




 本文介绍了正则表达式的常用符号及其用法,并通过实例详细解释了如何利用findall方法进行模式匹配,包括如何处理括号内的匹配结果及非捕获组的应用。
本文介绍了正则表达式的常用符号及其用法,并通过实例详细解释了如何利用findall方法进行模式匹配,包括如何处理括号内的匹配结果及非捕获组的应用。
正则表达式的学习
可以去regex 页面测试学习
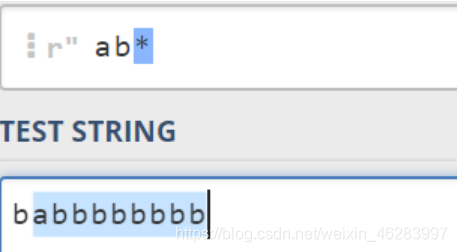
- *匹配0个或者多个;‘+’匹配一个或者多个;?匹配0个或一个注意是贪婪的。
*就表示非贪婪的,他匹配尽可能多
*?就表示非贪婪的,他匹配尽可能少
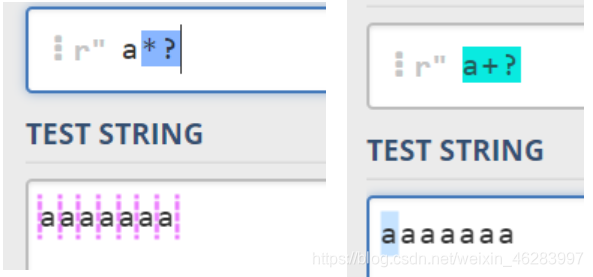
-
例如说匹配一个日期
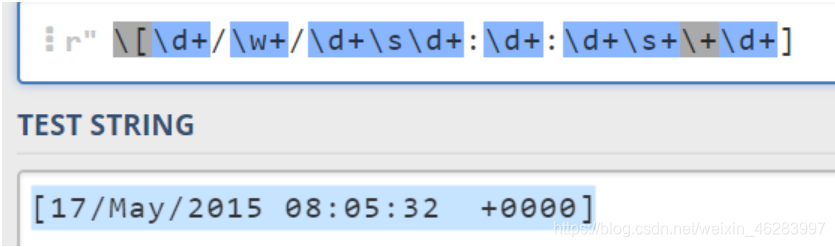
-
注意转义字符的使用:因为如果不加转义字符,[有可能有歧义,可能匹配的是[01],表示匹配0或者1,而加了转义符号,就代表它原来的含义
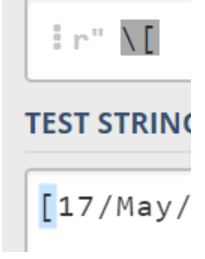
-
匹配多种情况(选择匹配):
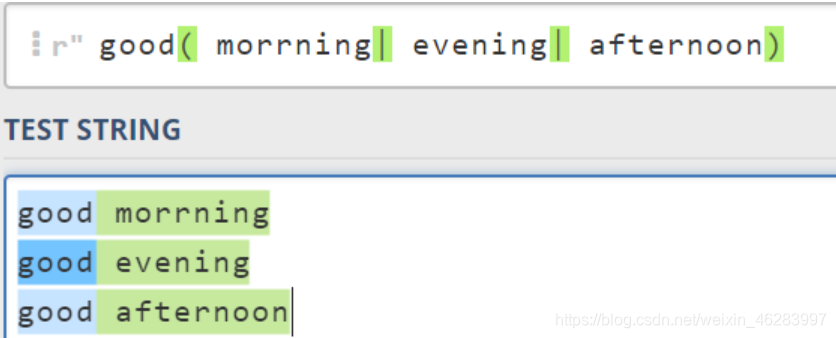
-
findall方法: 列出字符串中模式的所有匹配项
正则中没有括号时,返回的是 list,list的元素是 str ;
正则中有括号时,返回的是 list,list的元素是 tuple ,tuple 中的各项对应的是括号中的匹配结果;
import re input2=input("please input:") b=re.findall(r'\w+\.(jpg|jpeg|gif|bmp)',input2) print(b)C:/Users/LENOVO/....匹配.py please input:abc.jpg ['jpg']此时我们发现匹配到的就只有jpg,按道理来讲它应该整个式子abc.jpg都可以匹配的到。这是因为()的作用是将()内部的内容当作一个子模式(一个整体)来对待,所以就返回的值是一个元组,就返回()内匹配到的东西。
-
import re
input2=input("please input:")
b=re.findall(r'(\w+\.(jpg|jpeg|gif|bmp))',input2)
print(b)
please input:abc.jpg
[('abc.jpg', 'jpg')]
而单我们在外面也加一个(),这样findall返回的就是俩层()内匹配的值,第一个()内匹配到的是一个整体abc.jpg,第二个()内匹配到的是jpg
那如果我们只想匹配外面的整体呢:我们可以使用(?:。。。。)匹配但不捕获该匹配的子表达式
import re
input2=input("please input:")
b=re.findall(r'(\w+\.(?:jpg|jpeg|gif|bmp))',input2)
print(b)
please input:abc.jpg
['abc.jpg']
此时就只有整体了。

















 2962
2962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









