







目录
简单快速再整理一下这些数据结构的内容
先上图
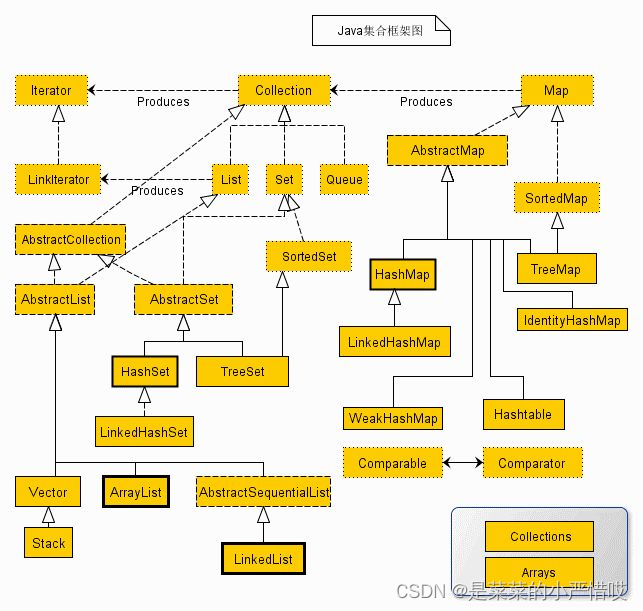
一部分信息可以参考我这篇文章
 https://blog.youkuaiyun.com/weixin_46097842/article/details/115025842
https://blog.youkuaiyun.com/weixin_46097842/article/details/115025842arraylist
底层为数组,默认容量为10,扩容一次为1.5倍,扩容时创建新数组,使用拷贝的方式复制数据,查询快,但,增删慢
add方法默认插入最后位置
实现了coloneable与serializable,支持拷贝和序列化,重写clone方法、方法内容默认调用父类的clone方法

拷贝分为浅拷贝和深拷贝
浅拷贝:基础类型的变量拷贝之后是独立的,不会随着源变量变动而变,引用类型拷贝的是引用地址,拷贝前后的变量引用同一个堆中的对象,String类型拷贝之后也是独立的
深拷贝:变量的所有引用类型变量(除了String)都需要实现cloneable,clone方法中,引用类型需要各自调用clone,重新赋值,当然,数组可以直接调用clone方法
这块补充一下java的传参,java对于基础类型和引用类型的传参是不一样的,java在传参时,是将变量复制一份,然后传入方法体去执行,复制的是栈中的内容
对于基础类型,复制的变量名和值,值变了不影响源变量
对于引用类型,复制的是变量名和引用地址,对象变了,会影响源变量的值,这一点如果用C这种的,指针,是不是也明白了
而String算比较特殊,是不可变对象,重新赋值时,会在常量表新生成字符串,如果有的话,会直接取它地址,将新字符串的引用地址赋值给栈中的新变量,因此源变量不会受影响
至于所谓的序列化与反序列化,其实序列化就是把对象转换为实际可存储格式,反之,就是反序列化
linkedlist
底层用链表实现,增删快,查找慢,链表有一个一个节点组成,每个节点会记录当前节点数据和下一个节点信息,在物理上不是连续的,这一点和数组不同,非连续非顺序的存储机构
注意哦,linkedlist是个双向链表,所以它还会存储上一个节点的信息
和arraylist对比来说,如果没有指定容量,linkedlist快,因为arraylist有扩容问题
hashset
底层是hashmap,value为object
没什么可说的
hashmap
k-v形式,键值对,key可以存null,key不可重复,采用数组、链表、红黑树实现
这其中涉及到一个算法,叫哈希算法,也叫散列算法,把任意长度的值通过哈希算法变换为固定长度的值/地址,通过这个地址进行访问的数据结构,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度,哈希算法具有幂等性,同样的入参,执行结果相同
但,使用哈希算法也会遇到一个问题,那就是哈希冲突,关于这点,采用链表解决即可,相同哈希值,那就挂链表往后挂
这一点,从hashmap源码也能看出来

