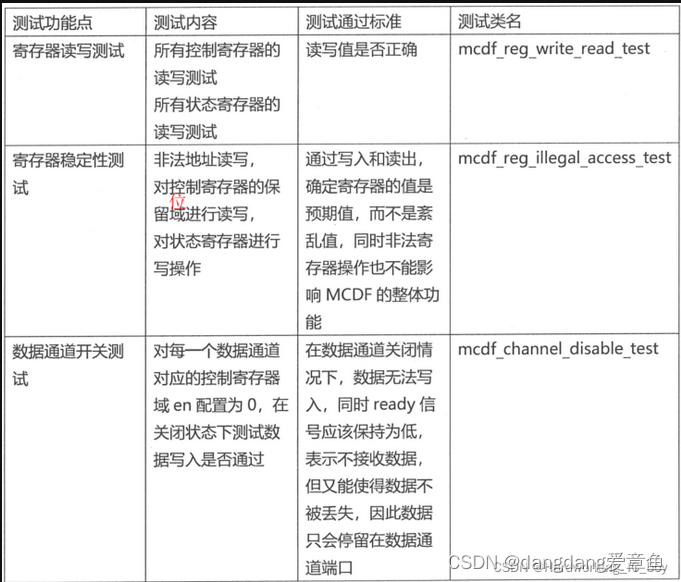
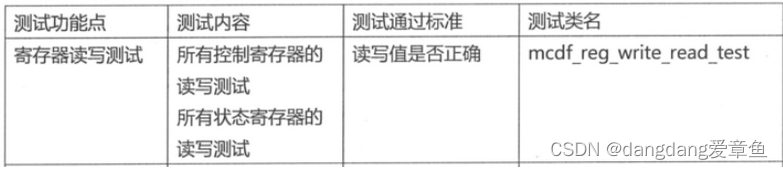
假设1:外部的reg_agent对寄存器的配置信息正常送到了寄存器中。这个假设可以通过寄存器读写测试来覆盖到,也就是检测寄存器的读写值是否正确,对应的测试类名是mcdf_reg_write_read_test。
假设2:在假设1的基础上,DUT中寄存器的en信号可以准确送到3个channel,也就是寄存器和3个channel的连接正常。比如,如果寄存器和channel 0 的连接出了问题,没有把寄存器的en信号为0(关闭)传过去,那么当valid为1时,ch_ready有可能还为1。
分析:
我们在mcdf_data_consistence_basic_test里把通道0和1关闭,只打开通道2,观察实验结果:
task do_reg();
bit[31:0] wr_val, rd_val;
// slv0 with len=8, prio=0, en=1
wr_val = (1<<3)+(0<<1)+0;
this.write_reg(`SLV0_RW_ADDR, wr_val);
this.read_reg(`SLV0_RW_ADDR, rd_val);
void'(this.diff_value(wr_val, rd_val, "SLV0_WR_REG"));
// slv1 with len=16, prio=1, en=1
wr_val = (2<<3)+(1<<1)+0;
this.write_reg(`SLV1_RW_ADDR, wr_val);
this.read_reg(`SLV1_RW_ADDR, rd_val);
void'(this.diff_value(wr_val, rd_val, "SLV1_WR_REG"));
// slv2 with len=32, prio=2, en=1
wr_val = (3<<3)+(2<<1)+1;
this.write_reg(`SLV2_RW_ADDR, wr_val);
this.read_reg(`SLV2_RW_ADDR, rd_val);
void'(this.diff_value(wr_val, rd_val, "SLV2_WR_REG"));
// send IDLE command
this.idle_reg();
endtask
可以从打印消息看出通道0和1被关闭了,没有比较信息,只有2有。
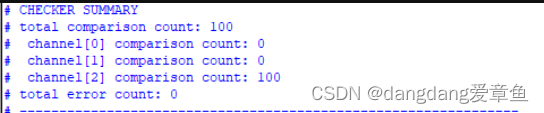
而从波形中也可以看出数据没有经过通道0和1,只有2有。

再放大一点看,可以看到通道0和1的valid信号为1,而ready信号一直没有拉高,说明我们的通道开关功能是正常的,测试通过。

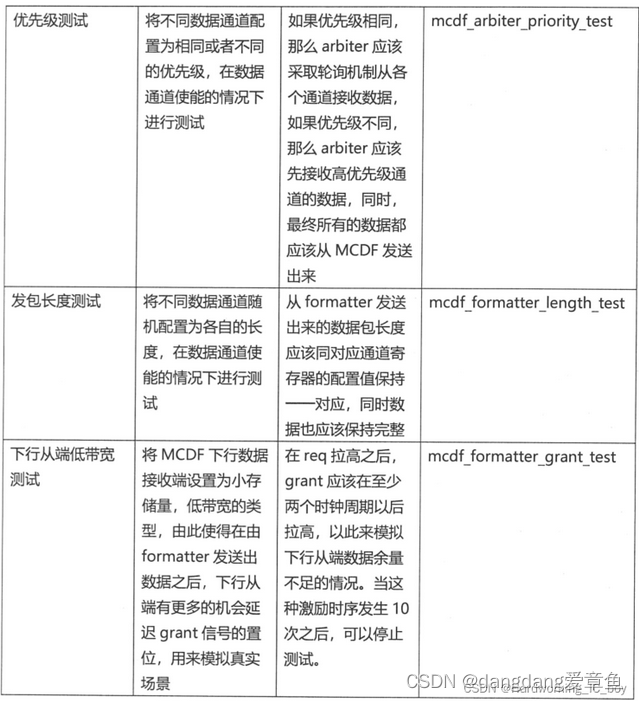
优先级测试:
要想实现这个优先级相同采取轮询机制的步骤,需要更新一下arbiter的代码,我们目前手头拿到的代码是没有加上轮询机制的。
arbiter 部分代码:
只要把arbiter中的下面部分增加轮询机制部分即可。
always @ (posedge clk_i or negedge rstn_i)
begin : CHANEL_SELECT
if (!rstn_i) id_sel_r = 2'b11;
else if (f2a_id_req_i)
//------------------此处为新增加的轮询机制部分,其他地方几乎不变------------------------------------
if({slv2_req_i,slv1_req_i,slv0_req_i} != 3'b000)//如果没有 Slave 申请权限,权限保持不变
begin
if(slv0_prio_i == slv1_prio_i && slv1_prio_i == slv2_prio_i)// 如果权限相同,轮询调度
begin
case(id_sel_r)
2'b00: begin
if(slv1_req_i == 1)
begin
id_sel_r <= 2'b01;
a2f_pkglen_sel_r = slv1_pkglen_i;
end
else if(slv2_req_i == 1)
begin
id_sel_r <= 2'b10;
a2f_pkglen_sel_r = slv2_pkglen_i;
end
end
