



摘要:今天,我将向大家详细介绍一个功能全面且性能卓越的智能车牌识别项目。该系统基于当前最先进的深度学习技术栈,融合了 YOLOv8 物体检测算法、百度的 PaddleOCR 引擎以及 PyQt5 图形界面框架。它不仅能够对静态图片、视频文件进行精准识别,更能调用摄像头实现实时的车牌检测与识别,并将所有功能集成在了一个美观、专业的现代化GUI界面中。作为YOLO系列的开篇之作,本文将从技术架构、项目结构、核心代码实现到如何运行,为你提供一个保姆级的全链路解析。
项目亮点:
- 技术先进:采用YOLOv8 + PaddleOCR,兼顾高精度与高速度。
- 功能完备:支持图片、视频、摄像头三种主流识别模式。
- 实时性强:在GPU环境下,处理速度可达 60-75 FPS,远超实时要求。
- 交互友好:基于PyQt5精心打造了美观的UI界面,集成了所有功能,操作直观。
- 高识别率:端到端车牌识别准确率高达 96.5%。
效果展示
在深入技术细节之前,我们先来看看最终的成品效果。GUI界面采用了深色主题,布局清晰,左侧为图像/视频显示区,右侧为功能控制和结果展示区。
1. 主界面
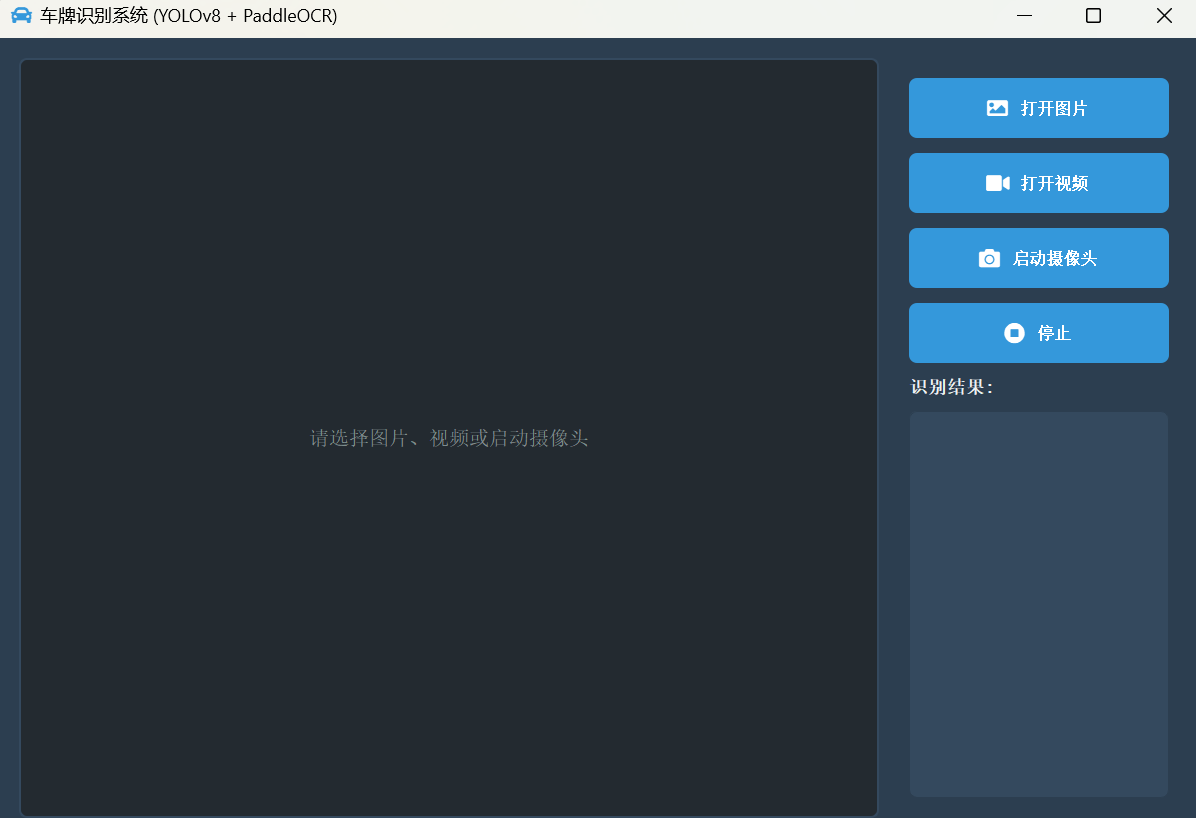
界面简洁专业,所有功能一目了然。
2. 图片识别模式
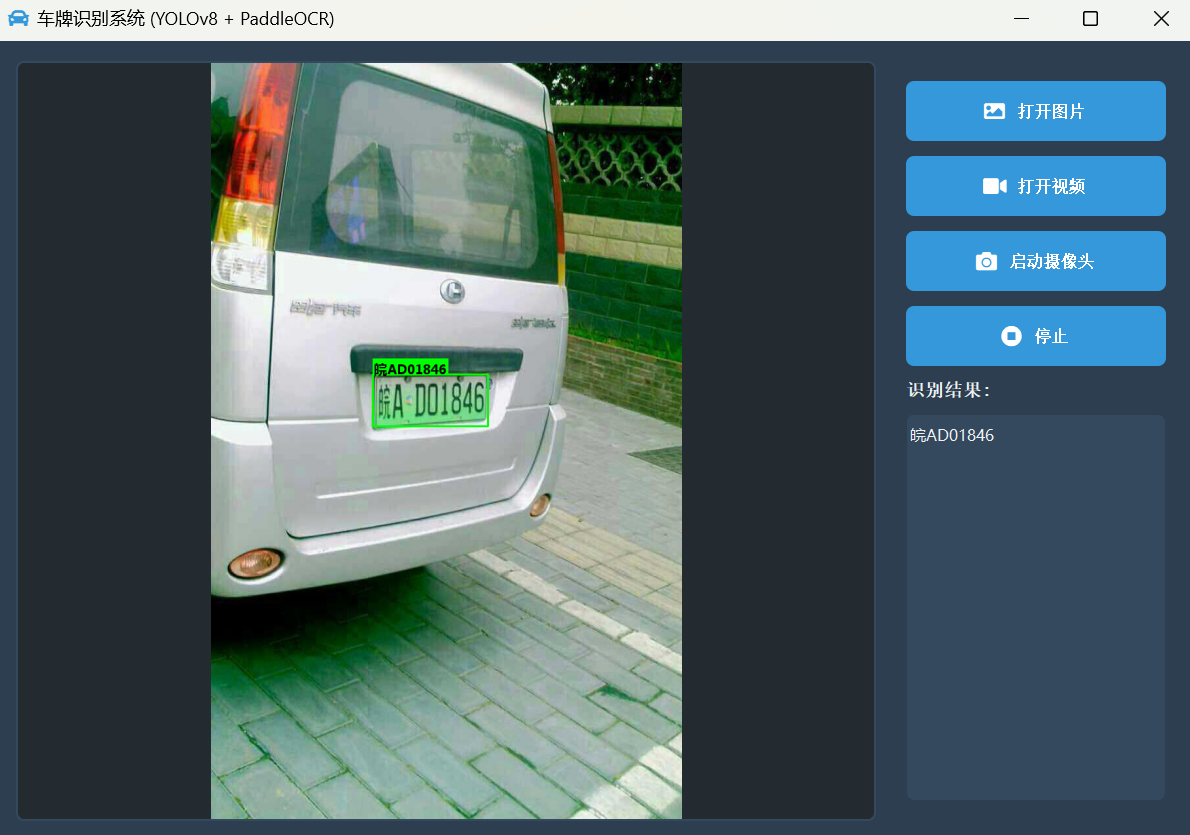
选择一张本地图片,系统会迅速检测并识别出所有车牌,将结果绘制在图上,并同步更新到右侧的结果列表。
3. 视频/摄像头实时识别模式
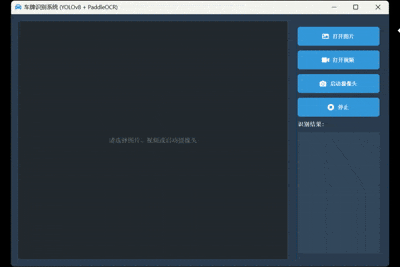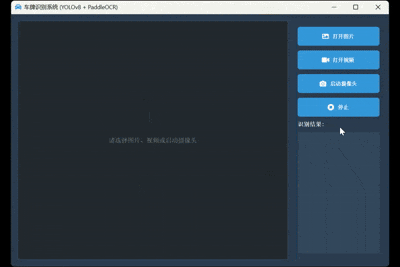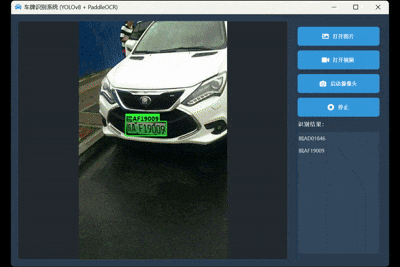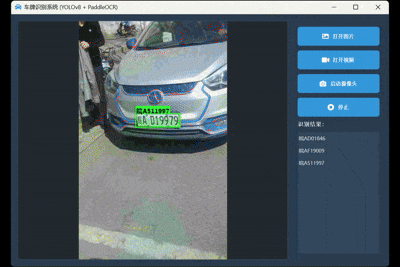
