




 本文介绍了在进行性能测试时,使用CSV数据文件在分布式环境中可能出现的问题,即多台机器同时取相同值。提出了三种解决方案:1) 打乱CSV文件行顺序;2) 添加等待时间;3) 随机开始行。还讨论了混合场景的测试需求,强调了在多线程组中使用JMeter属性传递参数的重要性,并提供了动态属性的设置和使用方法,以及混合场景的设计策略。
本文介绍了在进行性能测试时,使用CSV数据文件在分布式环境中可能出现的问题,即多台机器同时取相同值。提出了三种解决方案:1) 打乱CSV文件行顺序;2) 添加等待时间;3) 随机开始行。还讨论了混合场景的测试需求,强调了在多线程组中使用JMeter属性传递参数的重要性,并提供了动态属性的设置和使用方法,以及混合场景的设计策略。
补充
做性能测试时,很多人,习惯用csv数据文件设置这个功能。
csv文件,默认的时候,从上往下循环取值 。如果你用一台发起方电脑,这个是没有问题的。
但是,我们在企业中,会有使用多台机器,构成分布式方式来做性能测试--------脚本中,使用从csv文件设置,就会出现一个问题
- 问题:
- 多台助攻机器,csv文件取值,都是从上往下循环取值。----那么,多台机器的时候,就会同时取相同的值。
- 在项目中,经常会出现,最后一个是有效的,而前面的都无效
- 多台助攻机器,csv文件取值,都是从上往下循环取值。----那么,多台机器的时候,就会同时取相同的值。
- 解决:
-
解决办法1: 把每台机器上的csv文件中的行的顺序打乱
- linux系统: 在每台助攻电脑上 shuf 源文件 -o 新文件
-
解决方法2:每台分布式时间建一个等待时间
- 线程组中,
使用一个随机延迟时间
- 线程组中,
-
解决方法3:每台机器csv文件取值,行不从固定第1行开始,而是随机行
- 下载插件:
Random CSV Data Set Config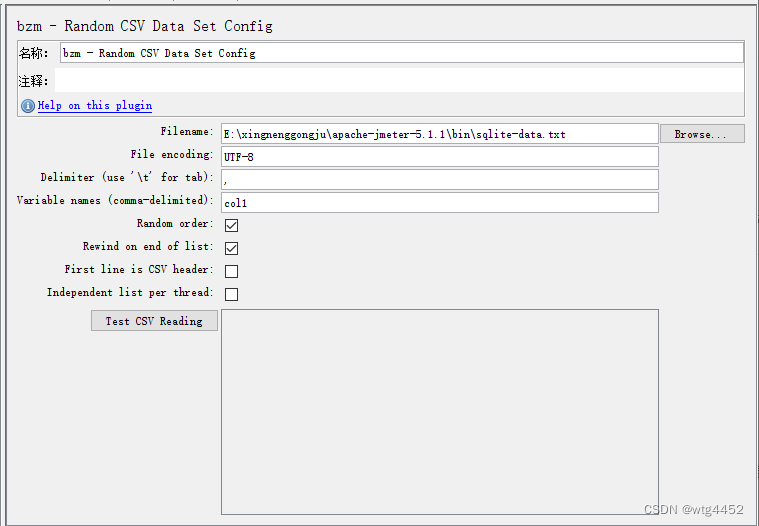
- 或者 下载插件:
Extended CSV Data Set Config
- 下载插件:
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1283
1283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









