







 跳表是一种随机化的数据结构,用于快速查找、插入和删除操作,其性能与红黑树、AVL树相当。由William Pugh发明,跳表通过在有序链表上建立多级索引来加速搜索,平均时间复杂度为O(logn)。文章介绍了跳表的搜索、添加和删除操作的算法,并提供了一个简单的C语言实现。
跳表是一种随机化的数据结构,用于快速查找、插入和删除操作,其性能与红黑树、AVL树相当。由William Pugh发明,跳表通过在有序链表上建立多级索引来加速搜索,平均时间复杂度为O(logn)。文章介绍了跳表的搜索、添加和删除操作的算法,并提供了一个简单的C语言实现。
跳表全称叫做跳跃表,简称跳表。跳表是一个随机化的数据结构,实质就是一种可以进行二分查找的有序链表。跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。跳表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能。
跳表这种数据结构是由William Pugh 发明的,关于跳表的详细介绍可以参考论文:「Skip Lists: A Probabilistic Alternative to Balanced Trees」,论文中详细阐述了关于 skiplist 查找元素、删除元素、插入元素的算法伪代码,以及时间复杂度的分析。
跳表是一种随机化的数据结构,可以被看做二叉树的一个变种,它在性能上和红黑树、AVL 树不相上下,但是跳表的原理非常简单,目前在 Redis 和LevelDB 中都有用到。跳表的期望空间复杂度为O(n),跳表的查询,插入和删除操作的期望时间复杂度均为 O(logn)。
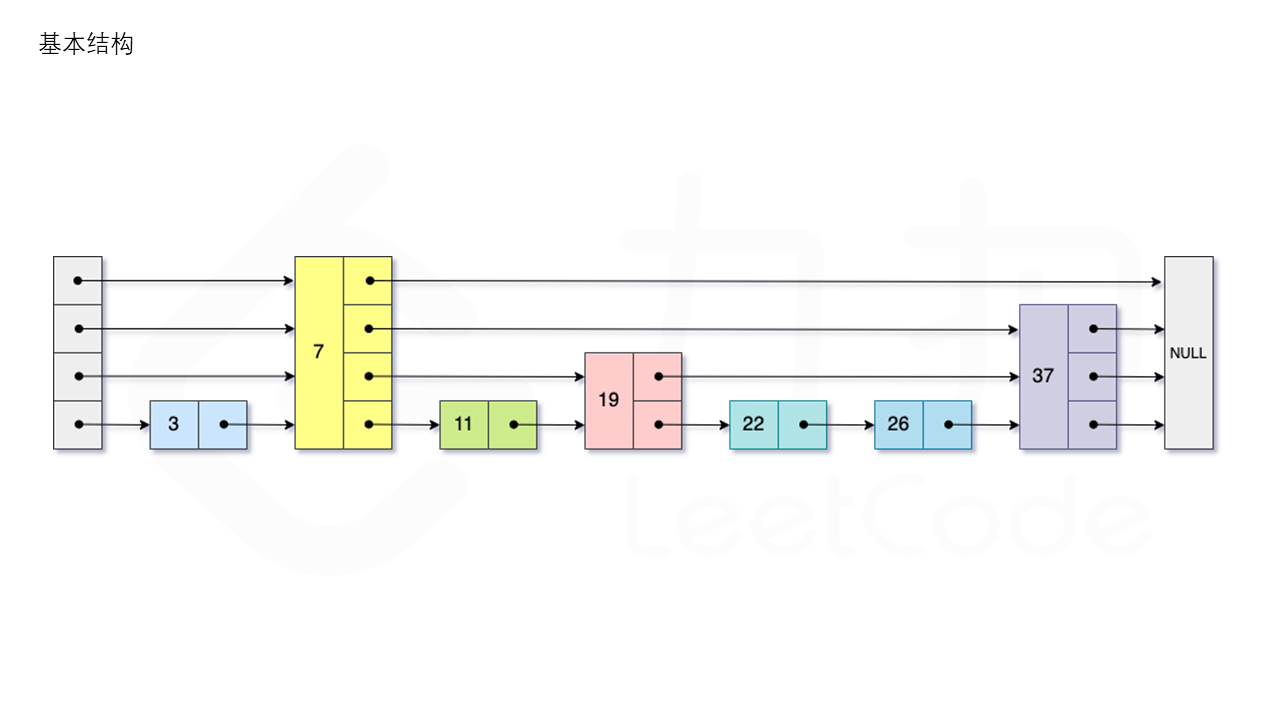
search:从跳表的当前的最大层数 level 层开始查找,在当前层水平地逐个比较直至当前节点的下一个节点大于等于目标节点,然后移动至下一层进行查找,重复这个过程直至到达第 1 层。此时,若第 1 层的下一个节点的值等于 target,则返回true;反之,则返回 false。
add:从跳表的当前的最大层数level 层开始查找,在当前层水平地逐个比较直至当前节点的下一个节点大于等于目标节点,然后移动至下一层进行查找,重复这个过程直至到达第 1 层。设新加入的节点为 newNode,我们需要计算出此次节点插入的层数 lv,如果 level 小于 lv,则同时需要更新level。我们用数组 update 保存每一层查找的最后一个节点,第 i 层最后的节点为 update[i]。我们将newNode 的后续节点指向 update[i] 的下一个节点,同时更新 update[i] 的后续节点为 newNode。
erase:首先我们需要查找当前元素是否存在跳表中。从跳表的当前的最大层数 level 层开始查找,在当前层水平地逐个比较直至当前节点的下一个节点大于等于目标节点,然后移动至下一层进行查找,重复这个过程直至到达第 1层。如果第 1层的下一个节点不等于 num 时,则表示当前元素不存在直接返回。我们用数组update 保存每一层查找的最后一个节点,第 i层最后的节点为 update[i]。此时第 i层的下一个节点的值为num,则我们需要将其从跳表中将其删除。由于第 i层的以 pp 的概率出现在第 i+1 层,因此我们应当从第 1 层开始往上进行更新,将num 从update[i] 的下一跳中删除,同时更新 update[i] 的后续节点,直到当前层的链表中没有出现 num 的节点为止。最后我们还需要更新跳表中当前的最大层数 level。
#define MAX(a, b) ((a) > (b) ? (a) : (b))
const int MAX_LEVEL = 32;
const int P_FACTOR = RAND_MAX >> 2;
typedef struct SkiplistNode {
int val;
int maxLevel;
struct SkiplistNode **forward;
} SkiplistNode;
typedef struct {
SkiplistNode *head;
int level;
} Skiplist;
SkiplistNode *skiplistNodeCreat(int val, int maxLevel) {
SkiplistNode *obj = (SkiplistNode *)malloc(sizeof(SkiplistNode));
obj->val = val;
obj->maxLevel = maxLevel;
obj->forward = (SkiplistNode **)malloc(sizeof(SkiplistNode *) * maxLevel);
for (int i = 0; i < maxLevel; i++) {
obj->forward[i] = NULL;
}
return obj;
}
void skiplistNodeFree(SkiplistNode* obj) {
if (obj->forward) {
free(obj->forward);
obj->forward = NULL;
obj->maxLevel = 0;
