






本次分为两个部分。第一部分介绍一个目前很火的大语言模型新的推理框架SGLang。第二部分分享一些大模型推理幻觉的一些研究工作。
SGLang
SGLang是一个对标vLLM的大语言模型推理框架, 系统的整体架构如下图,分为前端和后端。 前端是对调用大语言模型的一些常用操作的抽象,提供一系列原语。 后端是具体的对推理过程的优化。 SGLang的两点主要的优化是RadixAttention和Structured output。在此基础之上,作为大模型推理的基础框架, 后续也有很多其他的系统优化工作是在SGLang框架上的。

下图是一个使用SGLang框架的示例。

Motivation
SGLang的两个主要的优化点是:
-
在不同的请求之间共享KV Cache,复用更多的计算结果,减少计算量以达到加速的效果。
-
针对约束解码的情况, 通过压缩的状态机减少模型推理生成的token, 实现加速效果。
Radix-Attention
基础的kvcache是针对单个请求的,不同请求之间的kvcache是独立的。 而在推理模型的实际使用中,不同的请求之前往往会有大量重复的前缀(例如,一些常用的prompt,以及在推理时通过一些搜索、枚举的方法提高模型能力的技术等)。 这就提供了更多的优化空间。 RadixAttention可以看成是将不同请求的kvcache当成字符串, 将所有的请求构建成一个trie树。 此时对于新请求的kvcache,就可以看成是在这个缓存好的trie树上找到它的最长前缀, 实现最大程度的kvcache复用。
由于kvcache需要消耗显存, 而我们的显存是有限的, 我们只能存储下有限大小的trie树。 类似系统中的缓存, RadixAttention也需要一些机制去维护这个大小受限的trie树,同时尽可能地使得后续的请求能命中缓存。 一个额外的约束是在这个树结构的缓存中, 只能逐出叶子结点的元素,因为kvcache缓存的都是前缀,只有连续的前缀才是有效的。
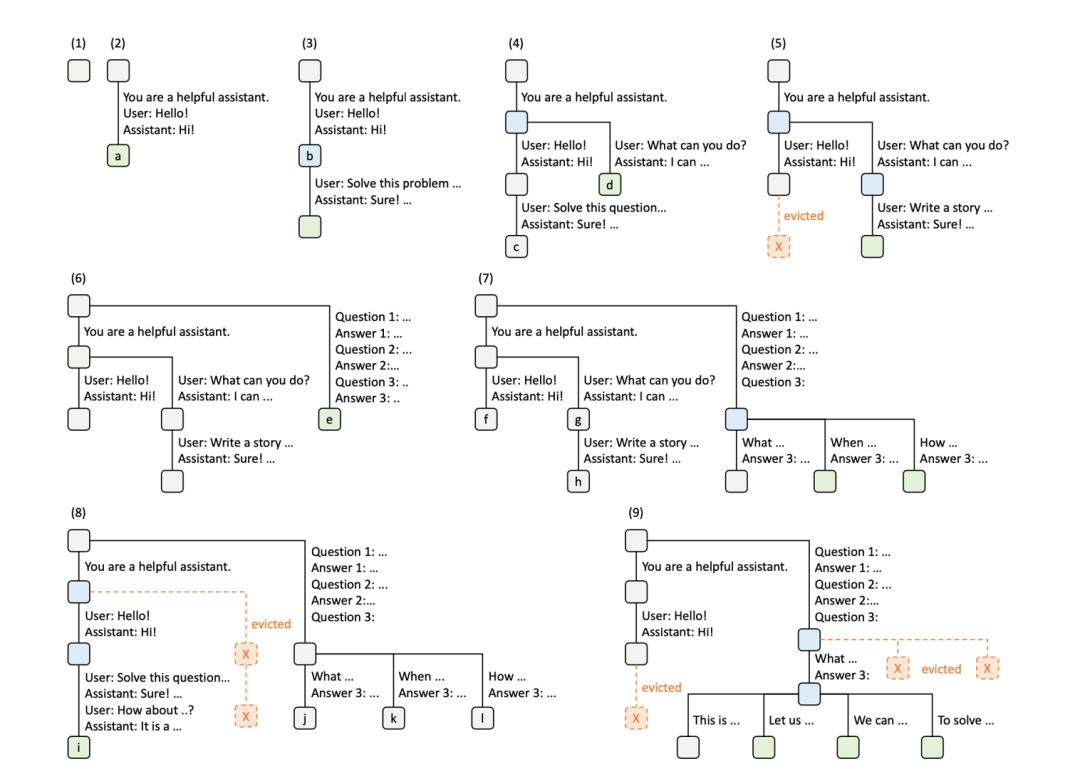
上图是维护radixattention的一个例子。 1~3是第一个请求多轮对话依次更新的过程。 4-5是处理第二个请求的过程。 前两个请求共享同样的system prompt "You are a helpful assistant." 在处理的时候查RadixAttention即可得到这个system prompt的kvcache,不需要重复计算。 接下来的tokens和已经缓存的不同,需要重新计算,并得到一个新的分叉。 注意到在5

















 808
808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









