




目录
涉及六个主要的函数
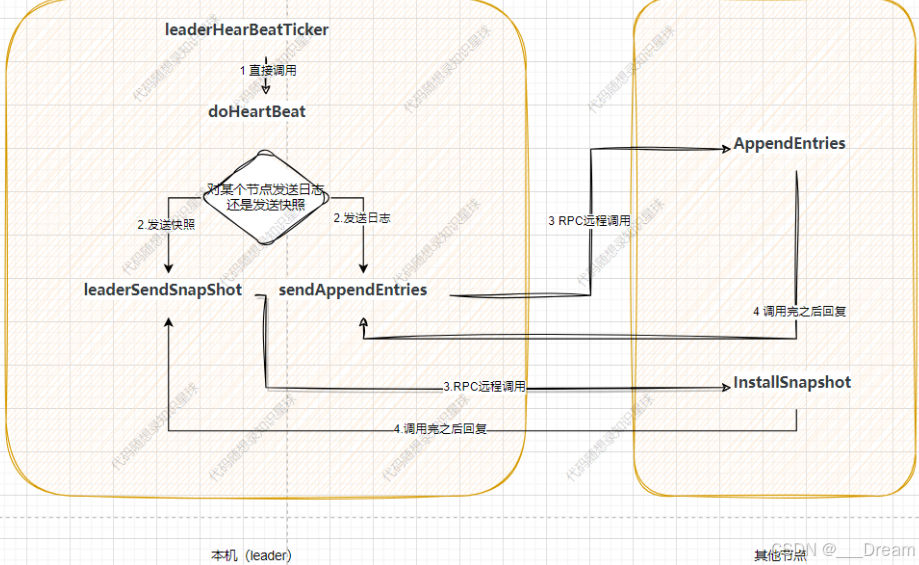
由于这个项目作者的代码风格很统一,所以其实这篇和上篇有很多相似的地方,唯一区别就是这篇在doHeartBeart中做出了是发送日志还是发送快照的抉择,假如把发送日志/快照分为一组的话,其实跟上一篇选leader很像,他们甚至代码逻辑也很相似:
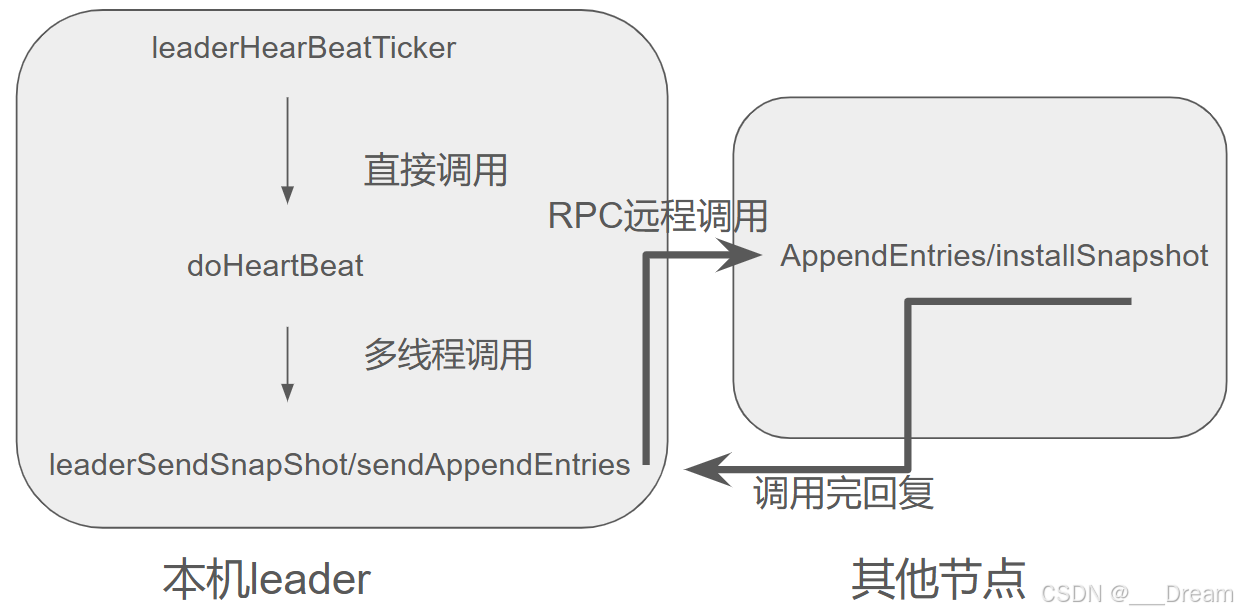
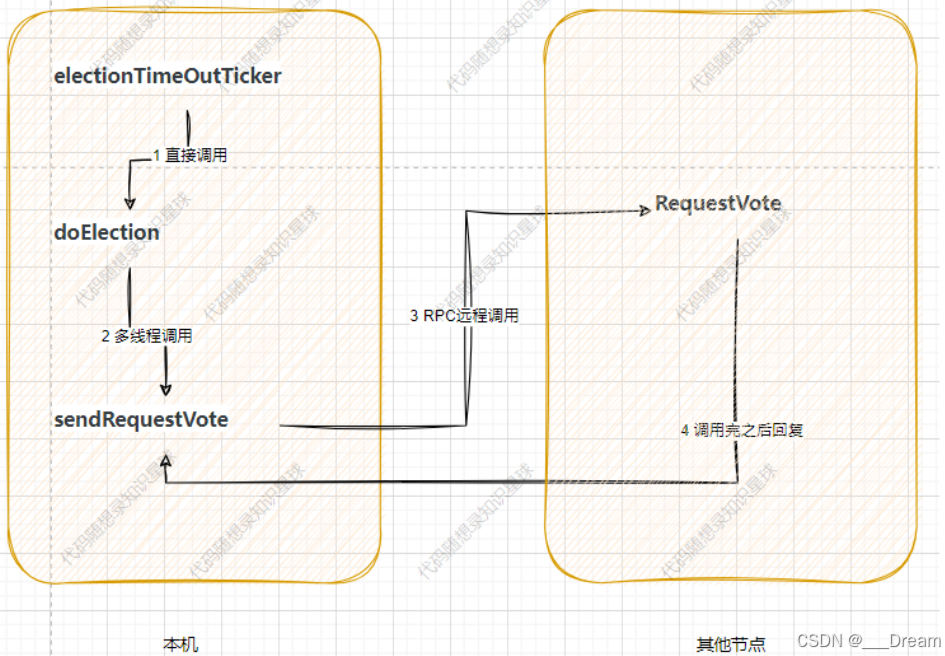
上面两张图中,第一张是我重画的日志复制以及心跳流程图,第二张是我从上一篇blog偷过来的,,很像吧,这一篇如果讲6个函数的话会很长,复习和学习起来都会很吃力,所以我只学了日志复制...感谢理解
leaderHearBeatTicker
leaderHearBeatTicker这个函数的目的是负责查看是否该发送心跳了,如果该发起就执行doHeartBeat。
代码逻辑可以看选举的Tricker,非常类似
核心仍然是计算合适的睡眠时间,这里是计算下一次心跳之前的合适睡眠时间,怎么计算呢?合适的睡眠时间由:
由一个配置参数提供的心跳超时HeartBeatTimeout + 上一次心跳或者是相关操作重置时间m_lastResetHearBeatTime - 现在时间nowTime得到
与选举不同的是m_lastResetHearBeatTime 是一个固定的时间,提前设置好的参数,而选举超时时间是一定范围内的随机值。
如果睡眠时间小于1ms,这几乎意味着下次发送心跳几乎立即执行。这种情况下,继续执行而不实际休眠可能会导致频繁的无效循环,所以睡眠时间至少1ms,当小于1ms的时候粗暴地重置为1ms就好
直接给出整个的代码:
void Raft::leaderHearBeatTicker() {
while (true) {
auto nowTime = now();
m_mtx.lock();
auto suitableSleepTime = std::chrono::milliseconds(HeartBeatTimeout) + m_lastResetHearBeatTime - nowTime;
m_mtx.unlock();
if (suitableSleepTime.count() < 1) {
suitableSleepTime = std::chrono::milliseconds(1);
}
std::this_thread::sleep_for(suitableSleepTime);
if ((m_lastResetHearBeatTime - nowTime).count() > 0) { //说明睡眠的这段时间有重置定时器,那么就没有超时,再次睡眠
