




 这篇博客详细探讨了Linux系统的基础知识,涉及用户划分、进程管理,包括孤儿进程、僵尸进程和fork函数,以及Task_struct在进程中的作用。还讨论了Linux内存管理,如用户空间与内核空间、内存分配策略以及进程空间管理。此外,还涵盖了文件管理、IO设备管理、环境变量、shell和命令行操作,以及硬链接和软链接的区别。博客内容深入浅出,对理解Linux操作系统和Java在Linux上的运行有极大帮助。
这篇博客详细探讨了Linux系统的基础知识,涉及用户划分、进程管理,包括孤儿进程、僵尸进程和fork函数,以及Task_struct在进程中的作用。还讨论了Linux内存管理,如用户空间与内核空间、内存分配策略以及进程空间管理。此外,还涵盖了文件管理、IO设备管理、环境变量、shell和命令行操作,以及硬链接和软链接的区别。博客内容深入浅出,对理解Linux操作系统和Java在Linux上的运行有极大帮助。
用户划分
超级用户root(0)
程序用
户(1~499)
普通用户(500~65535)
超级用户:默认是root用户,其UID和GID均为0。在每台unix/linux操作系统中都是唯一且真实存在的,通过它可以登录系统,可以操作系统中任何文件和命令,拥有最高的管理权限
普通用户:这类用户一般是由具备系统管理员root的权限的运维人员添加的。
/. /./.
程序用户:这类用户的最大特点是安装系统后默认就会存在的,且默认情 ?况不能登录系统,它们是系统正常运行必不可少的,他们的存在主要是方便系统管理,满足相应的系统进程都文件属主的要求。例如系统默认的bin、adm、nodoby、mail用户等
linux系统中的用户组(group)就是具有相同特性的用户(user)集合;
Linux系统中下的账户文件主要有
/etc/passwd:展示所有的用户及密码,uidgid等等
/etc/shadow:展示所有用户和加密后的密码
/etc/group:展示用户组的各个属性
/etc/gshadow
增加用户:当查看/home/目录时,会发现系统自动建立了一个zhonggy的目录。
useradd zhonggy
修改密码:passwd 123
删除用户:userdel
sudo su:切换root
su username:切换普通用户
常用操作指令:
find:查找符合条件的文件
find /etc -name “ifcfg-eth0”
find /etc -size +5M 大于5M
grep :用于查找文件里符合条件的字符串
压缩:tar
执行退出: exit
查看当前路径: pwd
创建目录: mkdir
创建文件:典型的如 touch,vi 也可以创建文件
文件权限修改:chmod 777 file
rwx读写执行分别代表421 用户|所在组|其他人
mv:移动文件
cp -r:复制文件
cat A B:在B上连接A文件
touch:无则创建,有则修改文件的时间属性
rm -rf
kill
ls -l:所有不隐藏的文件 ls -a:隐藏的文件
& 表示任务在后台执行,如要在后台运行redis-server,则有 redis-server &
&& 表示前一条命令执行成功时,才执行后一条命令 ,如 echo '1‘ && echo ‘2’
| 表示管道,上一条命令的输出,作为下一条命令参数,如 echo ‘yes’ | wc -l
|| 表示上一条命令执行失败后,才执行下一条命令,如 cat nofile || echo “fail”
-:一般是一个字母参数ls -l
–:一般是长参数chkconfig --add
查看当前进程: ps
ps -ef:查看所有进程信息
ps -ef/grep pid
netstat apo/grep portId
%CPU: CPU占用率
%MEM: 内存占用率
STAT: 进程状态
描述Linux运行级别0-6的各自含义
0:关机模式
1:单用户模式<==破解root密码
2:无网络支持的多用户模式
3:有网络支持的多用户模式(文本模式,工作中最常用的模式)
4:保留,未使用
5:有网络支持的X-windows支持多用户模式(桌面)
6: 重新引导系统,即重启
通过init命令切换运行级别
GPL:(通用公共许可证):一种授权,任何人有权取得、修改、重新发布自由软件的权力。
GNU:(革奴计划):目标是创建一套完全自由、开放的的操作系统。 自由软件:是一种可以不受限制地自由使用、复制、研究、修改和分发的软件。主要许可证有GPL和BSD许可证两种。
进程管理
linux线程为进程的执行上下文
进程的数据结构:task_struct
六种基本状态:
R (TASK_RUNNING)
1:正在CPU上执行的进程
2:可执行但是尚未被调度执行
S (TASK_INTERRUPTIBLE),可中断的睡眠状态
D (TASK_UNINTERRUPTIBLE),不可中断的睡眠状态。不响应异步信号
无法kill,所以几乎不会出现TASK_UNINTERRUPTIBLE。通常出现在等待IO完成但是长期等待的情况
SIGSTOP/SIGCONT
T (TASK_STOPPED or TASK_TRACED),暂停状态或跟踪状态
Z (TASK_DEAD - EXIT_ZOMBIE),退出状态,进程成为僵尸进程。进程占有的所有资源将被回收,除了task_struct结构(以及少数资源)以外。
X (TASK_DEAD - EXIT_DEAD),退出状态,进程即将被销毁
linux操作系统初始化时,创建pid为1,init进程
有两项使命:
1:执行系统初始化脚本,创建一系列的进程(它们都是init进程的子孙)
2:在一个死循环中等待其子进程的退出事件,并调用waitid系统调用来完成“收尸”工作
子进程在退出的过程中,内核会给其父进程发送一个信号,通知父进程来“收尸”只要父进程不退出,这个僵尸状态的子进程就一直存在。那么如果父进程退出了呢,谁又来给子进程“收尸”?当进程退出的时候,会将它的所有子进程都托管给别的进程(使之成为别的进程的子进程)
孤儿进程
每个子进程都有个父进程,但是如果父意外退出了,子进成为孤儿进程。此时一般由init进程作为父亲进程
僵尸进程
子进程在结束后,会释放掉自己程序/数据所占用的资源,但是PCB保留,给父进程来shoushi,父进程shoushi后会释放掉PCB,代码子进程已经完全结束了
为什么要shoushi:因为子进程会释放自己的资源除了PCB,但是可能会返回执行时间,状态码之类的父进程关心的数据,所以父进程为其shoushi
ZOMBIE:如果子进程死亡,父亲进程会子成功shoushi,那么正常退出。在shoushi的时候,父亲进程也exit。这个时候就没人为子进程shoushi,成为僵尸进程。需要init为其shoushi
父进程复制自己的地址空间(fork)传建一个新的(子)进程结构。每个新进程分配一个唯一的进程ID(PID),满足跟踪安全性之需,PID和父进程(PPID)是子进程环境的元素,任何进程都可以创建子进程,所有进程都是第一个系统进程的后代:
fork函数
返回值:如果fork函数调用失败,返回一个负数,调用成功则返回两个值:0和子进程ID。
函数功能:
以当前进程作为父进程创建出一个新的子进程,并且将父进程的堆栈段和数据段给子进程共享,这样子进程作为父进程的一个副本存在。父子进程几乎时完全相同的,但也有不同的如父子进程ID不同。
我们可以通过返回值判断是父进程执行还是子进程
id==0:执行父进程
id>0:在子进程中执行
id<0:fork函数调用失败
fork是分裂执行的
下面程序一共打印8次I’m a process.
