




 CSPNet通过独特的部分密集块和部分过渡层设计,有效减少计算量并增强CNN学习能力,实验证明其能显著降低计算成本同时保持甚至提高模型精度。
CSPNet通过独特的部分密集块和部分过渡层设计,有效减少计算量并增强CNN学习能力,实验证明其能显著降低计算成本同时保持甚至提高模型精度。
文章目录
前言
YOLOv4中所采用的的backbone
发表
CVPR2020
源代码
https://github.com/WongKinYiu/CrossStagePartialNetworks
论文动机
作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的。CSPNet通过将梯度的变化从头到尾地集成到特征图中,在减少了计算量的同时可以保证准确率。
论文贡献与成果
加强CNN学习能力
消除计算瓶颈
降低内存成本
模型方法说明
1.DenseNet与CSPNet模型
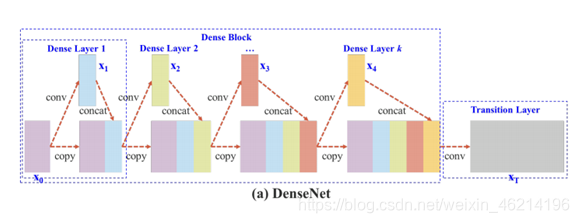
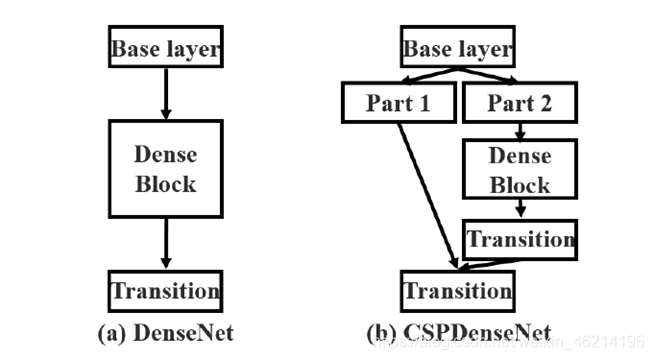
上图是DenseNet的一个阶段,包含 一个dense block和一个transition层,每个dense block由k个dense layers组成,多个dense layers串联,串联后的结果缩为transition层的输入。
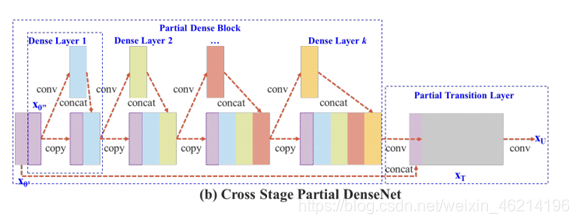
CSPNnet全名为Cross Stage Partial DenseNet,它的每个阶段包含一个partial dense block和一个partial transition layer,在pairial dense block中,将输入的底层特征图分为了两部分,一部分直接连接到终点,另一部分经过一个dense block再与第一部分汇合concatenated。汇合后再经过一个transition layer。
2.DenseNet与CSPNet的前馈传递与权重更新
在DenseNet中,为串联输入输出,因此下一个前馈传递的输入为前一个的输出。
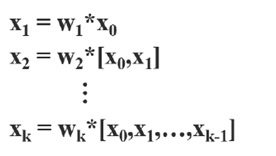
在反向传播更新权重时,可以看到到大量的梯度信息被重复使用,其中f为权重更新函数,gi为传播到第i个dense layers的梯度。
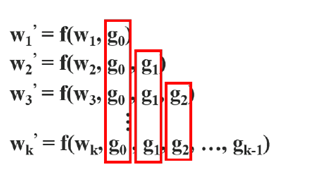
在CSPNnet中,将输入的特征图分为了x0’和x0’’两部分,x0’’经过dense block得到xk,经过transition layer得到xT。在与x0’部分相连后得到xU。
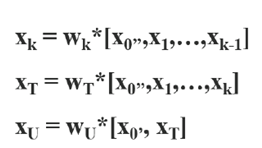
