








目录
一、引言
在朴素的深度学习ctr预估模型中(如DNN),通常以一个行为为预估目标,比如通过ctr预估点击率。但实际推荐系统业务场景中,更多是多种目标融合的结果,比如视频推荐,会存在视频点击率、视频完整播放率、视频播放时长等多个目标,而多种目标如何更好的融合,在工业界与学术界均有较多内容产出,由于该环节对实际业务影响最为直接,特开此专栏对推荐系统深度学习多目标问题进行讲述。
今天重点介绍“样本Loss提权”,该方法通过训练时Loss乘以样本权重实现对其它目标的加权,方法最为简单。
二、样本Loss提权
2.1 技术原理
所有目标使用一个模型,在标注正样本时,考虑多个目标。例如对于点击和播放,在标注正样本时,给予不同的权重,使它们综合体现在模型目标中。如下表,以视频业务为例,每行为一条训练样本,根据业务需要,把点击视频、视频完播、视频时长的权重分别设置为1、3、5。

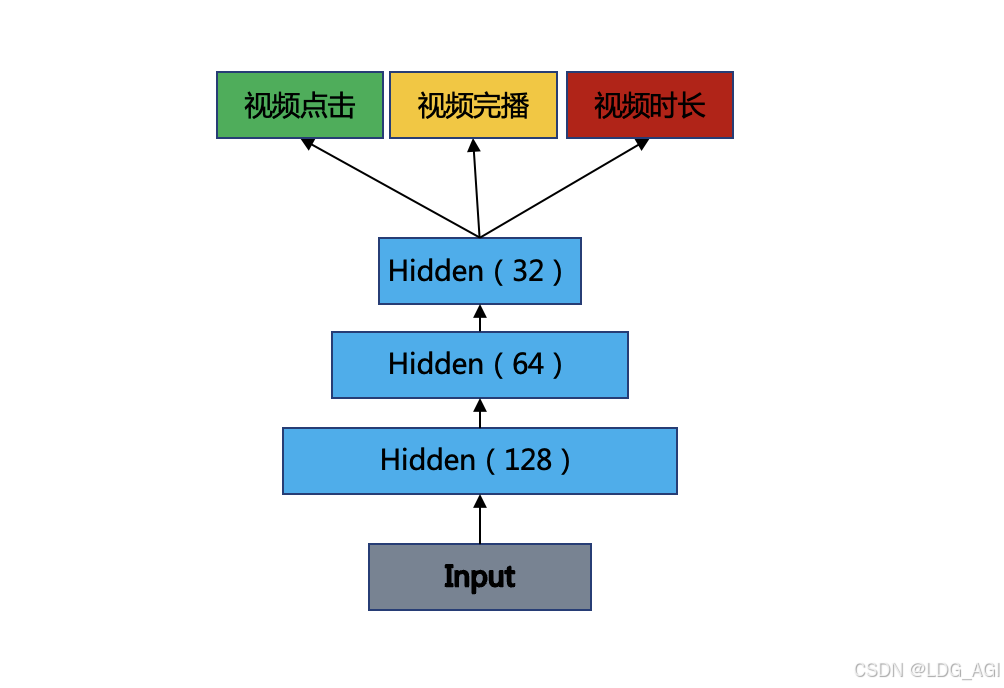
该方法通过对不同正向行为给予不同权重,将多目标问题转化为单目标问题。本质是保证一个主目标的同时,将其它目标转化为样本权重,达到优化其它目标的效果。

2.2 技术优缺点
优点:
- 模型简单:易于理解,仅在训练时通过Loss乘以样本权重实现对其它目标的加权
- 成本较低:相比于训练多个目标模型再融合,单模型资源及维护成本更低
缺点:
- 优化周期长:每次调整样本加权系数,都需要重新训练模型至其收敛
- 跷跷板问题:多个目标之间可能存在相关或互斥的问题,导致一个行为指标提升的同时,另一个指标下降。
2.3 代码实例
首先,我们需要定义一个DNN模型,并实现一个多目标样本损失函数loss加权算法。这个算法会为不同的目标分配不同的权重,以便在训练过程中优化每个目标
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 487
487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