int main(void)
{
pid_t pid1, pid2, pid3;
pid1 = fork();
pid2 = fork();
pid3 = fork();
printf(“I’m a process.\n”);’;;
return 0;
}
wait或者waitpid进行退出
fork:无论是fork,vfork,_clone实质上都是调用clone()-do_fork()-copy_process
copy_process:
1:调用dump_task_struct为新进程创建内核栈,thread_info,tast_struct
2:调整子进程的tast_struct里的进程描述符
3:根据clone_flags进程合法性检查
4:获取新的PID
5:设置进程地址空间等等
COW写时复制(copy_on_write)
父进程将堆栈段和数据段(页框)给子进程共享。
父进程和子进程共享页帧而不是复制页帧。然而,只要页帧被共享,它们就不能被修改,即页帧被保护。无论父进程还是子进程何时试图写一个共享的页帧,就产生一个异常,这时内核就把这个页复制到一个新的页帧中并标记为可写。此时实现分离
exec:系统调用execve()对当前进程进行替换,替换者为一个指定的程序,其参数包括文件名(filename)、参数列表(argv)以及环境变量(envp)一个进程一旦调用exec类函数,它本身就"死亡"了,系统把代码段替换成新的程序的代码,废弃原有的数据段和堆栈段,并为新程序分配新的数据段与堆栈段,唯一留下的,就是进程号
if ( fork() == 0 ) {/* 子进程执行此命令 */
execlp( command, NULL );
/* 如果exec函数返回,表明没有正常执行命令,打印错误信息*/
perror( command );
exit( errno );
}
else {/* 父进程, 等待子进程结束,并打印子进程的返回值 */
wait ( &rtn );
printf( " child process return %d\n", rtn );
}
因为如果调用exec,此时仍然要执行COW,没有必要
优化:“run the child process first”策略,在执行了fork()之后马上执行子进程。这种情况下,子进程马上执行exec类函数的话,将不用对可能有几十m大小的address space进行复制,省去了不必要的复制成本。
vfork和fork的区别:
1:fork:子进程拷贝父进程的代码段和数据段
vfork:子进程和父进程共享代码段和数据段
2:fork中父子进程的先后运行次序不定
vfork:保证子进程先运行,子进程exit后父进程才开始被调度运行
注意,vfork中的子进程必须调用exit
Task_struct
背景:触发任何一个事件时,系统都会将他定义成为一个进程,并且给予这个进程一个 ID ,称为 PID,同时依据启发这个进程的使用者与相关属性关系,给予这个 PID 一组有效的权限配置
注意:
1:运行的shell,其实也是一个程序形成进程,bin/bash程序,所以也有UID/PID等等
2:而在shell的输入的命令,实际上也就是一个文件[alias,bash内置的等等都是一个程序],所以也会形成一个进程
当这个程序执行完毕,会有标准输出,标准错误输出等,将这些输出到屏幕或者其他地方,进程结束
并且,子程序会继承父程序的环境变量,权限等
我们可以通过Ps -l:查看所有程序的属性
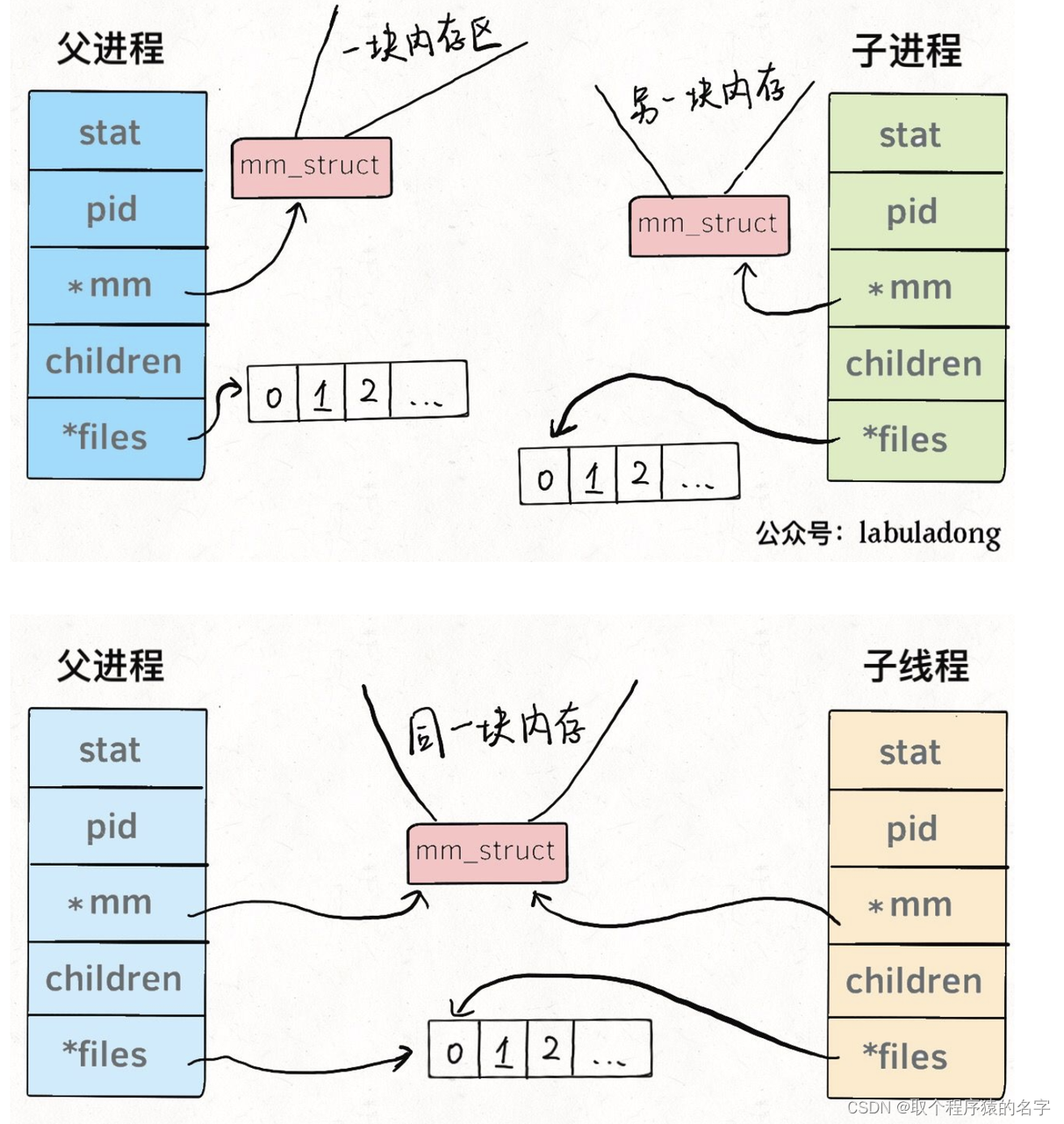
在 Linux 系统中,进程和线程几乎没有区别。
首先,两个都是使用一种结构体
struct task_struct {
// 进程状态
long state;
// 虚拟内存结构体
struct mm_struct *mm;
// 进程号
pid_t pid;
// 指向父进程的指针
struct task_struct *parent;
// 子进程列表
struct list_head children;
// 存放文件系统信息的指针
struct fs_struct *fs;
// 一个数组,包含该进程打开的文件指针
struct files_struct *files;
};
其中files文件描述符
一个进程会从files[0]读取输入,将输出写入files[1],将错误信息写入files[2]。