continue;
}
doHeartBeat();
}
}doHeartBeat
个人认为doHeartBeat实现了发送心跳以及将需要复制的日志条目放进entries列表
先不管代码,从blog的第一张图看你会发现,doHearthBeat需要判断是发快照还是发日志
看图可能产生的疑问我以问答的形式在块里指出:
Q:快照的概念是什么?
A:快照是在Raft中日志压缩的机制,其主要作用是:
减小日志的存储空间:随着系统运行,日志会不断增长,占用大量存储空间。通过定期生成快照,可以删除已经包含在快照中的旧日志条目。
加快节点恢复速度:当新节点加入或节点重新加入集群时,通过接收快照,可以快速更新到集群的最新状态,而不需要从头开始复制所有日志。
Q:为什么要区分发送快照和发送日志?
A:当日志达到一定长度或满足特定条件时,系统会对日志进行快照,将之前的日志压缩为一个快照文件,并丢弃旧的日志条目。
因此,当Leader与Follower同步日志时,需要根据Follower的日志状态来决定是发送快照还是发送增量日志:
- 发送快照:当Follower缺少的日志已经被Leader压缩为快照,Leader只能通过发送快照来让Follower更新到最新状态。
- 发送日志:当Follower缺少的日志还存在于Leader的日志中,Leader可以通过发送增量日志条目来同步Follower的日志。
在看代码之前先别嫌我啰嗦,再看几个成员变量和成员变量的含义:
preLogIndex是 Leader 希望 Follower 的日志与自己匹配的最后一个日志索引。当 Follower 的日志与 Leader 的日志不一致时,Leader 可以通过调整preLogIndex和prevLogTerm,找到与 Follower 日志匹配的位置,然后从那里开始发送日志,修复不一致。在发送AppendEntries请求时,Leader 使用preLogIndex来告诉 Follower,新的日志条目应该接在preLogIndex后面。prevLogTerm是与preLogIndex对应的日志条目的 任期(term)。它表示 Leader 在preLogIndex位置上的日志条目所属的任期。getPrevLogInfo用于 获取指定 Follower 的前一个日志索引(preLogIndex)和前一个日志任期(prevLogTerm)。它根据 Follower 的nextIndex,计算出对应的preLogIndex和preLogvTerm。leaderCommit是 Leader 当前已提交的最高日志索引。它表示 Leader 已经将日志条目应用到状态机的位置。
摩拳擦掌!开始攻克第二个功能块!