2'b01: begin
if(slv2_req_i == 1)
begin
id_sel_r <= 2'b10;
a2f_pkglen_sel_r = slv2_pkglen_i;
end
else if(slv0_req_i == 1)
begin
id_sel_r <= 2'b00;
a2f_pkglen_sel_r = slv0_pkglen_i;
end
end
2'b10: begin
if(slv0_req_i == 1)
begin
id_sel_r <= 2'b00;
a2f_pkglen_sel_r = slv0_pkglen_i;
end
else if(slv1_req_i == 1)
begin
id_sel_r <= 2'b01;
a2f_pkglen_sel_r = slv1_pkglen_i;
end
end
default:
begin
id_sel_r <= 2'b00;
a2f_pkglen_sel_r = slv0_pkglen_i;
end
endcase
end
end
//----------------------------------------------------------------------------------------------
else
case ({slv2_req_i,slv1_req_i,slv0_req_i}) // 如果权限不同,优先级调度
3'b001: begin
id_sel_r <= 2'b00;
a2f_pkglen_sel_r = slv0_pkglen_i;
end
3'b010: begin
id_sel_r <= 2'b01;
a2f_pkglen_sel_r = slv1_pkglen_i;
end
3'b011: begin
if(slv1_prio_i >= slv0_prio_i)
begin
id_sel_r <= 2'b00;
a2f_pkglen_sel_r = slv0_pkglen_i;
end
else
begin
id_sel_r <= 2'b01;
a2f_pkglen_sel_r = slv1_pkglen_i;
end
end
3'b100: begin
id_sel_r <= 2'b10;
a2f_pkglen_sel_r = slv2_pkglen_i;
end
3'b101: begin
if(slv2_prio_i >= slv0_prio_i)
begin
id_sel_r <= 2'b00;
a2f_pkglen_sel_r = slv0_pkglen_i;
end
else
begin
id_sel_r <= 2'b10;
a2f_pkglen_sel_r = slv2_pkglen_i;
end
end
3'b110: begin
if(slv2_prio_i >= slv1_prio_i)
begin
id_sel_r <= 2'b01;
a2f_pkglen_sel_r = slv1_pkglen_i;
end
else
begin
id_sel_r <= 2'b10;
a2f_pkglen_sel_r = slv2_pkglen_i;
end
end
3'b111: begin
if(slv2_prio_i >= slv0_prio_i && slv1_prio_i >= slv0_prio_i)
begin
id_sel_r <= 2'b00;
a2f_pkglen_sel_r = slv0_pkglen_i;
end //priority 0>1 && 0>2
if(slv2_prio_i >= slv0_prio_i && slv1_prio_i < slv0_prio_i)
begin
id_sel_r <= 2'b01; //priority 1>0>2
a2f_pkglen_sel_r = slv1_pkglen_i;
end
if(slv2_prio_i < slv0_prio_i && slv2_prio_i >= slv1_prio_i)
begin
id_sel_r <= 2'b01; //priority 1>2>0
a2f_pkglen_sel_r = slv1_pkglen_i;
end
if(slv2_prio_i < slv0_prio_i && slv2_prio_i < slv1_prio_i)
begin
id_sel_r <= 2'b10; //priority 2>0 && 2>1