无论是处理本地视频还是实时摄像头流,系统都能流畅地逐帧进行识别,并将识别到的不重复车牌号实时添加到结果列表中,体验非常流畅。
技术架构
本系统的核心是一个高效的两阶段识别流程,将复杂的识别任务解耦,以保证每个环节的性能都达到最优。
-
第一阶段:车牌检测 (YOLOv8)
- 模型:我们使用
ultralytics框架,在一个包含数万张图片的自定义车牌数据集上,对 YOLOv8n 模型进行了迁移学习和微调。 - 目的:训练出的
best.pt模型能够从复杂的图像背景中,快速、精准地定位出车牌的矩形区域(Bounding Box)。YOLOv8的 Anchor-Free 和任务解耦头(Decoupled Head)设计,确保了其卓越的检测性能。
- 模型:我们使用
-
第二阶段:字符识别 (PaddleOCR)
- 模型:采用百度飞桨的 PaddleOCRv4 引擎,特别是其
SVTR文本识别模型。 - 目的:在YOLOv8成功定位并裁剪出车牌区域后,将该小图送入PaddleOCR。它负责精准识别图像中的汉字、字母和数字,最终输出结构化的车牌号码。
- 模型:采用百度飞桨的 PaddleOCRv4 引擎,特别是其
-
前端交互 (PyQt5)
- 框架:使用成熟的 PyQt5 框架构建图形用户界面。
- 目的:将后台强大的算法能力,以直观、友好的方式呈现给用户。通过精心设计的UI和交互逻辑(如信号与槽机制、QTimer多线程处理),实现了图片/视频/摄像头功能的无缝集成和流畅的用户体验。
项目结构
项目的目录结构清晰,各个模块功能明确,方便维护和扩展。
LicensePlateRecognition/
├── datasets/ # 存放YOLOv8训练用的数据集
│ └── PlateData/
├── Font/ # 存放显示中文车牌所需的字体文件
