







 本文详细介绍了Oracle中的分组查询,包括分组函数的使用、GROUP BY语句的两种用法、HAVING子句与WHERE子句的区别,以及ORDER BY子句的运用。通过实例展示了如何进行分组过滤,强调了在SQL优化中应尽量使用WHERE子句代替HAVING子句,同时提到了分组函数的嵌套和GROUP BY语句的增强功能。
本文详细介绍了Oracle中的分组查询,包括分组函数的使用、GROUP BY语句的两种用法、HAVING子句与WHERE子句的区别,以及ORDER BY子句的运用。通过实例展示了如何进行分组过滤,强调了在SQL优化中应尽量使用WHERE子句代替HAVING子句,同时提到了分组函数的嵌套和GROUP BY语句的增强功能。
▲ 分组函数
 分组函数会作用于一组数据,并返回一个值。
分组函数会作用于一组数据,并返回一个值。




SQL> set linesize 200
SQL> col 部门中员工的姓名 for a60
SQL> select deptno 部门号,wm_concat(ename) 部门中员工的姓名
2 from emp
3 group by deptno;
部门号 部门中员工的姓名
10 CLARK,MILLER,KING
20 SMITH,FORD,ADAMS,SCOTT,JONES
30 ALLEN,JAMES,TURNER,BLAKE,MARTIN,WARD

分组函数会忽略空值,
NVL函数会使分组函数无法忽略空值。
SQL> select count(comm),count(nvl(comm,0))
2 from emp;
COUNT(COMM) COUNT(NVL(COMM,0))
4 14
▲ group by 语句

用法1:当select语句的列表中有组函数时,所有不属于组函数的列都要包含在group by子句中。
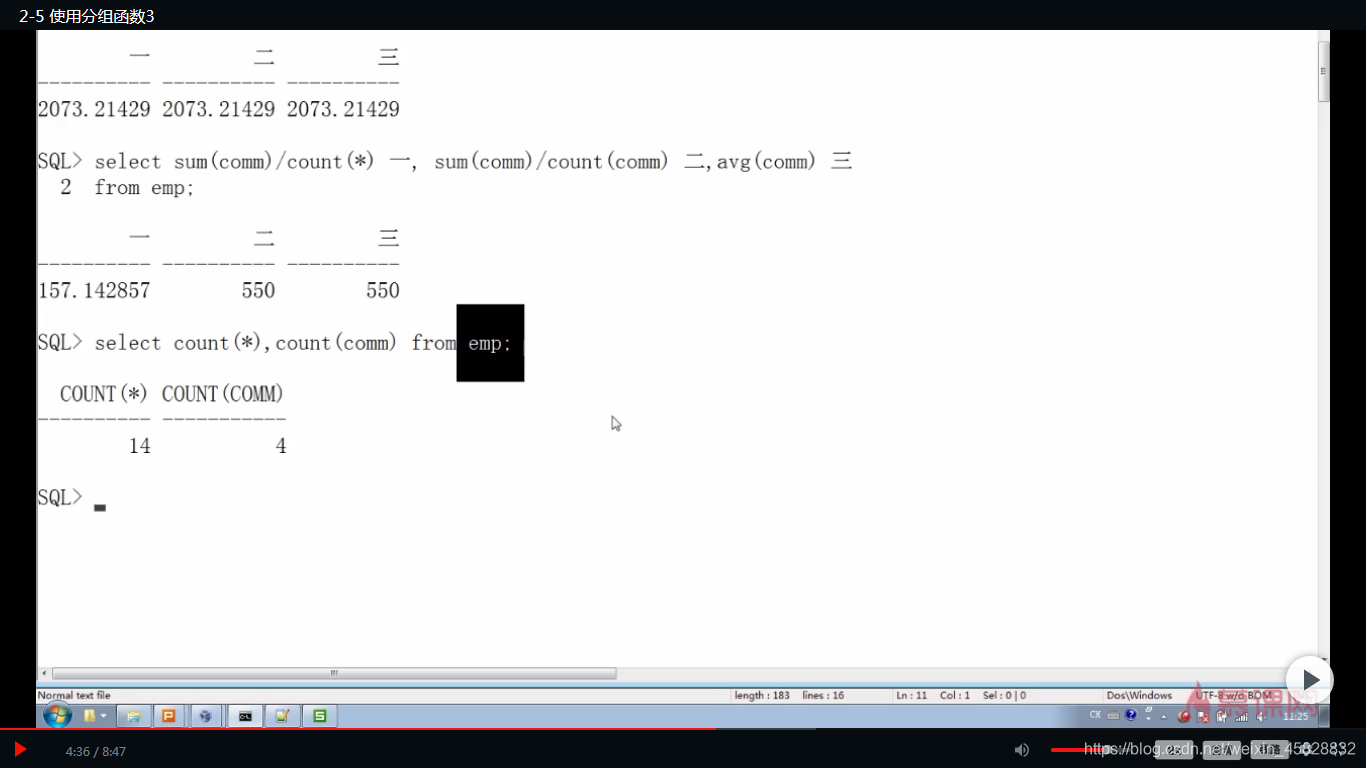
SQL> select deptno,avg(sal)
2 from emp
3 group by deptno;
DEPTNO AVG(SAL)
30 1700
20 2335
10 3516.66667
用法2:包含在group by子句中的列不必包含在select 列表中