首先,咱得确定leader身份吧,不是leader不能发送心跳也没资格统一日志呀,然后为了线程安全,咱得用lock_guard保护一下锁吧~
接着,对follower(除了自己以外的所有节点)发送请求,检查每一个follower的m_nextIndex[i](下一个需要发送给Follower的日志索引)是否小于等于m_lastSnapshotIncludeIndex(最后一个被包含在快照中的日志索引)。如果是,那么说明Follower缺失的日志已经被压缩,咱们需要发送快照。
发送快照就需要调用leaderSendSnapShot了,这里实现的是逻辑不是具体操作,这个只需要留影响
以上逻辑的代码我先贴一下:
std::lock_guard<mutex> g(m_mtx);
if (m_status == Leader) {
auto appendNums = std::make_shared<int>(1); //正确返回的节点的数量
for (int i = 0; i < m_peers.size(); i++) {
if(i == m_me){ //不对自己发送AE
continue;
}
if (m_nextIndex[i] <= m_lastSnapshotIncludeIndex) {
//改发送的日志已经被做成快照,必须发送快照了
std::thread t(&Raft::leaderSendSnapShot, this, i);
t.detach();
continue;
}接下来就是发送心跳了,心跳在代码上的具体表现就是Leader想每个Follower发送AppendEntries(追加日志) RPC请求。即使在没有新日志条目需要复制的情况下,也会发送空的AppendEntries请求,这实际上就是心跳。
发送前先构造发送值,先初始化一波~
int preLogIndex = -1;int PrevLogTerm = -1;
然后调用 getPrevLogInfo 函数,从 Leader 的日志中获取 preLogIndex 和 PrevLogTerm。用于构建 AppendEntries 请求。
接下来创造请求参数,为即将发送的AppendEntries请求准备参数:
- 将 Leader 的当前任期
m_currentTerm设置到请求参数中 - 将 Leader 的标识
m_me设置到请求参数中 - 将preLogIndex设置到请求参数中,告诉 Follower,新的日志条目应该接在此索引之后
- 将prevLogTerm设置到请求参数中,用于 Follower 验证其在
preLogIndex处的日志任期是否与 Leader 一致 - 清空日志条目列表,clear_entries(),注意情况的entries列表,是日志条目,以上的参数没有被清空
- 将 Leader 的
m_commitIndex设置到请求参数中,通知 Follower 可以提交到该索引
以上还属于初始化参数的阶段,我把以上全部逻辑代码合并贴出来,分块儿看:
void Raft::doHeartBeat() {
std::lock_guard<mutex> g(m_mtx);
if (m_status == Leader) {
auto appendNums = std::make_shared<int>(1); //后面才用到
for (int i = 0; i < m_peers.size(); i++) {
if(i == m_me){
continue;
}
if (m_nextIndex[i] <= m_lastSnapshotIncludeIndex) {
std::thread t(&Raft::leaderSendSnapShot, this, i);
t.detach();
continue;
}
//发送心跳,构造发送值
int preLogIndex = -1;
int PrevLogTerm = -1;
getPrevLogInfo(i, &preLogIndex, &PrevLogTerm);
std::shared_ptr<mprrpc::AppendEntriesArgs> appendEntriesArgs = std::make_shared<mprrpc::AppendEntriesArgs>();
appendEntriesArgs->set_term(m_currentTerm);
appendEntriesArgs->set_leaderid(m_me);
appendEntriesArgs->set_prevlogindex(preLogIndex);
appendEntriesArgs->set_prevlogterm(PrevLogTerm);
appendEntriesArgs->clear_entries();
appendEntriesArgs->set_leadercommit(m_commitIndex);appendEntriesArgs已经构造好了,接下来我们需要统一日志:
如果 preLogIndex 不等于 m_lastSnapshotIncludeIndex,说明 Follower 缺少的日志还存在于 Leader 的日志中,可以直接发送增量日志。首先得添加日志条目,范围是从 preLogIndex 的下一个日志开始,直到当前日志的末尾。我们需要将每个日志条目添加到 entries 列表中。
如果 preLogIndex 等于 m_lastSnapshotIncludeIndex,说明之前的日志已被压缩成快照,需要从当前的日志开始发送所有条目。我们需要将所有的 m_logs 条目添加到 entries 列表中。
//leader对每个节点发送的日志长短不一,但是都保证从prevIndex发送直到最后
if (preLogIndex != m_lastSnapshotIncludeIndex) {
for (int j = getSlicesIndexFromLogIndex(preLogIndex) + 1; j < m_logs.size(); ++j) {
mprrpc::LogEntry *sendEntryPtr = appendEntriesArgs->add_entries();
*sendEntryPtr = m_logs[j];
}
} else {
for (const auto& item: m_logs) {
mprrpc::LogEntry *sendEntryPtr = appendEntriesArgs->add_entries();
*sendEntryPtr = item;
}
}接下来调用 getLastLogIndex 函数,获取 Leader 当前的最后一个日志索引,用于后续处理。
然后创建一个用于Follower对AppendEntries请求的回复响应,并启动一个新线程,调用 sendAppendEntries 函数,向 Follower i 发送请求,最后使用 detach 将线程分离,使其独立运行,不阻塞主线程,和上一篇的doElection很像。
最后结束对Followers的循环,重置心跳时间。
所有代码:
void Raft::doHeartBeat() {
std::lock_guard<mutex> g(m_mtx);
if (m_status == Leader) {
auto appendNums = std::make_shared<int>(1); //正确返回的节点的数量
for (int i = 0; i < m_peers.size(); i++) {
if(i == m_me){
continue;
}
if (m_nextIndex[i] <= m_lastSnapshotIncludeIndex) {
std::thread t(&Raft::leaderSendSnapShot, this, i);
t.detach();
continue;
}
int preLogIndex = -1;
int PrevLogTerm = -1;
getPrevLogInfo(i, &preLogIndex, &PrevLogTerm);
std::shared_ptr<mprrpc::AppendEntriesArgs> appendEntriesArgs = std::make_shared<mprrpc::AppendEntriesArgs>();
appendEntriesArgs->set_term(m_currentTerm);
appendEntriesArgs->set_leaderid(m_me);
appendEntriesArgs->set_prevlogindex(preLogIndex);
appendEntriesArgs->set_prevlogterm(PrevLogTerm);
appendEntriesArgs->clear_entries();
appendEntriesArgs->set_leadercommit(m_commitIndex);
if (preLogIndex != m_lastSnapshotIncludeIndex) {
for (int j = getSlicesIndexFromLogIndex(preLogIndex) + 1; j < m_logs.size(); ++j) {
mprrpc::LogEntry *sendEntryPtr = appendEntriesArgs->add_entries();
*sendEntryPtr = m_logs[j];
}
} else {
for (const auto& item: m_logs) {
mprrpc::LogEntry *sendEntryPtr = appendEntriesArgs->add_entries();
*sendEntryPtr = item;
}
}
int lastLogIndex = getLastLogIndex();
//构造返回值
const std::shared_ptr<mprrpc::AppendEntriesReply> appendEntriesReply = std::make_shared<mprrpc::AppendEntriesReply>();
appendEntriesReply->set_appstate(Disconnected);
std::thread t(&Raft::sendAppendEntries, this, i, appendEntriesArgs, appendEntriesReply,
appendNums);
t.detach();
}
m_lastResetHearBeatTime = now();
}
}sendAppendEntries
实现了Leader向Follower发送 AppendEntries(追加日志)RPC 请求,并处理 Follower 的响应。
- 发送
AppendEntries请求给指定的 Follower。 - 根据 Follower 的响应,更新 Leader 的内部状态,如
nextIndex和matchIndex。 - 处理日志不一致的情况,调整
nextIndex,以确保日志的一致性。 - 判断是否可以提交新的日志条目,并更新
commitIndex。
第一行代码:bool ok = m_peers[server]->AppendEntries(args.get(), reply.get());
作者的代码风格很统一,这块可以参照sendRequestVote了,还是很像,上一篇的努力是没有白费的,后面都是事半功倍的效果!