在jdk1.8之前,hashmap采用头插法,1.8之后,采用尾插法
头插法和尾插法的区别:
如字面意思,头插法和尾插法分别在链表的头部和尾部插入新来的要添加的数据
但,头插法会引起死循环
假设已有一个结构,存储了两个元素A和B,它们在一个链表上,顺序为A指向B
线程1和线程2,同时进行操作,现在容量不足,线程1进行扩容,但,它申请了容量,没来得及处理数据,线程2得到了CPU执行权,并且,线程2在这期间还完成了扩容的全部流程
也就是说,现在结构由原来的A指向B,变为了B指向A,本质上他们所在位置的地址值是不变的,只是变了值而已
也就是说,假设第一个位置是x1,第二个位置是x2
线程1拿到的结果是 A_x1指向B_x2,线程2拿到的结果是B_x1指向A_x2
出现了A指向B,B指向A的问题
hashmap是这么存的,但如何取呢?其实也和存一样,算哈希值,拿到以后对比,是不是一样的,如果存了不止一个,那就挨个找
提问:已经实现了hashmap的存取,为何还要在jdk1.8引入红黑树
回答:为了加快查找速度,当链表过长,查找速度会很低
jdk8不是用红黑树代替链表,而是一种增加补充,jdk1.8也不是上来就是红黑树,它是链表长度大于8之后,左右旋为红黑树,数量小于6,就从红黑树退化为链表,红黑树是一颗平衡树
hashmap默认容量是16,加载因子0.75,也就是说,插入到第12个元素的时候,就会出发hashmap的扩容,以下为示意图,受限于屏幕,将就着看叭。。。。。
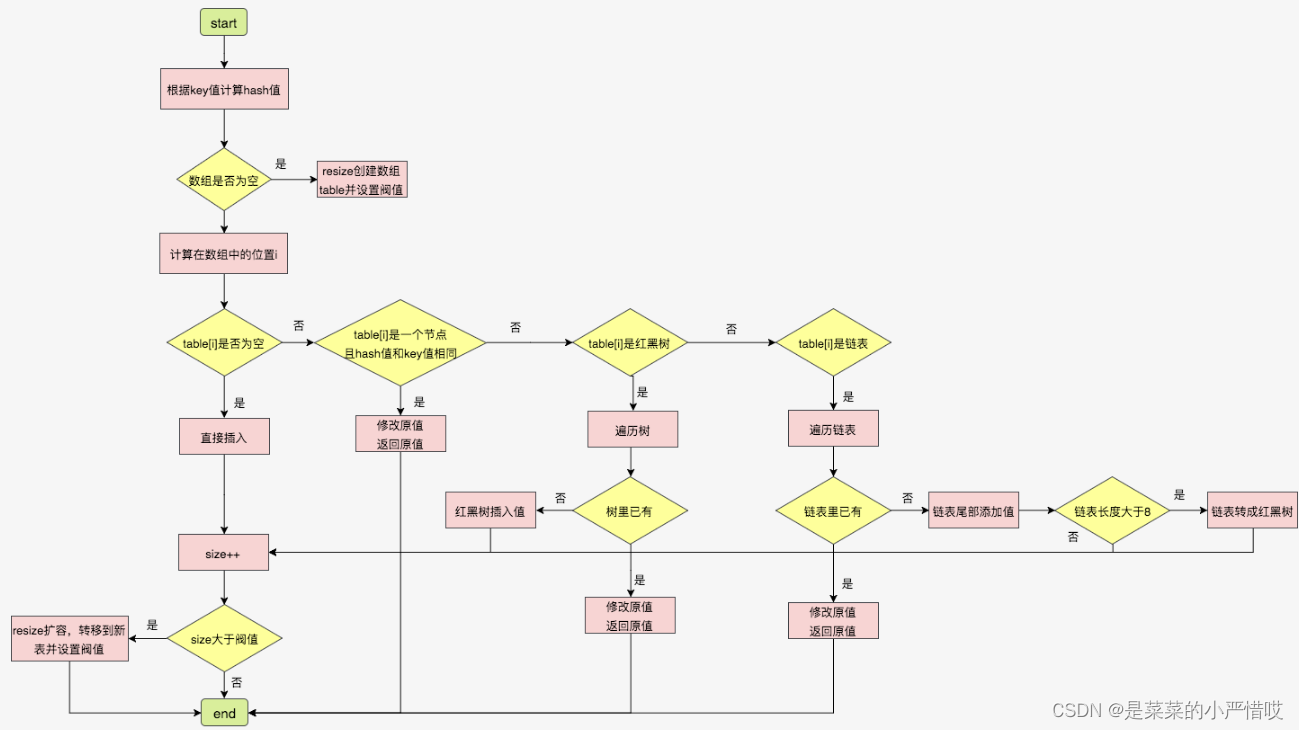
注意,key相同的话,value会覆盖
concurrenthashmap
这是一个并发安全的map,hashtable虽然也是线程安全的,但hashtable性能不高,hashtable的put方法被synchronized修饰
底层采用数组、链表、红黑树,内部有大量的CAS操作,并发控制使用synchronized和cas来操作
concurrenthashmap是个懒加载,put的时候才会判断容量,为0才会初始化,初始化的时候第一步会判断是否已经出实话,如果没有,采用CAS方法扩容,这一点和hashmap不同,hashmap是构造方法加载容量
concurrenthashmap的put方法,如果是数组,采用CAS方法赋值,如果是链表或者红黑树,使用synchronized,锁粒度很小,在头节点或红黑树上
1.7的时候使用桶锁,也叫分段锁,锁住整个哈希值对应的段,锁的是数组一部分的所有,数组节点及节点挂的链表,如果分段很多,且加锁的段不连续,内存空间浪费会比较多,而且如果某个分段比较大,会影响效率,耽误时间,所以在jdk1.8弃用了



















 550
550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