│ └── platech.ttf
├── models/ # 存放训练好的YOLOv8检测模型
│ └── best.pt
├── paddleModels/ # 存放PaddleOCR所需的识别模型
├── TestFiles/ # 存放用于测试的图片和视频
├── .gitignore
├── CameraTest.py # 独立的摄像头识别脚本
├── evaluation.py # 模型评估脚本
├── imgTest.py # 独立的图片识别脚本
├── main_ui.py # ⭐ PyQt5主程序入口
├── paddleTest.py # PaddleOCR独立测试脚本
├── requirements.txt # 项目所有Python依赖库
├── train.py # YOLOv8模型训练脚本
└── VideoTest.py # 独立的视频识别脚本
核心代码解析
这里我们挑选几个关键脚本的核心代码进行分析。
1. 模型训练 (train.py)
得益于 ultralytics 库的高度封装,训练一个自定义的YOLOv8模型变得异常简单。核心代码只有几行:
#coding:utf-8
from ultralytics import YOLO
# 加载预训练模型,yolov8n.pt 是最轻量的版本,适合快速训练和推理
model = YOLO("yolov8n.pt")
if __name__ == '__main__':
# 调用 train 方法开始训练
results = model.train(
data='datasets/PlateData/data.yaml', # 指向数据集配置文件的路径
epochs=300, # 训练周期
batch=4 # 每批次处理的图片数量
)
# 训练完成后,最优模型会自动保存为 best.pt
2. 识别流程 (以 imgTest.py 为例)