a2f_pkglen_sel_r = slv2_pkglen_i;
end
end
default: begin
id_sel_r <= 2'b11;
a2f_pkglen_sel_r = 3'b111;
end
endcase
else
begin
id_sel_r <= id_sel_r;
a2f_pkglen_sel_r <= a2f_pkglen_sel_r;
end
end
checker代码更新:
task do_arbiter_priority_check();
int id;
forever begin
@(posedge this.arb_vif.clk iff (this.arb_vif.rstn && this.arb_vif.mon_ck.f2a_id_req===1));
id = this.get_slave_id_with_prio(); //id的优先级最高
if(id >= 0) begin
@(posedge this.arb_vif.clk);
if(!(refmod.get_field_value(0,RW_PRIO) == refmod.get_field_value(1,RW_PRIO)
&& refmod.get_field_value(1,RW_PRIO) == refmod.get_field_value(2,RW_PRIO)))
if(this.arb_vif.mon_ck.a2s_acks[id] !== 1) //id的优先级最高,那么对应的a2s_acks应该为1,否则报错
rpt_pkg::rpt_msg("[CHKERR]",
$sformatf("ERROR! %0t arbiter received f2a_id_req===1 and channel[%0d] raising request with high priority, but is not granted by arbiter", $time, id),
rpt_pkg::ERROR,
rpt_pkg::TOP);
end
end
endtask
其中,下面这一句通过get_field_value函数获取每个chnl的优先级。如果三个优先级都不一样,那么就不会执行轮询,按照原来情况执行,也就是通过id优先级的高级来通过arbiter。
如果三个优先级都一样,那么就采用轮询机制,不执行接下来信息打印部分,否则就一定会报错。因为id的优先级最高,那么对应的a2s_acks应该为1。而轮询机制并不是按照优先级来控制a2s_acks信号,所以会出现错误。
if(!(refmod.get_field_value(0,RW_PRIO) == refmod.get_field_value(1,RW_PRIO)
&& refmod.get_field_value(1,RW_PRIO) == refmod.get_field_value(2,RW_PRIO)))
测试代码1:优先级不同
可以根据mcdf_data_consistence_basic_test 的代码调整一下优先级即可,比如此处我将2的优先级调为最大。
class mcdf_arbiter_priority_test extends mcdf_base_test;
function new(string name = "mcdf_arbiter_priority_test");
super.new(name);
endfunction
task do_reg();
bit[31:0] wr_val, rd_val;
// slv0 with len=8, prio=2, en=1
wr_val = (1<<3)+(2<<1)+1;
this.write_reg(`SLV0_RW_ADDR, wr_val);
this.read_reg(`SLV0_RW_ADDR, rd_val);
void'(this.diff_value(wr_val, rd_val, "SLV0_WR_REG"));
// slv1 with len=16, prio=1, en=1
wr_val = (2<<3)+(1<<1)+1;
this.write_reg(`SLV1_RW_ADDR, wr_val);
this.read_reg(`SLV1_RW_ADDR, rd_val);
void'(this.diff_value(wr_val, rd_val, "SLV1_WR_REG"));
// slv2 with len=32, prio=0, en=1