ok返回的是调用RPC是否成功的布尔值,接下来用锁,然后用任期判断现在的leader还能不能是leader,如果一切都没问题,也就是目前的节点就是任期最大的,那么开始正式操作,分为两个部分,日志不匹配的处理和日志匹配成功的处理:
- 日志不匹配处理
if (reply->updatenextindex() != -100) { ... },其中reply->updatenextindex() 是从follower返回的一个整数值,表示follower建议的下一个尝试发送日志索引,-100用作一个特殊标记,表示 Follower 没有提供有效的 updatenextindex。如果 reply->updatenextindex() 不等于 -100,说明 Follower 提供了一个有效的索引,Leader 可以更新 m_nextIndex[server]。
接下来就将 m_nextIndex[server] 设置为 Follower 建议的索引值。Leader 不再需要逐个减少 nextIndex,而是直接跳转到 Follower 提供的索引,大大提高了日志同步的效率。
- 日志匹配处理
成功响应计数器appendNums+1表示接收本次心跳或者日志,同意了日志,就更新相对于的matchIndex和nextIndex。
matchIndex的含义是记录了follower已经复制的最高日志索引:
args->prevlogindex():此次AppendEntries请求中的前一个日志索引。args->entries_size():此次发送的日志条目数量。- 总和:得到此次发送的最后一个日志条目的索引。
nextIndex的含义是下一个需要发送给follower的日志索引:
m_matchIndex[server] + 1,表示 Follower 已经复制到的索引,再加 1 就是下一个需要发送的索引。
Q:
m_nextIndex与m_matchIndex是否有冗余,即使用一个m_nextIndex可以吗?A:
不行的,
m_nextIndex的作用是用来寻找m_matchIndex,不能直接取代。我们可以从这两个变量的变化看,在当选leader后,m_nextIndex初始化为最新日志index,m_matchIndex初始化为0,如果日志不匹配,那么m_nextIndex就会不断的缩减,直到遇到匹配的日志,这时候m_nextIndex应该一直为m_matchIndex+1。如果一直不发生故障,那么后期m_nextIndex就没有太大作用了,但是raft考虑需要考虑故障的情况,因此需要使用两个变量。
跳出if-else之后,得到了最后一个log的索引,记录下来,之后使用
两个逻辑都已结束,现在就需要判断是否可以提交日志了
if (*appendNums >= 1 + m_peers.size() / 2)表示成功复制日志的节点数量达到或者已经超过了多数节点,则可以进行提交,更新m_commitIndex。
先把以上方法写成代码总结一下:
bool
Raft::sendAppendEntries(int server, std::shared_ptr<mprrpc::AppendEntriesArgs> args, std::shared_ptr<mprrpc::AppendEntriesReply> reply,
std::shared_ptr<int> appendNums) {
bool ok = m_peers[server]->AppendEntries(args.get(), reply.get());
if (!ok) {
return ok;
}
if (reply->appstate() == Disconnected) {
return ok;
}
lock_guard<mutex> lg1(m_mtx);
if(reply->term() > m_currentTerm){
m_status = Follower;
m_currentTerm = reply->term();
m_votedFor = -1;
return ok;
} else if (reply->term() < m_currentTerm) {
return ok;
}
if (m_status != Leader) {
return ok;
}
if (!reply->success()){
if (reply->updatenextindex() != -100) {
m_nextIndex[server] = reply->updatenextindex();
}
} else {
*appendNums = *appendNums +1;
m_matchIndex[server] = std::max(m_matchIndex[server],args->prevlogindex()+args->entries_size() );
m_nextIndex[server] = m_matchIndex[server]+1;
int lastLogIndex = getLastLogIndex();
if (*appendNums >= 1+m_peers.size()/2) {
*appendNums = 0;
if(args->entries_size() >0 && args->entries(args->entries_size()-1).logterm() == m_currentTerm){
m_commitIndex = std::max(m_commitIndex,args->prevlogindex() + args->entries_size());
}
}
}
return ok;
}Q:为什么*appendNums >= 1 + m_peers.size() / 2就可以提交了,有没有可能这个时候还没有更新完
A:
提交过程:
Leader 在收到大多数节点对该日志条目的成功响应后,可以更新自己的
commitIndex。之后,Leader 会通过心跳或后续的
AppendEntriesRPC,将新的commitIndex通知给 Followers,促使他们也更新自己的commitIndex,并应用日志到状态机。你的问题可以从两方面来回答:
多数派保证一致性:
在分布式系统中,使用大多数(即超过半数)的节点达成一致,可以确保系统的一致性。
因为在任何两个多数派中,至少有一个节点是重叠的,确保了已提交的日志条目在未来的 Leader 中依然存在。
安全性保证:
一旦一个日志条目在大多数节点上被存储并提交,即使当前 Leader 崩溃,新的 Leader 也会包含该日志条目。
这是因为在新的选举中,只有拥有已提交日志条目的节点才能成为 Leader。
当成功响应的节点数量达到或超过多数节点时,Leader 可以认为该日志条目已经被大多数节点存储,可以更新
commitIndex,进行提交。虽然,你说得对,在此条件满足时,可能仍有少数 Followers 还未成功接收到日志条目但是由于【一致性保证】因为大多数节点已经存储了该日志条目,Raft 的一致性机制确保了即使未更新的节点在之后重新加入,它们也会从 Leader 或新的 Leader 获取到缺失的日志条目,保持日志一致性。以及【可用性和安全性的平衡】,在分布式系统中,等待所有节点都更新可能会降低系统的可用性。使用多数派规则,可以在保证安全性的前提下,提高系统的可用性。
在日志提交后,leader会在后序的心跳或AppendEntries请求中,继续向位更新的follower发送缺失的日志条目,直到他们的日志与leader一直。如果未更新的节点因为网络分区或故障而暂时无法接收日志,当它们恢复后,会从 Leader 获取缺失的日志条目,更新自己的日志。
总结:
Raft 使用多数派协议确保系统的一致性和可用性。
在日志复制过程中,只要大多数节点存储了日志条目,Leader 就可以提交该日志。
未更新的节点会在之后追赶上来,确保整个集群的日志一致性。
Q:以安全方面考虑,最后更新commitIndex的代码为什么那样写?