而标准的计算机,files的前三位被填入默认值,分别指向标准输入流、标准输出流、标准错误流。输入流是键盘,输出流是显示器,错误流也是显示器
也就是,进程会从键盘读取输入,将输出写到屏幕,将错误信息也写到屏幕
【混淆点:进程的文件描述符为指针,而指针具体所指向的地方是键盘,和屏幕。因为linux一切都是文件,所以键盘和屏幕也是文件,也可以输入输出】
这里补充解释一下重定向和管道
重定向:就是让file文件描述符指针的位置改变,指向其他地方
管道:
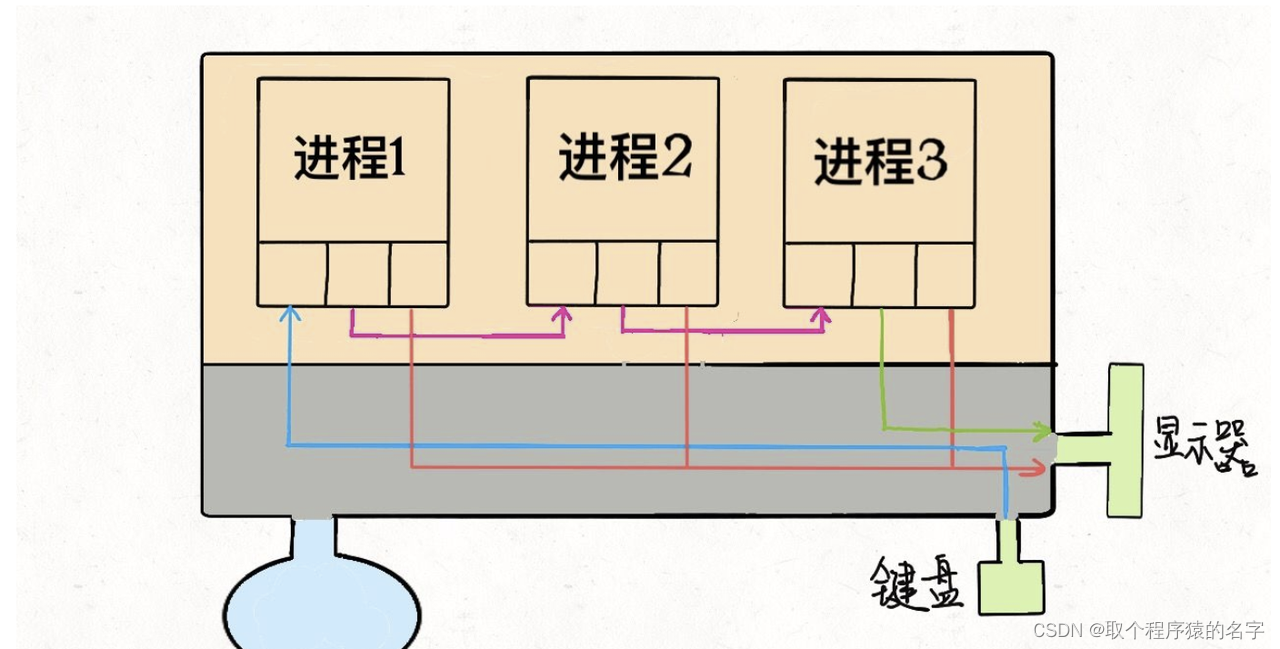
线程pthread和进程fork的区别:
8:配置文件和代理
首先主要的配置文件就是两类,一类是linux配置文件,一类是其他配置文件
- linux配置文件,约为四个:/etc/ ~/里的四个,里面的命令其实就是转为环境变量
- export 设置临时环境变量,unset 取消临时环境变量
- export -p 查看所有环境变量
其他配置文件: - git:有三类git的配置文件
- go:go env查看go的配置文件,设置的话需要export
代理:正向代理,反向代理。也就是主机无法请求,所以委托代理机进行请求
比如我在开发机上进行make run-boe
标准输入输出
shell/标准错误输出:
首先shell调用getchar等待用户输入
用户第一个输入的字符的是指令name,需要从path找到
用户第一个后输入的字符是参数,在linux脚本中用$123代替
回车后,开启一个进程执行,并看用户输入有没有&
如果没有,则阻塞等待进程执行完后,将输出打到shell中
如果有,则异步执行,主线程不会等待
Ps 看/bin/bash即为进程
Lsof -p可以看到拥有的文件,其中012分别代表标准输入输出,指向/dev中的设备文件
1:标准输入/输出
分为标准输入,输出,错误输出
输入指向键盘 0
输出指向屏幕 1
错误输出指向屏幕 2
我们可以重定向
find . -name “handler.go” 1>1.txt
表示将输出重定向到1.txt
1正确输出,2错误输出【1可忽略,即便 >1.txt就代表将输出定向到1.txt】
如果是想忽略,则定向到黑洞/dev/null
覆盖写
累加写
如果想输入到同一个文件:
[dmtsai@www ~]$ find /home -name .bashrc > list 2> list <==错误
[dmtsai@www ~]$ find /home -name .bashrc > list 2>&1 <==正确
[dmtsai@www ~]$ find /home -name .bashrc &> list <==正确
为什么错误,因为相当于两个线程同时写,造成混乱
输入指的是,在屏幕里输入,以ctrl+d结束输入
许多时候如果我们没有对命令指定对象,就相当于从标准输入设备中读取,例如上面的wc ,输入后,白色空行代表你的输入,ctrl+d结束输入
也可以将输入重定向到文件
cat > catfile < ~/.bashrc
指的是,将cat的输出重定向到catfile中。
而cat的输入重定向到~/.bashrc中
注意:输入/输出重定向都是到一个文件
linux启动过程:
Linux内核+GNU软件构成的操作系统
1:BIOS开机自检,按照BIOS中设置的启动设备(通常是硬盘)来启动
包含了CPU的相关信息、设备启动顺序信息、硬盘信息、内存信息、时钟信息、PnP特性
2:找到MBR扇区(512B),复制到内存中得到Boot Loader(446B),运行(grub第一阶段)
硬盘上第0磁道第一个扇区被称为MBR,也就是Master Boot Record,即主引导记录。预启动信息、分区表信息等。初始化硬件设备、建立内存空间的映射图,从而将系统的软硬件环境带到一个合适的状态【操作系统】
3:读取grub配置信息(/boot/gurb),并依照此配置信息来启动不同的操作系统(grub第二阶段)
4:加载内核(/boot中)。grub设定的内核映像所在路径,系统读取内存映像调用start_kernel()初始化
5:读取配置文件 /etc/inittab,运行init进程。设定Linux的运行等级(0关机,1单用户模式等)
6::rc.sysinit等脚本进行配置
7:启动终端
关机:
sync将数据由内存同步到硬盘中 > shutdown
