




多头自注意力机制 (Multi-Head Self-Attention)
为什么要使用多头注意力?
在基础的自注意力机制中,我们通常使用 单个注意力头(single head)来对整个序列进行建模。这种方式存在一定的局限性:
-
单一视角建模:每个位置的表示只能从一个角度去理解上下文信息,可能忽略了其他维度的联系;
-
难以捕捉复杂关系:语言中包含多层次的信息,比如语法结构、语义关联、位置依赖等,而单头注意力难以同时有效建模这些不同层面的关系。
这与词向量编码中的一个基本思想类似:我们希望从多个角度去理解和表示一个词或序列的信息。因此,引入多头注意力的机制,使得模型能够并行地从多个子空间对信息进行建模和关注,有效提升了模型对上下文的理解能力。
多头注意力机制的数学表达
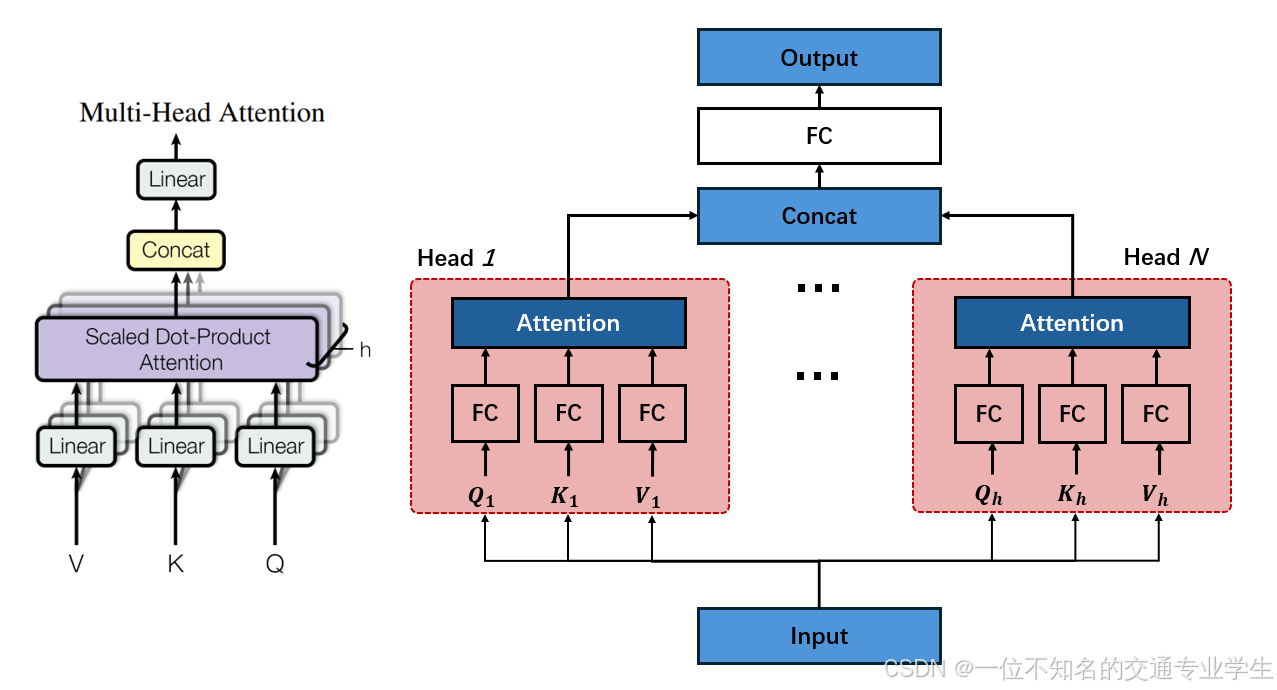
-
输入矩阵:给定一个矩阵 X ∈ R n × d X \in \mathbb{R}^{n \times d} X∈Rn×d
-
设置注意力头数量 h h h:我们将注意力机制拆分为 h h h 个并行的头(head),每个头能学习不同的表示子空间。
-
每个头的维度:为了保证拼接后的维度与输入保持一致,设每个头的表示维度为 d k = d / h d_k = d / h dk=d/h,注意: h h h 必须能整除 d d d。
-
线性变换生成 Q , K , V Q, K, V Q,K,V 矩阵:对输入 X X X 分别乘以不同的参数矩阵(共享 X X X,但线性层不共享),得到 h h h 组 Q i = X W i Q , K i = X W i K , V i = X W i V Q_i=XW_i^Q,K_i=XW_i^K,V_i=XW_i^V Qi=XWiQ,Ki=XWiK,Vi=XWiV,其中 i = 1 , 2 , … , h i=1,2,…,h i=1,2,…,h,每组 Q i , K i , V i ∈ R n × d k Q_i, K_i, V_i \in \mathbb{R}^{n \times d_k} Qi,Ki,Vi∈Rn×dk
-
每个头分别计算注意力:
h e a d i = A t t e n t i o n ( Q i , K i , V i ) = s o f t m a x ( Q K T d k ) head_{i} = Attention(Q_i, K_i, V_i) = softmax(\frac{QK^T}{\sqrt{d_k}}) headi=Attention(Qi,Ki,Vi)=softmax(dkQKT) -
拼接所有注意力头的输出:将每个头的输出拼接在一起,得到维度为
C o n c a t ( h e a d 1 , h e a d 2 , … , h e a d h ) ∈ R n × ( h × d ) Concat(head_{1},head_{2},\dots,head_{h}) \in \mathbb{R}^{n \times (h\times d)} Concat(head1,head2,…,headh)∈Rn×(h×d) -
输出线性变换:拼接结果通常再经过一个线性变换,使得输出维度与输入保持一致:将维度从 n × ( h × d ) n \times (h\times d) n×(h×d) 变为原来的 n × d n \times d n×d
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , h e a d 2 , … , h e a d h ) W O MultiHead(Q,K,V) = Concat(head_{1},head_{2},\dots,head_{h})W^O MultiHead(Q,K,V)=Concat(head1,head2,…,headh)WO
多头注意力机制通过将注意力计算拆分为多个并行的子空间,使模型能够从不同的角度和层次理解序列中各位置之间的关系。每个头专注于捕捉某种类型的特征(如语义关联、句法结构或位置依赖),拼接后统一映射回原始空间,从而提升了模型表达能力和对上下文的理解深度。相比单头注意力,多头注意力在处理复杂语言结构和长距离依赖时表现更为出色,但是会有更大的计算量。


















 5226
5226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