A:这是为了确保 Leader 只提交当前任期(term)的日志条目。这样可以避免提交之前任期的日志可能导致的数据不一致问题,维护 Raft 协议的安全性和一致性。
在 Raft 协议中,Leader 在日志复制和提交时需要遵循特定的规则,以确保集群的一致性和安全性。
日志提交条件:
- Leader 可以将某个日志条目标记为已提交(即更新
commitIndex),当且仅当该日志条目已经被复制到集群中多数节点上。Leader 对
commitIndex的更新:
- Leader 会不断检查自己的日志,找到满足条件的最高的日志索引来更新
commitIndex。场景描述:
假设 Leader 在之前的任期内(term T)接收并复制了一个日志条目,但在还未提交该日志条目时发生了故障。
一个新的 Leader 当选,任期为 T+1,但其日志中可能不包含该未提交的日志条目。
问题:
如果允许新的 Leader 提交之前任期的日志条目,可能会导致已提交的日志在不同节点上不一致。
这违背了 Raft 协议的安全性要求,可能导致状态机应用不同的日志,产生不一致的状态。
解决方案
Leader 只提交当前任期内的日志条目:
- 这样可以确保提交的日志条目一定是由当前 Leader 提交,并且未来的 Leader 一定会包含这些日志条目。
之前任期的日志条目:
- 只有当当前任期的日志条目被提交后,之前任期的日志条目才能被间接地认为已提交。
效果:
- 避免了提交之前任期的日志条目可能导致的数据不一致问题,确保了领导人完整性。
整体代码:
bool
Raft::sendAppendEntries(int server, std::shared_ptr<mprrpc::AppendEntriesArgs> args, std::shared_ptr<mprrpc::AppendEntriesReply> reply,
std::shared_ptr<int> appendNums) {
// todo: paper中5.3节第一段末尾提到,如果append失败应该不断的retries ,直到这个log成功的被store
bool ok = m_peers[server]->AppendEntries(args.get(), reply.get());
if (!ok) {
return ok;
}
lock_guard<mutex> lg1(m_mtx);
//对reply进行处理
// 对于rpc通信,无论什么时候都要检查term
if(reply->term() > m_currentTerm){
m_status = Follower;
m_currentTerm = reply->term();
m_votedFor = -1;
return ok;
} else if (reply->term() < m_currentTerm) {//正常不会发生
return ok;
}
if (m_status != Leader) { //如果不是leader,那么就不要对返回的情况进行处理了
return ok;
}
//term相等
if (!reply->success()){
//日志不匹配,正常来说就是index要往前-1,既然能到这里,第一个日志(idnex = 1)发送后肯定是匹配的,因此不用考虑变成负数
//因为真正的环境不会知道是服务器宕机还是发生网络分区了
if (reply->updatenextindex() != -100) { //-100只是一个特殊标记而已,没有太具体的含义
// 优化日志匹配,让follower决定到底应该下一次从哪一个开始尝试发送
m_nextIndex[server] = reply->updatenextindex();
}
// 如果感觉rf.nextIndex数组是冗余的,看下论文fig2,其实不是冗余的
} else {
*appendNums = *appendNums +1; //到这里代表同意接收了本次心跳或者日志
m_matchIndex[server] = std::max(m_matchIndex[server],args->prevlogindex()+args->entries_size() ); //同意了日志,就更新对应的m_matchIndex和m_nextIndex
m_nextIndex[server] = m_matchIndex[server]+1;
int lastLogIndex = getLastLogIndex();
if (*appendNums >= 1 + m_peers.size()/2) { //可以commit了
//两种方法保证幂等性,1.赋值为0 2.上面≥改为==
*appendNums = 0; //置0
//日志的安全性保证!!!!! leader只有在当前term有日志提交的时候才更新commitIndex,因为raft无法保证之前term的Index是否提交
//只有当前term有日志提交,之前term的log才可以被提交,只有这样才能保证“领导人完备性{当选领导人的节点拥有之前被提交的所有log,当然也可能有一些没有被提交的}”
//说白了就是只有当前term有日志提交才会提交
if(args->entries_size() >0 && args->entries(args->entries_size()-1).logterm() == m_currentTerm){
m_commitIndex = std::max(m_commitIndex,args->prevlogindex() + args->entries_size());
}
}
}
return ok;
}AppendEntries1
实现了Follower节点处理Leader发来的AppendEntries RPC请求逻辑,一系列参数填到AppendEntriesArgs中,他再返回AppendEntriesReply,包含3个字段:
- s
uccess表示处理结果(表示 Follower 是否成功地接受并处理了 Leader 的AppendEntries请求。) term显示 Follower 当前的任期(Follower 当前的任期(currentTerm)。Leader 通过检查回复中的term,可以检测到自己是否过期,从而决定是否需要更新自己的状态。)updatenextindex提供日志同步建议(建议 Leader 下次发送日志时使用的nextIndex值。当日志不匹配时,Follower 提供一个索引,帮助 Leader 快速找到匹配的位置,加速日志同步过程。)。
这篇最后一个函数了,如果你认认真真看到这里,可以私聊我找我要一篇我自己整理的Raft100问,都是从各种地方面经上巴拉下来的,我自己写了答案,面试之前准备一下挺好的,我对于Raft项目就做这些准备...