内存管理
用户空间和内核空间
首先进程能够操控的都是虚拟内存,如果4G的虚拟内存,则3G为用户空间,高地址1G为内核空间。
用户在用户态只能使用用户空间,在内核态能使用内核空间。
对于linux的用户空间,是按照段页式存储的
task_struct>mm>vm_struct>(vm_end,vm_begin),vm_struct就相当于段,具体再分为页式存储
对于linux的内核空间,是按照映射的。高端内存映射到物理内存的低端地址。那么内核空间只有1G,是不是只能使用物理内存的低端1G吗?不是这样的,内核空间分为高端内存,低端内存。其中低端内存遵循上述的一一映射,但是高端内存是不能直接访问的,高端内存是映射访问,也就是可以映射到物理内存的任意一段,使用完后就释放即可
用户空间和内核空间的数据隔离:
IO的时候,是需要进入内核态的,将IO数据加载到内核空间3-4G,同时CPU需要将内核空间的数据拷贝到用户空间0-3G,用户态的进程才能使用。所以本质上,数据隔离指的是虚拟空间隔离
如何管理和分配
物理内存管理:
分页机制:大小为4k
数据结构:struct page,系统中所有的页面都存储在数组mem_map[]中。
而其中的空闲页面则可由上述提到的以伙伴关系组织的空闲页链表(free_area[MAX_ORDER])来索引。
伙伴关系分配算法:所有的空闲页框分为11个块链表,第0个块链表包含大小为2^0个连续的页框,第1个块链表中,每个链表元素包含2个页框大小的连续地址空间,….,第10个块链表中,每个链表元素代表4M的连续地址空间
分配页面:若分配4(2^2)页(16k)的内存空间,算法会先从free_area[2]中查看nr_free是否为空,如果有空闲块,则从中分配,如果没有空闲块,就从它的上一级free_area[3](每块32K)中分配出16K,并将多余的内存(16K)加入到free_area[2]中去]。以此类推
释放页面:当释放一个内存块时,先在其大小相同的的free_area链表中查找是否有伙伴存在,如果没有伙伴块,直接将释放的块插入链表头。如果有或板块的存在,则将其从链表摘下,合并成一个大块,然后继续查找合并后的块在更大一级链表中是否有伙伴的存在,直至不能合并或者已经合并至最大块2^10为止。
进程的空间管理
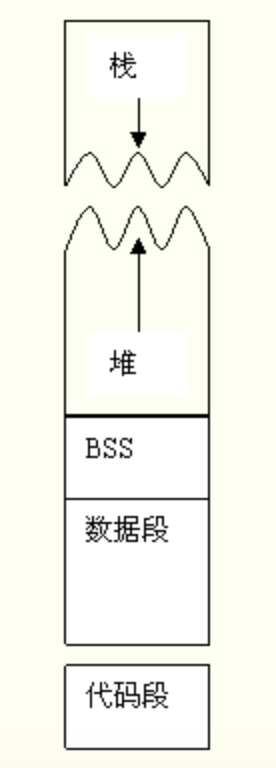
进程由五部分组成:
代码段
数据段:存放静态变量和全局变量。
BSS段:未初始化的全局变量,在内存中 bss段全部置零。
堆:动态分配的内存段。malloc-free
栈:局部变量函数{}中变量
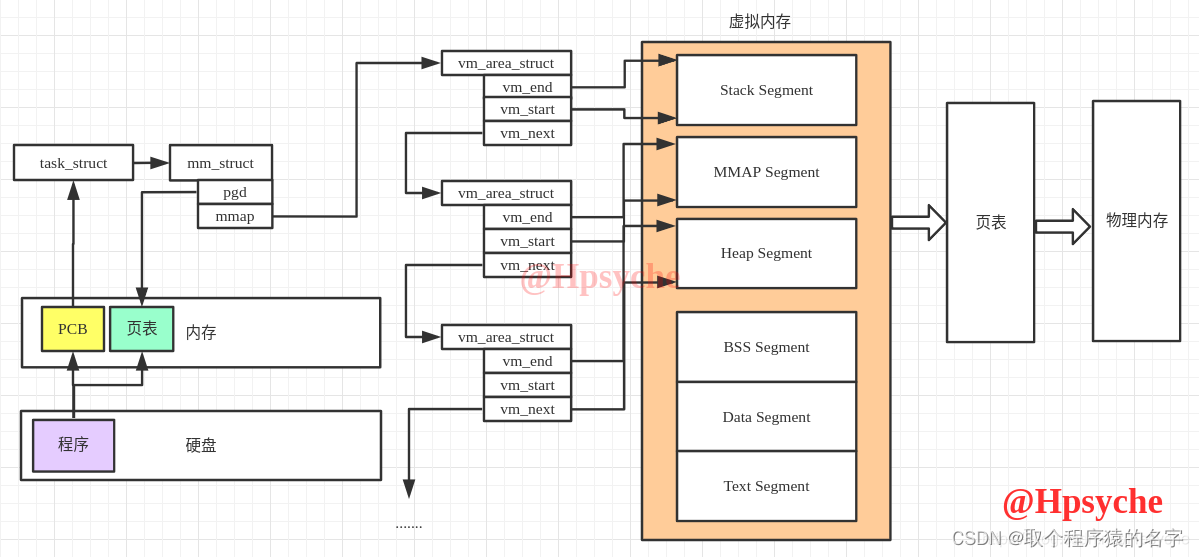
虚拟内存:
每个内存有独立的用户空间,共享内核空间
内核空间页表(init_mm.pgd),用户进程各自有不同的页表。
用户空间从0到3G,内核空间占据3G到4G
用户空间分配:
虚拟空间被划分为许多大小可变的内存区域(memory region)或者叫VMA就是页
这些区域的划分原则是“将访问属性一致的地址空间存放在一起”,所谓访问属性在这里无非指的是“可读、可写、可执行等”。
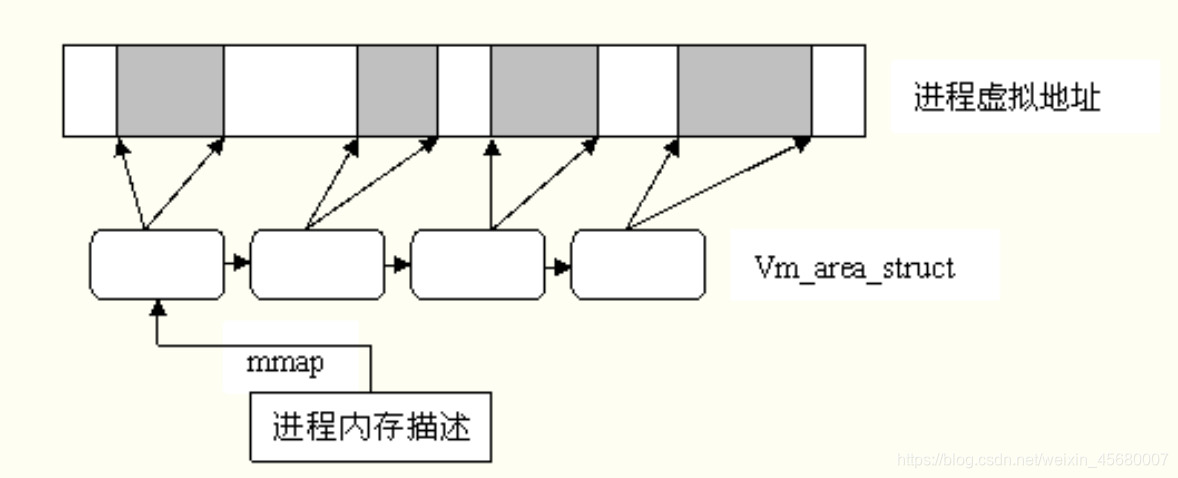 内存区域的数据结构: vm_area_struct
内存区域的数据结构: vm_area_struct
可以理解为每个vm_area_struct就是一个段,对应多个页
vm_area_struct的组织两种数据结构:链表,红黑树链表用于需要遍历全部节点的时候用,而红黑树适用于在地址空间中定位特定内存区域的时候
内存描述符结构:表示进程的全部地址空间
分配方法:do_mmap()可能是创建一个DMA,也可能是合并一个DMA
转化:
虚拟地址——》物理地址
时机:进程真的去访问新获取的虚拟地址时,才会由“请求页机制”产生“缺页”异常,从而进入分配实际页面的例程。
nopage:为进程分配物理页,并建立对应的页表,将虚拟地址转化到物理内存上
页表:32位10/10/12,64位9/9/9/9/12(64位逻辑地址转化为48位线性地址)
内核地址管理
往往是很小(远远小于一页)的内存块——比如存放文件描述符、进程描述符、虚拟内存区域描述符等行为所需的内存都不足一页
方式:Slab分配器
Kmalloc:对于小内存块。利用存储池技术,内存片段(小块内存)被看作对象,当被使用完后,并不直接释放而是被缓存到“存储池”里,留做下次使用