}
free(obj);
}
Skiplist* skiplistCreate() {
Skiplist *obj = (Skiplist *)malloc(sizeof(Skiplist));
obj->head = skiplistNodeCreat(-1, MAX_LEVEL);
obj->level = 0;
srand(time(NULL));
return obj;
}
static inline int randomLevel() {
int lv = 1;
/* 随机生成 lv */
while (rand() < P_FACTOR && lv < MAX_LEVEL) {
lv++;
}
return lv;
}
bool skiplistSearch(Skiplist* obj, int target) {
SkiplistNode *curr = obj->head;
for (int i = obj->level - 1; i >= 0; i--) {
/* 找到第 i 层小于且最接近 target 的元素*/
while (curr->forward[i] && curr->forward[i]->val < target) {
curr = curr->forward[i];
}
}
curr = curr->forward[0];
/* 检测当前元素的值是否等于 target */
if (curr && curr->val == target) {
return true;
}
return false;
}
void skiplistAdd(Skiplist* obj, int num) {
SkiplistNode *update[MAX_LEVEL];
SkiplistNode *curr = obj->head;
for (int i = obj->level - 1; i >= 0; i--) {
/* 找到第 i 层小于且最接近 num 的元素*/
while (curr->forward[i] && curr->forward[i]->val < num) {
curr = curr->forward[i];
}
update[i] = curr;
}
int lv = randomLevel();
if (lv > obj->level) {
for (int i = obj->level; i < lv; i++) {
update[i] = obj->head;
}
obj->level = lv;
}
SkiplistNode *newNode = skiplistNodeCreat(num, lv);
for (int i = 0; i < lv; i++) {
/* 对第 i 层的状态进行更新,将当前元素的 forward 指向新的节点 */
newNode->forward[i] = update[i]->forward[i];
update[i]->forward[i] = newNode;
}
}
bool skiplistErase(Skiplist* obj, int num) {
SkiplistNode *update[MAX_LEVEL];
SkiplistNode *curr = obj->head;
for (int i = obj->level - 1; i >= 0; i--) {
/* 找到第 i 层小于且最接近 num 的元素*/
while (curr->forward[i] && curr->forward[i]->val < num) {
curr = curr->forward[i];
}
update[i] = curr;
}
curr = curr->forward[0];
/* 如果值不存在则返回 false */
if (!curr || curr->val != num) {
return false;
}
for (int i = 0; i < obj->level; i++) {
if (update[i]->forward[i] != curr) {
break;
}
/* 对第 i 层的状态进行更新,将 forward 指向被删除节点的下一跳 */
update[i]->forward[i] = curr->forward[i];
}
skiplistNodeFree(curr);
/* 更新当前的 level */
while (obj->level > 1 && obj->head->forward[obj->level - 1] == NULL) {
obj->level--;
}
return true;
}
void skiplistFree(Skiplist* obj) {
for (SkiplistNode * curr = obj->head; curr; ) {
SkiplistNode *prev = curr;
curr = curr->forward[0];
skiplistNodeFree(prev);
}
free(obj);
}

















 308
308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