还是可以对照选leader学..这个函数主要就是返回leader的响应
首先解锁,其次任期判断~老朋友了(在处理 RPC 请求和响应时,必须首先检查 term(任期),因为不同的节点角色(Leader、Follower、Candidate)对 AppendEntries 请求的反应不同。)
我们需要判断leader老不老,leader还能不能继续是leader,这步我不多说了,代码多次出现了
接下来重置状态为Follower并重置选举超时,这一步是有必要的,如果发生网络分区,那么 Candidate 可能会收到同一个 term 的 Leader 的消息,要转变为 Follower,以上逻辑贴代码:
void Raft::AppendEntries1(const mprrpc:: AppendEntriesArgs *args, mprrpc::AppendEntriesReply *reply) {
std::lock_guard<std::mutex> locker(m_mtx);
if (args->term() < m_currentTerm) {
reply->set_success(false);
reply->set_term(m_currentTerm);
reply->set_updatenextindex(-100); // 论文中:让领导人可以及时更新自己
DPrintf("[func-AppendEntries-rf{%d}] 拒绝了 因为Leader{%d}的term{%v}< rf{%d}.term{%d}\n", m_me, args->leaderid(),args->term() , m_me, m_currentTerm) ;
return; // 注意从过期的领导人收到消息不要重设定时器
}
Defer ec1([this]() -> void { this->persist(); });//由于这个局部变量创建在锁之后,因此执行persist的时候应该也是拿到锁的. //本质上就是使用raii的思想让persist()函数执行完之后再执行
if (args->term() > m_currentTerm) {
// 三变 ,防止遗漏,无论什么时候都是三变
m_status = Follower;
m_currentTerm = args->term();
m_votedFor = -1; // 这里设置成-1有意义,如果突然宕机然后上线理论上是可以投票的
// 这里可不返回,应该改成让改节点尝试接收日志
// 如果是领导人和candidate突然转到Follower好像也不用其他操作
// 如果本来就是Follower,那么其term变化,相当于“不言自明”的换了追随的对象,因为原来的leader的term更小,是不会再接收其消息了
}
// 如果发生网络分区,那么candidate可能会收到同一个term的leader的消息,要转变为Follower,为了和上面,因此直接写
m_status = Follower; // 这里是有必要的,因为如果candidate收到同一个term的leader的AE,需要变成follower
// term相等
m_lastResetElectionTime = now(); //重置选举超时定时器倒数第二行的作用是确保节点的状态就是Follower,其实也是有必要的重置选举时间是为了防止Follower因为长时间没有收到leader消息而发起新选举。
进行日志一致性检查,检查 Leader 发送的 prevLogIndex 是否与自己的日志匹配。不能无脑的从 prevLogIndex 开始接收日志,因为 RPC 可能会延迟,导致发过来的 log 是很久之前的
// 那么就比较日志,日志有 3 种情况
if (args->prevlogindex() > getLastLogIndex()) {
reply->set_success(false);
reply->set_term(m_currentTerm);
reply->set_updatenextindex(getLastLogIndex() + 1);
return;
} else if (args->prevlogindex() < m_lastSnapshotIncludeIndex) { // 如果 prevLogIndex 还没有跟上快照
reply->set_success(false);
reply->set_term(m_currentTerm);
reply->set_updatenextindex(m_lastSnapshotIncludeIndex + 1);
}
-
prevLogIndex大于自己的最后日志索引:- 处理:
- 设置
success为false。 - 返回当前
term。 - 提供
updatenextindex,建议 Leader 下次发送的日志索引。
- 设置
- 原因:Leader 认为 Follower 的日志比实际的要长,Follower 需要让 Leader 减小发送的日志索引。
- 处理:
-
prevLogIndex小于自己的快照包含的索引:- 处理:
- 设置
success为false。 - 返回当前
term。 - 提供
updatenextindex,建议为快照包含的下一个索引。
- 设置
- 原因:Follower 的日志已经进行了快照,
prevLogIndex太旧,需要 Leader 发送更新的日志。
- 处理:
日志匹配检查 ,检查 Follower 在 prevLogIndex 处的日志条目的 term 是否与 Leader 提供的 prevLogTerm 一致。
如果一致:
一致就日志匹配,复制日志,更新commitIndex
1. 复制日志
if (matchLog(args->prevlogindex(), args->prevlogterm())) {
//日志匹配,那么就复制日志
for (int i = 0; i < args->entries_size(); i++) {
auto log = args->entries(i);
if (log.logindex() > getLastLogIndex()) { //超过就直接添加日志