Vmalloc:对于大对象。vmalloc函数分配内核虚拟内存,对内核虚拟地址进行重映射,必须更新内核页表
内部分片:为了满足一小段内存区(连续)的需要,不得不分配了一大区域连续内存给它,从而造成了空间浪费。由Kmalloc解决
外部分片:是指系统虽有足够的内存,但却是分散的碎片,无法满足对大块“连续内存”的需求。由Vmalloc解决
文件管理
Windows: 以多根的方式组织文件 C:\ D:\ E:
Linux: 以单根的方式组织文件 /
bin 普通用户使用的命令 /bin/ls, /bin/date
sbin 管理员使用的命令 /sbin/service
dev 设备文件
root root用户的HOME
home 存储普通用户家目录
proc 虚拟的文件系统
usr 系统文件,相当于C:\Windows
/usr/local 软件安装的目录,相当于C:\Program
/usr/bin 普通用户使用的应用程序
boot 存放的系统启动相关的文件,例如kernel,grub(引导装载程序)
etc 配置文件
lib 库文件Glibc
lib64 库文件Glibc
tmp 临时文件(全局可写:进程产生的临时文件)
var 存放的是一些变化文件,比如数据库,日志,邮件…
mysql: /var/lib/mysql
通过颜色判断文件的类型是不一定正确的
Linux系统中文件是没有扩展名
方法一:ls -l 文件名 //看第一个字符【在读写权限左面】
- 普通文件(文本文件,二进制文件,压缩文件,电影,图片。。。)
d 目录文件(蓝色)
b 设备文件(块设备)存储设备硬盘,U盘 /dev/sda, /dev/sda1
c 设备文件(字符设备)打印机,终端 /dev/tty1
s 套接字文件
p 管道文件
l 链接文件(淡蓝色)
方法二:file
初始化:boot loader初始化
分区管理:
fdist /dev/hda:指定磁盘文件
进入磁盘管理命令界面
d删除分区
p创建分区
mke2fs /dev/hda6格式化分区:
将分区划分为block和group.block为分区的最小单位,group是block的集合
super block(超级块):具体划分为多少个block和group
扇区:512B
Block:4K
文件的元信息:inode
文件类型,UID,GID,文件大小,文件使用的磁盘块的实际数
每一个文件都有一个对应的inode
stat 查询某个文件的inode信息
所以硬盘在分区的时候会分为两个区域,一个区域存放数据,一个区域存放inode信息。
文件系统层次:
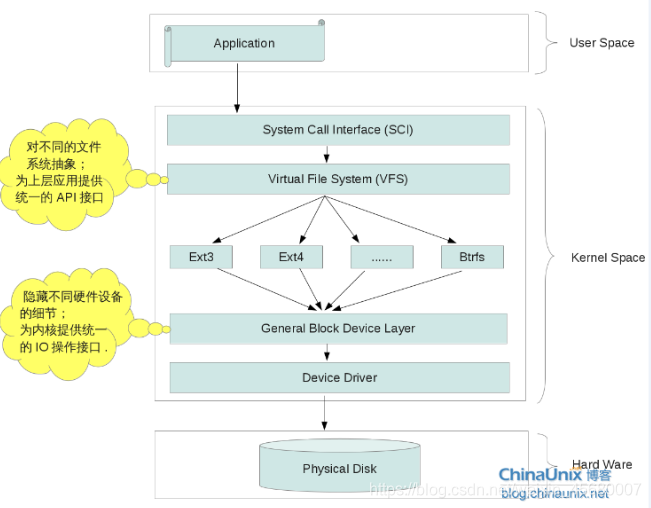
-
General Block Device Layer
不同硬盘不同驱动介质结构不同:
将其都看作块设备来处理。 -
虚拟文件系统(VFS)
不同文件系统都有各自的API接口
提供统一的API访问接口,
打开文件的步骤:
1:查找文件的inode编号
2:根据inode编号,找到inode信息
3:根据inode信息找到文件对于所在的block,进行数据的读写。
inode节点的数量在硬盘格式化的时候就已经给定了。当Linux上创建文件过多时,就可能发生inode用光,无法创建新文件的问题。
维护打开文件列表模块,包含所有内核已经打开的文件。已经打开的文件对象由open系统调用在内核中创建,也叫文件句柄
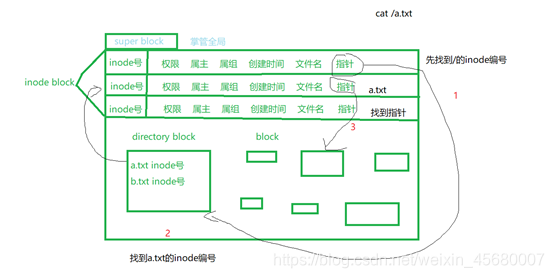
删除文件:i_link 硬链接数为0 并且 i_count 进程引用计数也为0
挂载指的是在linux系统中,磁盘分区后,需要将其挂载到其它目录下,才可以进行访问
将设备文件中的顶级目录连接到 Linux 根目录下的某一目录(最好是空目录),访问此目录就等同于访问设备文件如果不挂载,通过Linux系统中的图形界面系统可以查看找到硬件设备,但命令行方式无法找到。
创建文件:
- 存储属性 也就是文件属性的存储,内核先找到一块空的i-节点。例如,内核找到i-节点号921130。内核把文件的信息记录其中。如文件的大小、文件所有者、和创建时间等。
- 存储数据 即文件内容的存储,由于该文件需要3个数据块。因此内核从自由块的列表中找到3个自由块。如600、200、992,内核缓冲区的第一块数据复制到块600,第二和第三分别复制到922和600.