▲having子句
group by语句对数据进行分组以后需要对数据进行过滤,可以使用having语句
 例:求平均工资大于2000的部门号和部门平均工资
例:求平均工资大于2000的部门号和部门平均工资
SQL> select deptno,avg(sal)
2 from emp
3 group by deptno
4 having avg(sal)>2000;
DEPTNO AVG(SAL)
20 2335
10 3516.66667
在存在group by的语句中,where与having语句有时可以通用,但两者也有区别。
where与having的区别
1、不能在where子句中使用组函数
2、可以在having子句中使用组函数
由下例可见不能再where子句中使用组函数(也叫分组函数)
SQL> select deptno,avg(sal)
2 from emp
3 where avg(sal)>2000
4 group by deptno;
where avg(sal)>2000
*
第 3 行出现错误:
ORA-00934: 此处不允许使用分组函数
带group by 的查询中,有时where和having子句可以通用,这时从sql优化角度,尽量使用where子句。
见下例:
求10号部门平均工资
having用法:
SQL> select deptno,avg(sal)
2 from emp
3 group by deptno
4 having deptno=10;
DEPTNO AVG(SAL)
10 3516.66667
where用法:
SQL> select deptno,avg(sal)
2 from emp
3 where deptno=10
4 group by deptno;
DEPTNO AVG(SAL)
10 3516.66667
注意:此处where的语句中不能省略group by 语句,说明见以上。
group by查询中,
用where的是先过滤再分组,即先查出10号部门的记录,再把符合条件的记录进行分组;
用having的是先分组再过滤,即先按部门号对记录进行分组,再选出10号部门的记录。
可见,where使得分组记录数大大降低,提高了效率。
having与where语句容易混淆的地方。
列出emp,dept表各个部门的MANAGER(经理)的最低薪金和部门号:
SQL> ed
已写入 file afiedt.buf
1 select d.dname,min(e.sal)
2 from emp e,dept d
3 where e.deptno=d.deptno
4 group by d.dname
5* having e.empjob='MANAGER'
SQL> /
having e.empjob='MANAGER'
*
第 5 行出现错误:
ORA-00979: 不是 GROUP BY 表达式
上面错误是因为empjob是在按部门分组以后进行having e.empjob='MANAGER’过滤,而这时数据里面没有e.empjob这个字段,只有d.dname,min(e.sal)两个字段,正确写法如下:
SQL> ed
已写入 file afiedt.buf
1 select d.dname,min(e.sal)
2 from emp e,dept d
3 where e.deptno=d.deptno and e.empjob='MANAGER'
4* group by d.dname
SQL> /
DNAME MIN(E.SAL)
-------------- ----------
ACCOUNTING 3250
RESEARCH 3875
SALES 3650
▲Order by 子句
#order by
3种书写方式
(1)列名
SQL> select deptno,avg(sal)
2 from emp
3 group by deptno
4 order by deptno;
(2)列别名
select deptno,avg(sal) 平均工资
from emp
group by deptno
order by 平均工资;
(3)列号
select deptno,avg(sal) 平均工资
from emp
group by deptno
order by 2;
DEPTNO 平均工资
30 1700
20 2335
10 3516.66667
小技巧:
a可以用于对之前sql语句的添加,记得a后添加多一个空格:
SQL> ed
已写入 file afiedt.buf
1 select deptno,avg(sal) 平均工资
2 from emp
3 group by deptno
4* order by 2
SQL> /
DEPTNO 平均工资
30 1700
20 2335
10 3516.66667
SQL> a desc;–此处需要多加一个空格
4* order by 2 desc
SQL> /
DEPTNO 平均工资
10 3516.66667
20 2335
30 1700
▲分组函数可以用于嵌套:

SQL> select max(avg(sal))
2 from emp
3 group by deptno;
MAX(AVG(SAL))
3516.66667
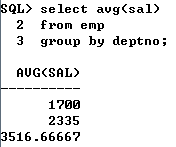
#group by 语句增强:后置 rollup(a,b)
▲group by 语句的增强
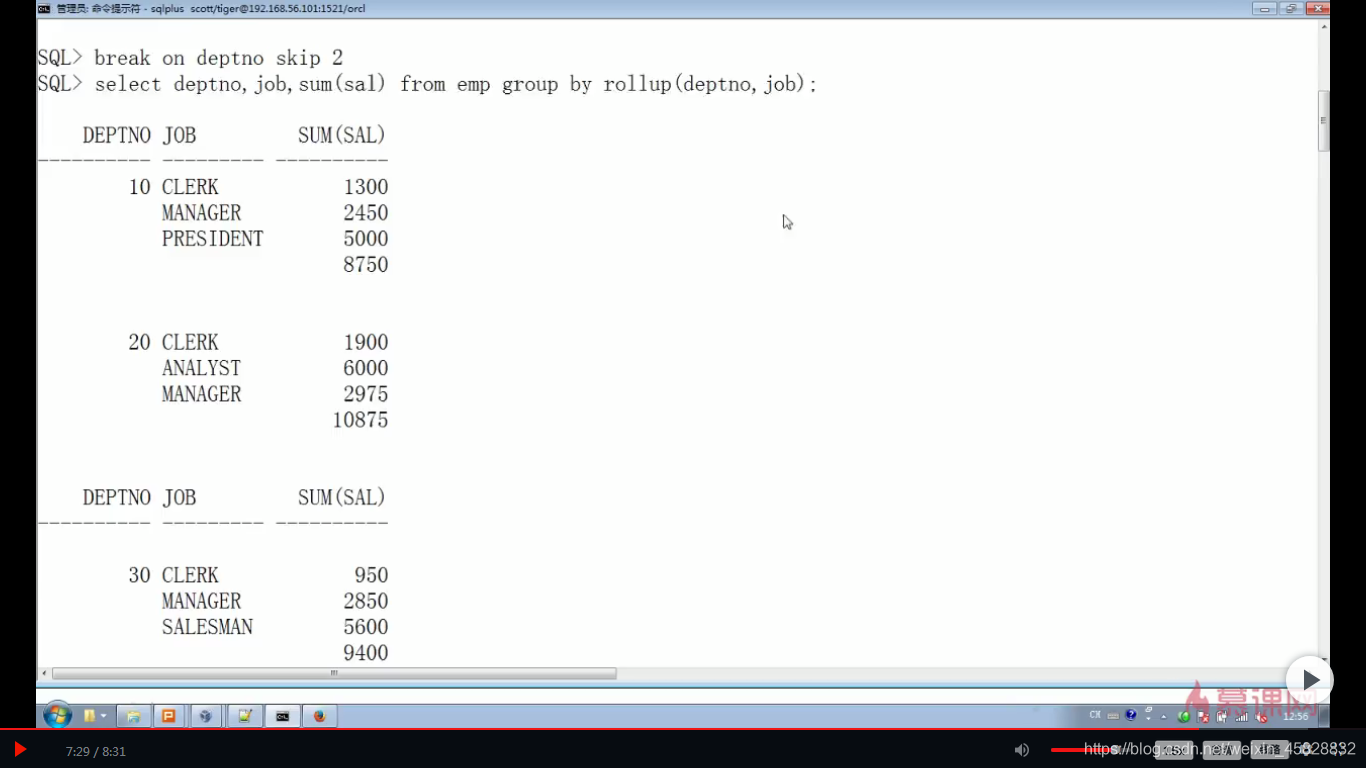 SQL> select deptno,empjob,sum(sal) from emp group by rollup(deptno,empjob);
SQL> select deptno,empjob,sum(sal) from emp group by rollup(deptno,empjob);
DEPTNO EMPJOB SUM(SAL)
10 CLERK 1300
10 MANAGER 3250
10 PRESIDENT 6000
10 10550
20 CLERK 1900
20 ANALYST 6000
20 MANAGER 3775
20 11675
30 CLERK 950
30 MANAGER 3650
30 SALESMAN 5600
DEPTNO EMPJOB SUM(SAL)
30 10200
32425
下面是添加的操作的图片:





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