wr_val = (3<<3)+(0<<1)+1;
this.write_reg(`SLV2_RW_ADDR, wr_val);
this.read_reg(`SLV2_RW_ADDR, rd_val);
void'(this.diff_value(wr_val, rd_val, "SLV2_WR_REG"));
// send IDLE command
this.idle_reg();
endtask
task do_formatter();
void'(fmt_gen.randomize() with {fifo == LONG_FIFO; bandwidth == HIGH_WIDTH;});
fmt_gen.start();
endtask
task do_data();
void'(chnl_gens[0].randomize() with {ntrans==100; ch_id==0; data_nidles==0; pkt_nidles==1; data_size==8; });
void'(chnl_gens[1].randomize() with {ntrans==100; ch_id==1; data_nidles==1; pkt_nidles==4; data_size==16;});
void'(chnl_gens[2].randomize() with {ntrans==100; ch_id==2; data_nidles==2; pkt_nidles==8; data_size==32;});
fork
chnl_gens[0].start();
chnl_gens[1].start();
chnl_gens[2].start();
join
#10us; // wait until all data haven been transfered through MCDF
endtask
endclass
测试代码1分析
略
测试代码2:优先级相同
和上面的测试代码一样,只不过把优先级设为相同。
task do_reg();
bit[31:0] wr_val, rd_val;
// slv0 with len=8, prio=0, en=1
wr_val = (1<<3)+(0<<1)+1;
this.write_reg(`SLV0_RW_ADDR, wr_val);
this.read_reg(`SLV0_RW_ADDR, rd_val);
void'(this.diff_value(wr_val, rd_val, "SLV0_WR_REG"));
// slv1 with len=16, prio=0, en=1
wr_val = (2<<3)+(0<<1)+1;
this.write_reg(`SLV1_RW_ADDR, wr_val);
this.read_reg(`SLV1_RW_ADDR, rd_val);
void'(this.diff_value(wr_val, rd_val, "SLV1_WR_REG"));
// slv2 with len=32, prio=0, en=1
wr_val = (3<<3)+(0<<1)+1;
this.write_reg(`SLV2_RW_ADDR, wr_val);
this.read_reg(`SLV2_RW_ADDR, rd_val);
void'(this.diff_value(wr_val, rd_val, "SLV2_WR_REG"));
// send IDLE command
this.idle_reg();
endtask
测试代码2分析:
仿真运行,通过。
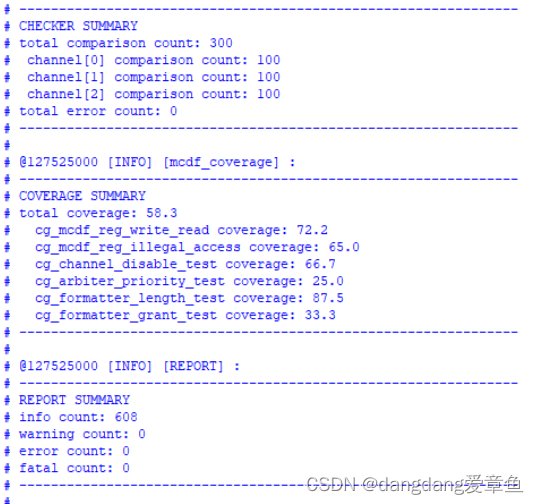
部分波形如下:
上图中,chnlx_data_i表示通过chnl发送的数据;fmt_data_o指通过fmt发送出去的数据;fmt_child_o表示当前发送的数据属于哪个通道。
可以看出三个通道的数据发送交替进行,实现轮询仲裁。
下行从端低带宽测试
代码:
class mcdf_down_stream_low_bandwidth_test extends mcdf_base_test;
function new(string name = "mcdf_down_stream_low_bandwidth_test");
super.new(name);
endfunction
task do_reg();
bit[31:0] wr_val, rd_val;