3)分配情况记录在文件的i-节点中的磁盘序号列表里。这3个编号分别放在最开始的3个位置 - 添加文件名到目录,新文件的名字是userlist 内核将文件的入口(47,userlist)添加到目录文件里。文件名和i-节点号之间的对应关系将文件名和文件和文件的内容属性连接起来,找到文件名就找到文件的i-节点号,通过i-节点号就能找到文件的属性和内容(挂载)
创建目录:
- 系统找到空闲的i-节点号887220,写入目录的属性
- 找到空闲的数据块1002来存储目录的内容,只是目录的内容比较特殊,包含文件名字列表,列表一般包含两个部分:i-节点号和文件名,这个列表其实也就是文件的入口,新建的目录至少包含三个目录”.”和”…”其中”.”指向自己,”…”指向上级目录,我们可以通过比较对应的i-节点号来验证,887270 对应着上级目录中的child对应的i-节点号
- 记录分配情况。这个和创建文件完全一样
- 添加目录的入口到父目录,即在父目录中的child入口。
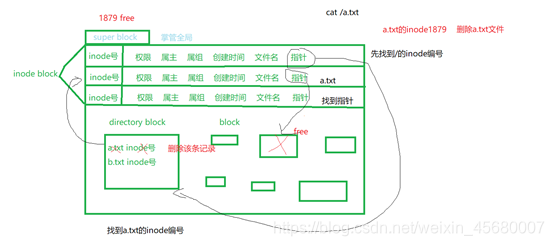
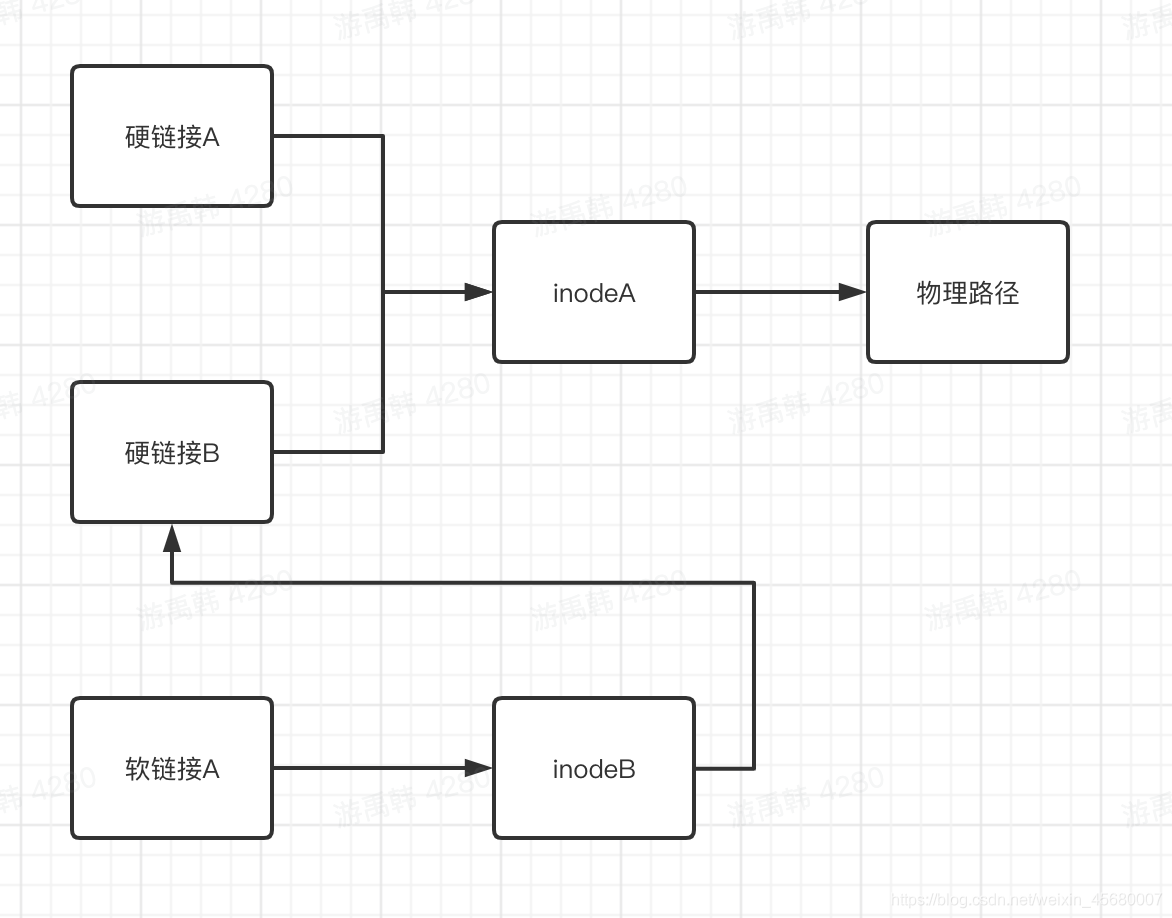
硬连接:
通过原文件的文件名找到文件的i-节点号
添加文件名关联到目录,新文件的名字是mylink 内核将文件的入口(921130,mylink)添加到目录文件里。
相同硬链接指向相同的inode节点
stat 文件名

有一个count,当删除文件的时候,count–,只有count=0才删除inode和指向的文件
软连接:快捷方式
具体来说,软链接指向一个不同的inode,inode里面的内容指向另一个文件的文件名字[不是inode也不是block,因为删除这个inode已经没法访问了,即使有其他硬链接]
#创建text.md文件
touch test.md
#创建一个硬连接
ln test.md hardlink.md
#创建一个软连接
ln -s test.md softlink.md
IO设备管理
IO系统的设备管理:
linux的一切皆文件的思想:
dev/
打印机:lp
控制台终端:console
磁盘高速缓存(内存):在磁盘读数据,先在缓冲中读。如果没有,先
数据从磁盘到高速缓存区,进程再到高速缓冲读取数据
写数据时,延迟写,缓冲区写满才写磁盘
缓冲区:空闲缓冲区队列(一个)和设备缓冲区队列(多个)
结构:双向链表
当某设备缓冲区写完后,进入空闲缓冲区队尾并且仍然保留在设备缓冲
区队列中,因为数据可能再次使用。
使用的话,同时从设备和空闲缓冲区队列中取出
其他
环境变量
配置文件
环境变量
查看:env/echo 能够在$识别的变量/
方法一:利用四大配置文件进行配置【永久】
方法二:利用export进行配置【临时】set,unset
设置命令:export
P
A
T
H
=
PATH=
PATH=GOPATH/bin:$PATH
注意点:
1:不同用户配置的path可能不同, 所以会产生不同用户命令运行不一致等各种bug
2:命令必须放在path中才可以生效(访问到)
3:export还可以进行简写路径的作用
注意:利用export进行配置,关闭shell后失效。
原因在于环境变量在进程中是伴随着进程的
父亲fork时候会把环境变量传递给子进程,子进程会单独存储环境变量。但是子进程export时,不会影响父亲进程的
命令的执行——Path
为什么我可以在任何地方运行/bin/ls这个命令呢?
