







 本文档详细介绍了如何在CentOS7环境下搭建Hadoop 3.3.1全分布式集群。内容包括网络配置、主机名与IP映射、SSH无密码登录、集群配置以及启动检查。特别提示,Hadoop 3.3.1版本的Web UI端口为9870,不同于旧版本的50070。
本文档详细介绍了如何在CentOS7环境下搭建Hadoop 3.3.1全分布式集群。内容包括网络配置、主机名与IP映射、SSH无密码登录、集群配置以及启动检查。特别提示,Hadoop 3.3.1版本的Web UI端口为9870,不同于旧版本的50070。
参考了林子雨的教程Hadoop集群安装配置教程_Hadoop3.1.3_Ubuntu_厦大数据库实验室博客
但他使用的是ubuntu 的,在一些方面和centos还是不同
Hadoop的安装同样可以参考:Hadoop安装教程_伪分布式配置_CentOS6.4/Hadoop2.6.0_厦大数据库实验室博客
Hadoop3.1.3安装教程_单机/伪分布式配置_Hadoop3.1.3/Ubuntu18.04(16.04)_厦大数据库实验室博客e
但是centos版本的太过时了,我同样通过查询学习,整理了一份
使用的软件:
vm15
centos7
hadoop3.3.1
jdk1.8.0
准备工作:
1.选定一台作为master,需要在master创建hadoop用户,安装ssh服务端,安装java环境,安装hadoop并且完成配置
2.这里我是选择一主二从,在两个slave上创建hadoop用户,安装SSH服务端,安装java环境
开始:
1.网络配置:需改为桥接模式
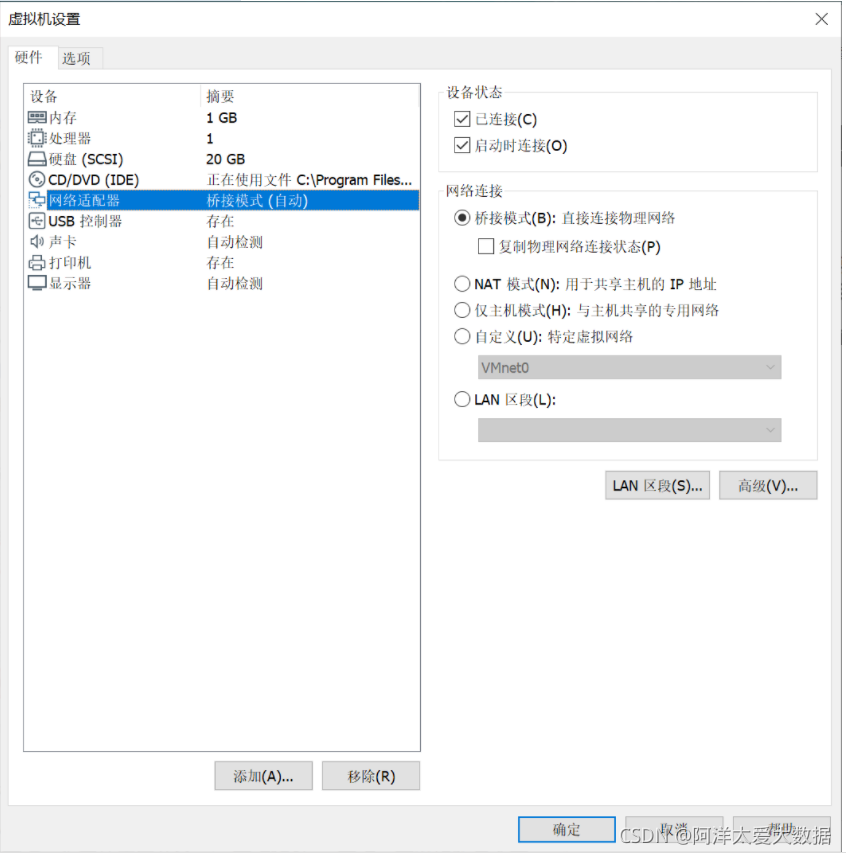
并且查看三台机子的的MAC地址是否一样,一样的话需要随机生成以至不一样
2.修改主机名:
Centos7通过hostname来查看主机名,而通过hostnamectl set-hostname slave来修改主机名,然后重启即可
3.修改IP映射:
输入以下命令:
sudo vim /etc/hosts
在加如映射关系前先通过ifconfig来查到三个主机的IP地址,查到后建立如下映射关系:
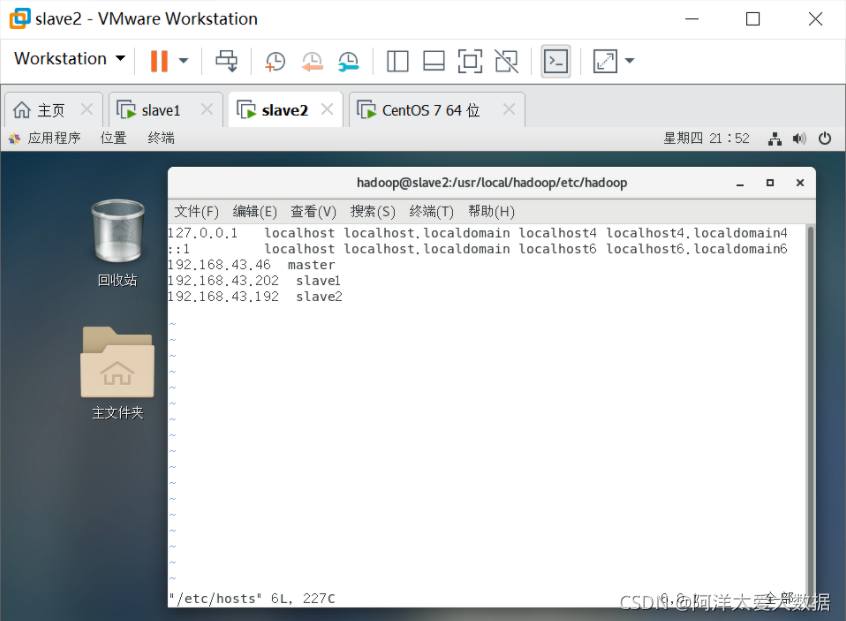
同样的,在两个slave1和slave2里面同样进行配置,配置完成后重新启动slave节点的Linux系统
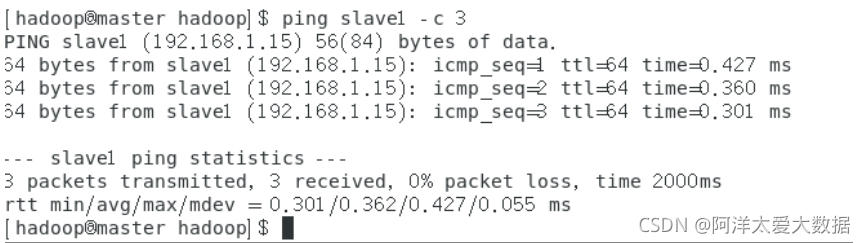
4.完成后还需要检查是否顺利配置:
在master节点上:
$ ping slave1 -c 3 #只会ping三次 $ ping slave2 -c 3
在两个slave节点上:
$ ping master -c 3
如果出现如下结果,则ping通了
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1602
1602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