m_logs.push_back(log);
} else { //没超过就比较是否匹配,不匹配再更新,而不是直接截断
if (m_logs[getSlicesIndexFromLogIndex(log.logindex())].logterm() != log.logterm()) { //不匹配就更新
m_logs[getSlicesIndexFromLogIndex(log.logindex())] = log;
}
}
}2.更新commitIndex
- 更新 Follower 的已提交索引
m_commitIndex: - 条件:如果 Leader 的已提交索引
leaderCommit大于 Follower 的m_commitIndex。 - 更新方式:
- 取较小值:
m_commitIndex = min(leaderCommit, getLastLogIndex())。- 原因:防止
leaderCommit超过 Follower 当前的最后日志索引,避免访问越界。
- 原因:防止
- 取较小值:
-
目的:
- 确保已提交的日志被应用:Follower 更新
commitIndex后,可以将已提交的日志应用到状态机,保持状态一致。 - 与 Leader 保持一致:跟随 Leader 的提交进度,确保集群的一致性。
- 确保已提交的日志被应用:Follower 更新
if (matchLog(args->prevlogindex(), args->prevlogterm())) {
//日志匹配,那么就复制日志
for (int i = 0; i < args->entries_size(); i++) {
auto log = args->entries(i);
if (log.logindex() > getLastLogIndex()) { //超过就直接添加日志
m_logs.push_back(log);
} else { //没超过就比较是否匹配,不匹配再更新,而不是直接截断
if (m_logs[getSlicesIndexFromLogIndex(log.logindex())].logterm() != log.logterm()) { //不匹配就更新
m_logs[getSlicesIndexFromLogIndex(log.logindex())] = log;
}
}
}
if (args->leadercommit() > m_commitIndex) {
m_commitIndex = std::min(args->leadercommit(), getLastLogIndex());// 这个地方不能无脑跟上getLastLogIndex(),因为可能存在args->leadercommit()落后于 getLastLogIndex()的情况
}
// 领导会一次发送完所有的日志
reply->set_success(true);
reply->set_term(m_currentTerm);
return;
}Q:为什么args->leadercommit() > m_commitIndex的时候m_commitIndex = min(leaderCommit, getLastLogIndex()),如果args->leadercommit() < m_commitIndex不也得m_commitIndex = std::min(args->leadercommit(), getLastLogIndex());吗?
A:
当
leaderCommit > m_commitIndex时:
- Follower 的提交进度落后于 Leader:Follower 需要更新自己的
m_commitIndex,以跟上 Leader 的提交进度。- 更新方式:
m_commitIndex = min(leaderCommit, getLastLogIndex()),确保不会提交超过自己日志长度的索引。当
leaderCommit < m_commitIndex时:
- Follower 的提交进度领先于 Leader:这可能发生在以下情况:
- 新 Leader 当选:新 Leader 可能还未更新自己的
leaderCommit,而 Follower 的m_commitIndex仍然保持在之前的值。- 网络延迟:Leader 的
leaderCommit尚未传播到所有 Followers。- 不能更新
m_commitIndex:
- 禁止回退:根据 Raft 协议,
commitIndex不能减少,已提交的日志条目不能被“取消”提交。- 安全性:如果 Follower 将
m_commitIndex减小,可能导致已应用的日志条目被撤销,破坏状态机的一致性和正确性。
如果不一致
不匹配,不匹配不是一个一个往前,而是有优化加速。PrevLogIndex 长度合适,但是不匹配,因此往前寻找 矛盾的term的第一个元素。
为什么该term的日志都是矛盾的呢?也不一定都是矛盾的,只是这么优化减少rpc而已
什么时候term会矛盾呢?很多情况,比如leader接收了日志之后马上就崩溃等等
else {
reply->set_updatenextindex(args->prevlogindex());
for (int index = args->prevlogindex(); index >= m_lastSnapshotIncludeIndex; --index) {
if (getLogTermFromLogIndex(index) != getLogTermFromLogIndex(args->prevlogindex())) {
reply->set_updatenextindex(index + 1);
break;
}
}
reply->set_success(false);
reply->set_term(m_currentTerm);
return;
}Q:if (getLogTermFromLogIndex(index) != getLogTermFromLogIndex(args->prevlogindex())) 。用的同一个函数检查谁的任期,这不是就检查了一个的任期吗,并没有leader和follower对比吧???