对于一般的命令,系统会依照PATH的配置去每个PATH定义的目录下搜寻档名为ls的可运行档, 如果在PATH定义的目录中含有多个档名为ls的可运行档,那么先搜寻到的同名命令先被运行!
查看path:
echo $PATH
配置path:
利用四大配置文件进行配置
开启shell,会依次执行/etc/profile,/etc/bashrc。并且如果两个有相似配置(alias),以/etc/profile为准
当切换用户的时候,会读取/.bash_profile,/.bashrc
1所有用户的环境变量/etc/profile:第一次登陆时读取
2所有用户的环境变量/etc/bashrc:shell打开时,文件执行
3当前用户的环境变量~/.bash_profile:
4当前用户的环境变量~/.bashrc:当登录时以及每次打开新的shell时,该文件被读取
命令的运行顺序:
- 以相对/绝对路径运行命令,例如『 /bin/ls 』或『 ./ls 』;
- 由 alias 找到该命令来运行;
- 由 bash 内建的 (builtin) 命令来运行;
- 透过 $PATH 这个变量的顺序搜寻到的第一个命令来运行。
易错点:明明之前安装了kitool,为什么今天使用的时候发现command not found?
原因是之前使用的zash维护一套环境变量path,切换到bash后有一套新的环境变量path。所以可能新的path没有指向二进制文件kitool的文件,所以命令不存在
更深一步的理解:命令本质上就是一个二进制程序,可执行程序
所以,和我们的代码一样,对于一个命令,首先其实就是程序,需要下载
go get github.com/golang/mock/gomock
下载成功后,进行go build,生成二进制可执行程序,之后将这个程序移动到PATH目录下,
mv mockgen $GOPATH/bin
才可以执行
; 连续执行
& 表示任务在后台执行,如要在后台运行redis-server,则有 redis-server &
&& 表示前一条命令执行成功时,才执行后一条命令 ,如 echo '1‘ && echo ‘2’
| 表示管道,上一条命令的输出,作为下一条命令参数,如 echo ‘yes’ | wc -l[类似于取代标准设备的输入 ]
|| 表示上一条命令执行失败后,才执行下一条命令,如 cat nofile || echo “fail”
硬链接,软链接
创建
本质
修改
删除原文件
硬链接
ln test.txt copy1.txt
存储的是索引节点的位置
会修改
无影响
软链接
ln -s test.txt copy2.txt
存储的是文件的路径
会修改
影响,失效
硬链接存储的是索引节点的位置,软链接存储的是文件的路径
touch test.txt
ln test.txt copy1.txt //硬链接
ln -s test.txt copy2.txt //软链接
ls- il
可以看到硬链接和普通文件是没有区别的,软链接是会显示l,并且有明确箭头的指向
修改:无论是修改硬连接还是软连接,如果修改了任意一个的值,所有的值都会改变
删除:删除硬链接,不会影响其他硬链接,但是会影响软链接,软链接会变成红色
文件权限
Linux中权限(r、w、x)对于目录与文件的意义
一、权限对于目录的意义
1、r权限:拥有此权限表示可以读取目录结构列表,也就是说可以查看目录下的文件名和子目录名,注意:仅仅指的是名字
2、x权限:
- 拥有目录的x权限表示用户可以进入该目录成为工作目录,能不能进入一个目录,只与该目录的x权限有关,如果用户对于某个目录不具有x权限,则无法切换到该目录下,也就无法执行该目录下的任何命令
- 能否查看目录内文件的具体信息
3、w权限:具体如下:
1)在该目录下新建新的文件或子目录。
2)删除该目录下已经存在的文件或子目录(不论该文件或子目录的权限如何),注意:这点很重要,用户能否删除一个文件或目录,看的是该用户是否具有该文件或目录所在的目录的w权限
注意:子目录/子文件能否删除取决于父目录的w权限,如果仅仅有爷目录的w权限,没有父目录的w权限,也不能删除孙文件
3)将该目录下已经存在的文件或子目录进行重命名。
4)转移该目录内的文件或子目录的位置。
二、权限对于文件的意义
1、也应该明白的是文件是实际含有数据的地方,所以r、w、x权限对文件来说是与其内容有关的。
2、r权限:用于此权限表示可以读取此文件的实际内容。
3、w权限:拥有此权限表示可以编辑、添加或者是修改该文件的内容。但是不包含删除该文件,因为由上面权限对于目录的意义得知删除文件或目录的条件是什么。
4、x权限:表示该文件具有可以被系统执行的权限。文件是否能被执行就是由该权限来决定的,跟文件名没有绝对的关系。
shell
参考文章
Shell表达式:批量操作场景下使用,利用文本记录操作执行批量指令。一些基本的需要了解,其他的使用的时候再看吧,不大好记住
-
使用参数:
$():内部为命令,命令的输出赋值
: 内 部 为 变 量 , 等 同 于 {}:内部为变量,等同于 :内部为变量,等同于。可以作为路径等等 -
输入参数:
方式一:利用read read -p “Input a filename : " filename
方式二:运行的时候后接参数
@ 参 数 全 部 内 容 , @ 参数全部内容, @参数全部内容,#参数个数, 1 第 一 个 参 数 I f e l s e : i f [ " 1第一个参数 Ifelse: if [ " 1第一个参数Ifelse:if["yn” == “Y” ] || [ “$yn” == “y” ]; then
echo “OK, continue”
exit 0
fi
Case:
case $1 in
“hello”)
echo “Hello, how are you ?”
