




 英伟达提出LMFilter,一种无监督数据筛选方法,用于改善NoisyStudentTraining在非目标领域ASR任务中的性能。LMFilter利用模型之间的差异筛选数据,无需额外模型或标签。在AISHELL-1和AISHELL-2上,LMFilter显示了显著的性能提升,且代码已在WeNet开源。
英伟达提出LMFilter,一种无监督数据筛选方法,用于改善NoisyStudentTraining在非目标领域ASR任务中的性能。LMFilter利用模型之间的差异筛选数据,无需额外模型或标签。在AISHELL-1和AISHELL-2上,LMFilter显示了显著的性能提升,且代码已在WeNet开源。
为了改进 Noisy Student Training 在非目标领域 ASR 上的性能,英伟达提出新型数据筛选方法 LM Filter。其利用不同解码方式的识别文本之间的差异来作为数据筛选条件,是一个完全无监督的筛选过程。在 AIShell-1 上与无数据筛选的基线相比可以有 10.4% 的性能提升;在 AIShell-2 上可以取得 4.72% 字错误率。
目前该工作已投稿 ICASSP 2023,论文预览版可见:https://arxiv.org/pdf/2211.04717.pdf

代码已开源在 WeNet 社区,详见:
https://github.com/wenet-e2e/wenet/tree/main/examples/aishell/NST
Noisy Student Training 简介
半监督学习一直在语音识别领域受到广泛关注。这两年,Noisy Student Training (NST) 刷新并保持了 Librispeech 上 SOTA 结果[1],并且在数据量相对充沛的情况下,增加无监督数据仍然可以提升性能,因此有大批学术界和工业界的从业者在关注和改进该方法。
NST 可以看作是 Teacher Student Learning 的改进版本,它是一个自我迭代的过程。首先,我们使用有监督数据训练好一个 teacher 模型,使用这个模型在无监督数据上做 inference 得到伪标签。接着将带伪标签的无监督数据和有监督数据混合到一起,来训练 student 模型,在训练的时候通常会加入一些噪声来使得模型更加鲁棒,例如语音上常用的 SpecAug。我们让 student 成为新的 teacher,以此类推。这个过程如下图所示。
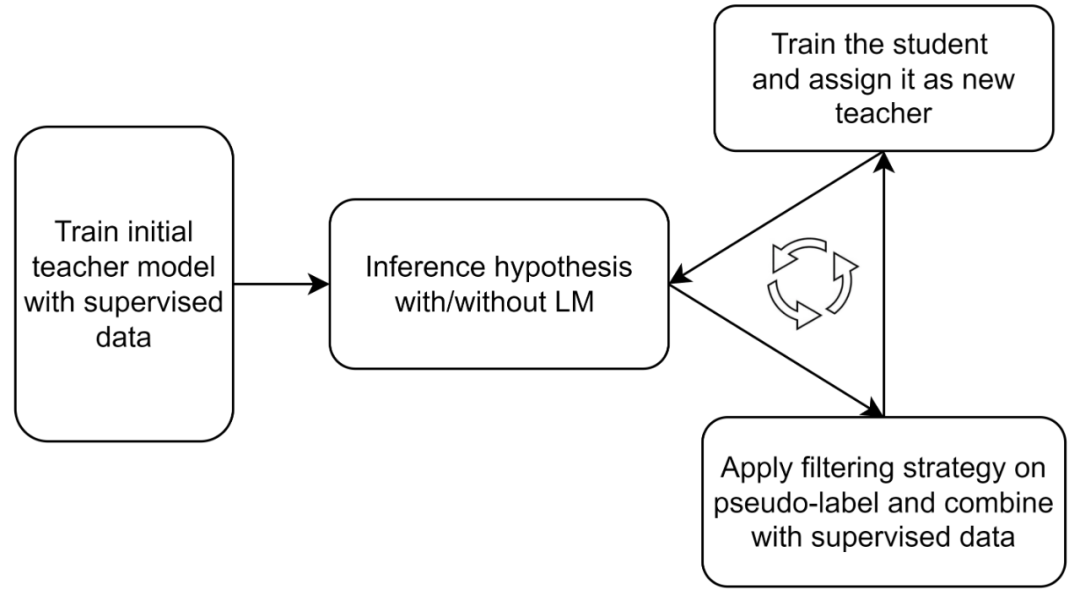
Motivation
NST 并没有在中文 ASR 任务中得到广泛研究,尤其是在有监督数据的领域与无监督数据的领域不匹配的情况下。
噪声和领域在 ASR 中起着重要的作用,来自社交媒体的大量无监督数据并不总能匹配任务所需的领域。因此,我们需要适当的数据筛选策略(Data Selection Strategy)来去除噪声并选择接近目标领域的数据。
常见的数据筛选策略
ASR 中最常见的数据筛选方式是置信度分数(Confidence Score),它根据置信度来选择合适的阈值来选择出可信的文本。但是,在具有大量领域不匹配的无标签数据的情况下,这种方法不一定可行。
近期有另一种新颖的无监督数据筛选的方式被提出[2],作者使用额外的对比语言模型(Contrastive Language Model)用作数据筛选,从而更好地改进目标域 ASR 任务。
在本文中,我们提出了一种新型的数据筛选策略,称之为 LM Filter,它可以利用模型差异性来筛选出更有价值的非目标领域的数据,来提高 NST 的性能。这种方法有以下的好处:
-
不需要额外的数据筛选模型。模型的差异可以从不同的解码策略(例如加不加语言模型)中获得。
-
不需要标签来进行数据筛选,是一个完全无监督的筛选过程。
-
训练 NST 所用的时间和资源更少,并且
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 354
354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