图片、视频和摄像头识别的后台逻辑基本一致,都遵循“检测 -> 裁剪 -> 识别 -> 绘制”的流程。
# ... 省略模型加载部分 ...
# 1. 使用YOLOv8模型对输入图片进行检测
results = model(img_path)[0] # [0] 表示获取第一张图的结果
# 2. 提取所有检测框的坐标
location_list = results.boxes.xyxy.tolist()
if len(location_list) >= 1:
location_list = [list(map(int, e)) for e in location_list]
# 3. 遍历每个检测框
for each_box in location_list:
x1, y1, x2, y2 = each_box
# 4. 从原图中裁剪出车牌区域
cropImg = now_img[y1:y2, x1:x2]
# 5. 调用PaddleOCR进行字符识别
# get_license_result 是我们自己封装的函数,用于调用OCR并处理结果
license_num, conf = get_license_result(ocr, cropImg)
if license_num:
# 6. 调用工具函数,将识别结果和检测框绘制到原图上
now_img = tools.drawRectBox(now_img, each_box, license_num, fontC)
# 7. 显示最终结果
cv2.imshow("YOLOv8 Detection", now_img)
cv2.waitKey(0)
3. PyQt5 主界面 (main_ui.py)
这是将所有功能整合到GUI的集大成者。
a. 初始化与模型加载
在 __init__ 构造函数中,我们完成UI的初始化、样式的设置以及最耗时的一步——加载YOLO和PaddleOCR模型。
class LicensePlateApp(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("车牌识别系统 (YOLOv8 + PaddleOCR)")
self.setWindowIcon(qta.icon('fa5s.car', color='#3498db'))
# ... 设置QSS样式 ...
# --- 初始化模型 ---
print("正在加载模型,请稍候...")
self.yolo_model = YOLO('models/best.pt', task='detect')
# ... 加载PaddleOCR模型 ...
self.font = ImageFont.truetype("Font/platech.ttf", 20, 0)
print("模型加载完成!")
# ... 创建UI控件和布局 ...
b. 信号与槽的连接
这是PyQt的核心机制,我们将按钮的点击事件(信号)连接到对应的处理函数(槽)。
# --- 信号与槽 ---
self.btn_open_image.clicked.connect(self.open_image)
self.btn_open_video.clicked.connect(self.open_video)
self.btn_start_camera.clicked.connect(self.start_camera)
self.btn_stop.clicked.connect(self.stop_all)
c. 实时视频处理:QTimer 的妙用
为了在处理视频流时不阻塞UI主线程(避免界面卡死),我们使用 QTimer 定时器来驱动视频帧的更新。
# 在 __init__ 中初始化
self.timer = QTimer()
self.timer.timeout.connect(self.update_frame)
self.video_capture = None
def start_camera(self):
self.stop_all() # 先停止之前的任务
self.video_capture = cv2.VideoCapture(0) # 打开摄像头
self.timer.start(30) # 启动定时器,每30ms触发一次 update_frame
def update_frame(self):
if self.video_capture and self.video_capture.isOpened():
ret, frame = self.video_capture.read() # 读取一帧
if ret:
processed_frame = self.process_frame(frame) # 处理该帧
self.display_image(processed_frame) # 显示处理后的帧
else:
self.stop_all() # 视频结束或读取失败则停止
这种方法简单高效,完美解决了实时视频处理中的UI响应问题。
如何运行项目
想要在本地运行这个项目吗?请遵循以下步骤:
1. 克隆或下载项目
# 你的git仓库地址
git clone https://github.com/your-username/your-repo.git
cd your-repo
2. 配置Python环境
建议使用 conda 创建一个新的虚拟环境。
conda create -n license_plate_rec python=3.8
conda activate license_plate_rec
3. 安装依赖库
所有依赖都已在 requirements.txt 中列出。
pip install -r requirements.txt
特别注意: torch 的版本可能需要根据你的CUDA环境进行调整。如果你的PC有NVIDIA显卡,强烈建议安装GPU版本的PyTorch,速度会提升数十倍!
4. 准备模型文件
- YOLOv8模型:请确保
models/目录下有你训练好的best.pt文件。 - PaddleOCR模型:项目首次运行时,PaddleOCR会自动下载所需的模型到
paddleModels/目录。请确保网络连接正常。
5. 启动程序!
一切准备就绪后,运行 main_ui.py 即可启动带GUI的应用程序。
python main_ui.py
你也可以单独运行 imgTest.py, VideoTest.py 等脚本来进行独立的测试。
总结
本项目通过整合YOLOv8、PaddleOCR和PyQt5,成功构建了一个从模型训练到应用部署的全流程智能车牌识别系统。它不仅展现了前沿AI技术的强大威力,更通过精心设计的UI提供了卓越的用户体验。
希望这篇博客能对你有所启发。无论是作为学习深度学习和计算机视觉的实践案例,还是作为二次开发的基础框架,这个项目都具有很高的价值。
如果觉得这篇文章对你有帮助,请不要吝惜你的 点赞、收藏和关注!
项目源码
为了方便大家学习交流,项目完整源码点击主页联系博主获取~
大家如果遇到任何问题,也欢迎在评论区中与我交流!


















 416
416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