// slv0 with len=8, prio=0, en=1
wr_val = (1<<3)+(0<<1)+1;
this.write_reg(`SLV0_RW_ADDR, wr_val);
this.read_reg(`SLV0_RW_ADDR, rd_val);
void'(this.diff_value(wr_val, rd_val, "SLV0_WR_REG"));
// slv1 with len=16, prio=1, en=1
wr_val = (2<<3)+(1<<1)+1;
this.write_reg(`SLV1_RW_ADDR, wr_val);
this.read_reg(`SLV1_RW_ADDR, rd_val);
void'(this.diff_value(wr_val, rd_val, "SLV1_WR_REG"));
// slv2 with len=32, prio=2, en=1
wr_val = (3<<3)+(2<<1)+1;
this.write_reg(`SLV2_RW_ADDR, wr_val);
this.read_reg(`SLV2_RW_ADDR, rd_val);
void'(this.diff_value(wr_val, rd_val, "SLV2_WR_REG"));
// send IDLE command
this.idle_reg();
endtask
// configure formatter with short/medium fifo and low/medium bandwidth to
// mimic critical datapath
task do_formatter();
void'(fmt_gen.randomize() with {fifo inside {SHORT_FIFO, MED_FIFO}; bandwidth inside {LOW_WIDTH, MED_WIDTH};});
fmt_gen.start();
endtask
// Burst data packet transition for data pressure
task do_data();
void'(chnl_gens[0].randomize() with {ntrans==300; ch_id==0; data_nidles==0; pkt_nidles==1; data_size==8; });
void'(chnl_gens[1].randomize() with {ntrans==300; ch_id==1; data_nidles==0; pkt_nidles==1; data_size==16;});
void'(chnl_gens[2].randomize() with {ntrans==300; ch_id==2; data_nidles==0; pkt_nidles==1; data_size==32;});
fork
chnl_gens[0].start();
chnl_gens[1].start();
chnl_gens[2].start();
join
#10us; // wait until all data haven been transfered through MCDF
endtask
endclass
代码分析:
我试着将不同的FIFO容量和消耗数据的速度进行搭配,跑完测试后记录下各自所花的时间,如下表:
- SHORT_FIFO搭配LOW_WIDTH,看波形时发现前14次都是req的下一个周期就拉高grant,而在第15次就不是了,直接在req后的第18个周期才拉高grant;相比之下,ULTRA_FIFO搭配ULTRA_WIDTH,如果fifo空间又大,消耗数据又很快,那么给出grant信号就会很快,因此每一次都是req的下一个周期就拉高grant。
- 如果fmt_agt消耗数据很快,那么就算其fifo容量小一点也无所谓,fmt_agt会较快地给formatter发送grant信号,因此阻塞的时间就会缩短,结束测试的时间也更快。
- 但是如果消耗数据所花的时间比较长,就算你的fifo稍微大一些也无济于事,fifo很快就满了,所以fmt_agt会较慢地给出grant信号,阻塞的时间就长,结束测试的时间也更长。


















 831
831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