在权重更新时,可以看到两部分都是单独集成的,所以在更新时,两边都不包含属于其他边的重复梯度信息。
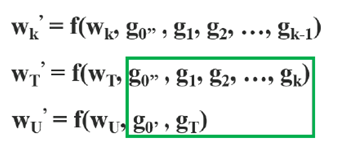
总之,CSPDenseNet保留了DenseNet的特征复用特性的优点,但同时通过截断梯度流,防止了过多的重复梯度信息。这一思想通过设计分层特征融合策略并用于partial transition层来实现。
3.CSPNet各个阶段的目的
Partial Dense Block:
1)增加梯度路径,分割再合并可以将梯度路径的数量变为原来的两倍
2)平衡各层之间的计算量
3)减少内存
Partial Transition Layer:
最大限度的提高梯度的组合差异,是一种分层特征融合机制,它采用截断梯度流的策略来防止不同层学习重复的梯度信息。
4.EFM机制
待补
5.CSPNet的变体
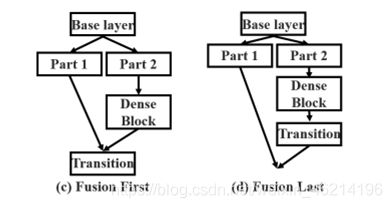
CSP(fusion first)是指将两支路生成的特征图进行concatenate ,然后再进行transition操作。如果采用这种策略,将会reused大量的梯度信息。
至于CSP(fusion last)策略,dense block的输出会经过transition层,然后与来自第1部分的特征图做concatenation。如果采用CSP(fusion last)策略,由于梯度流被截断,梯度信息将不会被重用。
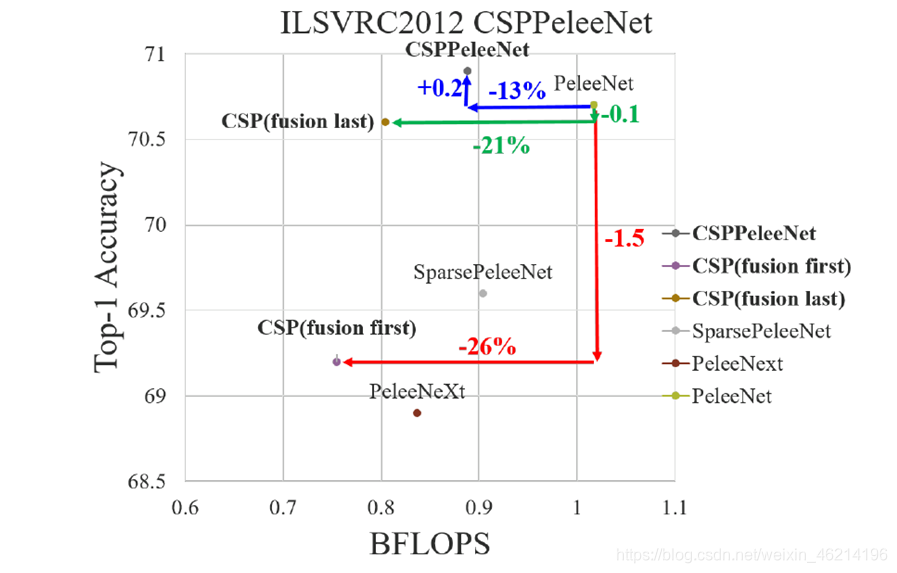
如上图,如果采用CSP(fusion last)策略进行图像分类,计算成本明显下降,但top-1的准确率仅下降0.1%。 另一方面,CSP(fusion first)策略确实有助于计算成本的大幅下降,但top-1的准确率明显下降了1.5%。
从图中可以看出,如果能够有效地减少重复的梯度信息,网络的学习能力将得到很大的提升。
实验
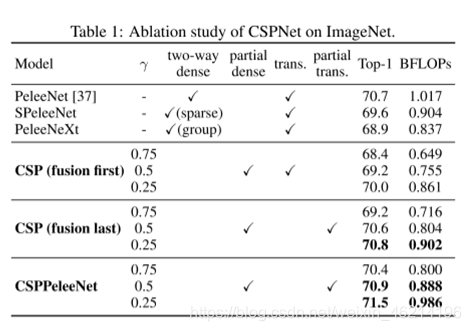
数据集:ImageNet的图像分类数据集
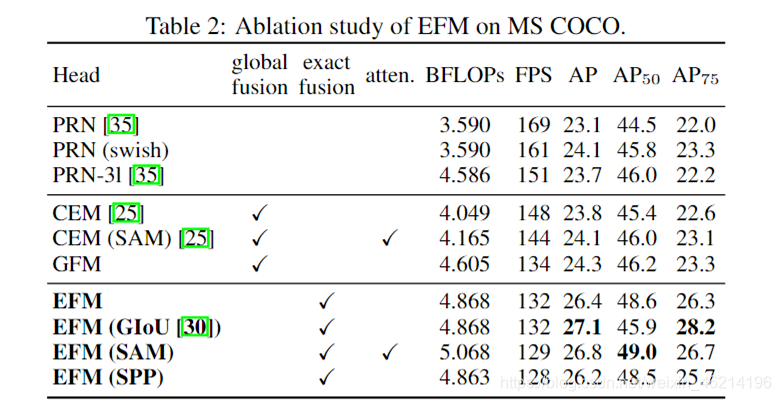
数据集:MS COCO对象检测数据集
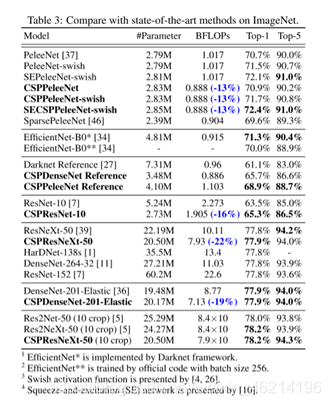
实验结果证实,无论是基于ResNet的模型、基于ResNeXt的模型,还是基于DenseNet的模型,当引入CSPNet的概念后,计算负荷至少降低10%,精度要么保持不变,要么提升。
待补
总结
CSPNet同样可以用于ResNet和ReNetX,减少计算量,加强CNN学习能力,降低内存成本。

















 943
943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