A:
我觉得你一定是没明白prevlogindex的含义,prevlogindex是leader在发送AppendEntries RPC时提供的参数,表示leader的日志中某一条日志的索引。Leader 希望从该日志后面开始,或者希望确认该条日志已经成功复制给 Follower。
getLogTermFromLogIndex(args->prevlogindex())实际上是Leader发送过来的日志索引对应的条目 在Follower 上的任期号。这个值在Follower日志中是固定的,因为Leader正在尝试将它自己在某个任期下的日志条目复制给Follower。
由于 Raft 要保证日志的一致性,如果 Follower 日志中该条目的任期号与 Leader 提供的任期号不匹配,就表示这两者的日志在该点不同,发生了冲突。因此,Leader 从
prevlogindex开始查找 Follower 日志中的日志条目,直到找到第一个任期号不匹配的位置。
Q:假设在日志条目 i 处发生了冲突,那么 从 i+1 到 n 处的所有条目(包括 Leader 和 Follower 的日志)都会不同。所以就从 i 处开始日志复制,但是,有没有一种可能,就是在i - 3处也冲突了
A:不太可能,原因如下:
Raft 的日志是顺序一致的:一旦在某个日志条目
i发生了冲突,这就意味着在i之后的所有日志条目都会不一致。因此,如果在i处发生冲突,并不需要再回溯到i-3处进行检查,因为如果之前的日志没有冲突,后续的日志也就不会有冲突。如果存在冲突,日志会在第一个冲突点停止检查,而后续所有的日志都会被视为不一致的。Raft 的日志条目包含了严格的顺序和任期号:Raft 协议通过任期号来保证日志条目的顺序一致性。如果在某个条目
i处发现与Follower的日志不同,那么从i+1到n处的日志条目都会被认为是无效的。因此,实际上只需要从第一个冲突点开始进行修复,不需要再去回溯之前的日志。
这部分的完整代码:
void Raft::AppendEntries1(const mprrpc:: AppendEntriesArgs *args, mprrpc::AppendEntriesReply *reply) {
std::lock_guard<std::mutex> locker(m_mtx);
// 不同的人收到AppendEntries的反应是不同的,要注意无论什么时候收到rpc请求和响应都要检查term
if (args->term() < m_currentTerm) {
reply->set_success(false);
reply->set_term(m_currentTerm);
reply->set_updatenextindex(-100); // 论文中:让领导人可以及时更新自己
DPrintf("[func-AppendEntries-rf{%d}] 拒绝了 因为Leader{%d}的term{%v}< rf{%d}.term{%d}\n", m_me, args->leaderid(),args->term() , m_me, m_currentTerm) ;
return; // 注意从过期的领导人收到消息不要重设定时器
}
Defer ec1([this]() -> void { this->persist(); });//由于这个局部变量创建在锁之后,因此执行persist的时候应该也是拿到锁的. //本质上就是使用raii的思想让persist()函数执行完之后再执行
if (args->term() > m_currentTerm) {
// 三变 ,防止遗漏,无论什么时候都是三变
m_status = Follower;
m_currentTerm = args->term();
m_votedFor = -1; // 这里设置成-1有意义,如果突然宕机然后上线理论上是可以投票的
// 这里可不返回,应该改成让改节点尝试接收日志
// 如果是领导人和candidate突然转到Follower好像也不用其他操作
// 如果本来就是Follower,那么其term变化,相当于“不言自明”的换了追随的对象,因为原来的leader的term更小,是不会再接收其消息了
}
// 如果发生网络分区,那么candidate可能会收到同一个term的leader的消息,要转变为Follower,为了和上面,因此直接写
m_status = Follower; // 这里是有必要的,因为如果candidate收到同一个term的leader的AE,需要变成follower
// term相等
m_lastResetElectionTime = now(); //重置选举超时定时器
// 不能无脑的从prevlogIndex开始阶段日志,因为rpc可能会延迟,导致发过来的log是很久之前的
// 那么就比较日志,日志有3种情况
if (args->prevlogindex() > getLastLogIndex()) {
reply->set_success(false);
reply->set_term(m_currentTerm);
reply->set_updatenextindex(getLastLogIndex() + 1);
return;
} else if (args->prevlogindex() < m_lastSnapshotIncludeIndex) { // 如果prevlogIndex还没有更上快照
reply->set_success(false);
reply->set_term(m_currentTerm);
reply->set_updatenextindex(m_lastSnapshotIncludeIndex + 1);
}
// 本机日志有那么长,冲突(same index,different term),截断日志
// 注意:这里目前当args.PrevLogIndex == rf.lastSnapshotIncludeIndex与不等的时候要分开考虑,可以看看能不能优化这块
if (matchLog(args->prevlogindex(), args->prevlogterm())) {
//日志匹配,那么就复制日志
for (int i = 0; i < args->entries_size(); i++) {
auto log = args->entries(i);
if (log.logindex() > getLastLogIndex()) { //超过就直接添加日志
m_logs.push_back(log);
} else { //没超过就比较是否匹配,不匹配再更新,而不是直接截断
if (m_logs[getSlicesIndexFromLogIndex(log.logindex())].logterm() != log.logterm()) { //不匹配就更新
m_logs[getSlicesIndexFromLogIndex(log.logindex())] = log;
}
}
}
if (args->leadercommit() > m_commitIndex) {
m_commitIndex = std::min(args->leadercommit(), getLastLogIndex());// 这个地方不能无脑跟上getLastLogIndex(),因为可能存在args->leadercommit()落后于 getLastLogIndex()的情况
}
// 领导会一次发送完所有的日志
reply->set_success(true);
reply->set_term(m_currentTerm);
return;
} else {
// 不匹配,不匹配不是一个一个往前,而是有优化加速
// PrevLogIndex 长度合适,但是不匹配,因此往前寻找 矛盾的term的第一个元素
// 为什么该term的日志都是矛盾的呢?也不一定都是矛盾的,只是这么优化减少rpc而已
// ?什么时候term会矛盾呢?很多情况,比如leader接收了日志之后马上就崩溃等等
reply->set_updatenextindex(args->prevlogindex());
for (int index = args->prevlogindex(); index >= m_lastSnapshotIncludeIndex; --index) {
if (getLogTermFromLogIndex(index) != getLogTermFromLogIndex(args->prevlogindex())) {
reply->set_updatenextindex(index + 1);
break;
}
}
reply->set_success(false);
reply->set_term(m_currentTerm);
return;
}
}关于快照
啥是快照
当在Raft协议中的日志变得太大时,为了避免无限制地增长,系统可能会采取快照(snapshot)的方式来压缩日志。快照是系统状态的一种紧凑表示形式,包含在某个特定时间点的所有必要信息,以便在需要时能够还原整个系统状态。
如果你学习过redis,那么快照说白了就是rdb,而raft的日志可以看成是aof日志。rdb的目的只是为了崩溃恢复的加速,如果没有的话也不会影响系统的正确性,这也是为什么选择不详细讲解快照的原因,因为只是日志的压缩而已。
快照咋传
快照的传输主要涉及:kv数据库与raft节点之间;不同raft节点之间。
kv数据库与raft节点之间:因为快照是数据库的压缩表示,因此需要由数据库打包快照,并交给raft节点。当快照生成之后,快照内设计的操作会被raft节点从日志中删除(不删除就相当于有两份数据,冗余了)。
不同raft节点之间:当leader已经把某个日志及其之前的内容变成了快照,那么当涉及这部的同步时,就只能通过快照来发送。

















 1899
1899

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