;;
“”)
echo “You MUST input parameters, ex> {$0 someword}”
;;
*)
echo “Usage $0 {hello}”
;;
esac -
demo:
!/bin/bash
自动化代码仓库的GDPR鉴权
list=cat $1
for val in $list
do
rm -rf gdpr
git clone $val gdpr
cd gdpr
git branch feat-add-gdpr
git checkout feat-add-gdpr
go get code.byted.org/kv/goredis@v5.1.0
go get code.byted.org/kv/redis-v6@master
go get code.byted.org/gopkg/consul@v1.1.9
go get code.byted.org/gopkg/pid@v0.0.7
git add .
git commit -m “GDPR鉴权-redis”
git push origin feat-add-gdpr
cd …
rm -rf gdpr
done
配置文件和代理
首先主要的配置文件就是两类,一类是linux配置文件,一类是其他配置文件
- linux配置文件,约为四个:/etc/ ~/里的四个,里面的命令其实就是转为环境变量
- export 设置临时环境变量,unset 取消临时环境变量
- export -p 查看所有环境变量
其他配置文件: - git:有三类git的配置文件
- go:go env查看go的配置文件,设置的话需要export
代理:正向代理,反向代理。也就是主机无法请求,所以委托代理机进行请求
比如我在开发机上进行make run-boe
consulCache [toutiao.mysql.card_write] error consul: connection refused (try set CONSUL_HTTP_HOST in dev env)
报错如上,这里和服务发现原理类似,因为Consumer无法请求到注册中心,自然无法获取信息。
所以需要设置代理CONSUL_HTTP_HOST,委托代理进行请求【这种情况下,找一台能够sd lookup psm的机器作为代理即可】
同理的,下述http也是利用的代理,也就是http请求都通过代理进行请求和接收
export http_proxy=10.20.47.147:3128 https_proxy=10.20.47.147:3128
。查看CPU,内存的使用率 top:top ppid是父进程,ppid=1说明父亲进程是linux-init进程。实时,占用资源比较多
查看所有进程ps -A:快照,占用资源比较少
目录含义
Shell:是系统的用户界面,提供了用户与内核进行交互操作的一种接口(命令解释器)
Bash是一种常用的shell
目前结构:
bin 存放二进制可执行文件(ls,cat,mkdir等)
boot 存放用于系统引导时使用的各种文件
dev 用于存放设备文件
etc 存放系统配置文件
home 存放所有用户文件的根目录
lib 存放跟文件系统中的程序运行所需要的共享库及内核模块
mnt 系统管理员安装临时文件系统的安装点
opt 额外安装的可选应用程序包所放置的位置
proc 虚拟文件系统,存放当前内存的映射
root 超级用户目录
sbin 存放二进制可执行文件,只有root才能访问
tmp 用于存放各种临时文件
usr 用于存放系统应用程序,比较重要的目录/usr/local 本地管理员软件安装目录
var 用于存放运行时需要改变数据的文件
而不同用户实际上的/home下的不同目录
mmap
mmap和零拷贝
参考:https://juejin.cn/post/6962404435620266015
传统的是read+write方法
正常流程:
read:磁盘->页缓存->用户空间 用户态-内核态-用户态
write:用户空间->Socket缓存->IO 用户态-内核态-用户态
引入了mmap
mmap:内存映射文件。将用户程序的虚拟地址映射为内核空间中(具体来说是页缓存中)【传统的做法,是用户程序的虚拟地址映射到用户空间,用户空间再拷贝到页缓存中】。在实现上也是可行的,因为从虚拟地址上0-3G是用户,3-4G是内核,只要有个映射就好。
所以mmap+write代替传统的是read+write方法,少了一次CPU拷贝
mmap+write:
mmap:磁盘->页缓存 用户态-内核态-用户态
write:页缓存 ->Socket缓存->IO 用户态-内核态-用户态
SendFile代替mmap+write,减少一次用户内核切换
磁盘->页缓存-> Socket缓存->IO 用户态-内核态-用户态
命令
操作指令
- wc
利用wc指令我们可以计算文件的Byte数、字数、或是列数,若不指定文件名称、或是所给予的文件名为"-",则wc指令会从标准输入设备读取数据
echo ‘yes1231231312414 2142141’ | wc -w
-w:字符 /-l:行 -c:字节
-
zash
shell可以有不同的方式,具体存储在/etc/shells里
zash:自动补全功能
https://www.cnblogs.com/yuanfang0903/p/12915662.html
chsh -s /bin/bash:需要重新开启shell -
find
Find
find . -name “*.c” 将目前目录及其子目录下所有延伸档名是 c 的文件列出来
find . -type f 将目前目录其其下子目录中所有一般文件列出
./:当前目录以及子目录
-maxdepth 1:当前目录 find . -maxdepth 1 -name *.conf
“c”:通配符匹配 -
chmod权限
chgrp:改变文件的属组
sudo chgrp -R admin container/$0
chown:改变文件的所有者,属组
sudo chown -R newuser container/
chmod:改变文件的权限
sudo chmod -R 777 container
其中421分别是读写执行,对于目录的执行,就指的是能否进入这个目录
-R:递归
-
Less:
/字串 :向下搜寻『字串』的功能;
?字串 :向上搜寻『字串』的功能;
n :重复前一个搜寻 (与 / 或 ? 有关!)
N :反向的重复前一个搜寻 (与 / 或 ? 有关!)
\可以进行换行 -
管道命令|
|进行表示,代表将|前的标准输出作为|后的标准输入
如果需要既保留为文件,也传递给后面的标准输入,该咋做?
ls -l /home | tee ~/homefile | more
一方面存储到~/homefile中,一方面作为more的展示
如果需要进行对输入的修饰,可以参考
http://cn.linux.vbird.org/linux_basic/0320bash_6.php
比较重要的:cut,grep,sort,wc
cut -d’分隔字符’ -f fields <==用于有特定分隔字符
cut -c 字符区间 <==用于排列整齐的信息
export |cut -c 12-
echo $PATH | cut -d “:” -f 1
-
grep
Grep:以行为单位进行截取
-i :忽略大小写
-v:反向选择
正则匹配:可参考
常用的
[]:内的字节出现一次
.:一个字节
*:0个或者多个字节
^:首部字节/取反
1首部以【】开头
[^ ]不出现[]
http://cn.linux.vbird.org/linux_basic/0330regularex_2.php -
&
后台执行程序:grep -r “find” .&
&表示将程序背景执行,当程序执行完后,回提示用户
jobs:查看所有工作
ctrl+z:将前景的进程转化为stopped的
fg:将程序从背景到前景
bg:将程序从背景暂停到背景运行
kill:
kill -9 %1
-9 这个 signal 通常是用在『强制删除一个不正常的工作』时所使用的, -15 则是以正常步骤结束一项工作(15也是默认值)
- 程序查看
ps -l
Ps -aux
PRI/NI:CPU调度的优先级
S:status
-
S 处于休眠状态
-
T 停止或被追踪
-
s 包含子进程
-
- 位于后台的进程组
-
文件处理
Grep:可以利用正则进行匹配
-r :递归
-i :忽略大小写
-w:精确匹配
Sed:文本替换
Linux sed 命令 | 菜鸟教程
Awk:文本分析工具
Sed [-F] ‘[pattern]{action}’ file
-F:指的是分隔符,用于切分每一行
pattern:匹配操作,符合匹配的行才会进入到action中遍历模式匹配
action:对每一行进行的操作,可以进行循环的等操作action操作
Demo:
awk -F ‘"’ ‘{for(i=1;i<=NF;i++){if($i~/pstatp/)print $i;}}’ log 1>pstatp.txt
- curl
Curl -0=wget:下载文件并且保存,并且注意curl的query需要转义拼接
curl -0 https://1psksyaf.fn.bytedance.net?method=user_action&action=download&did=2163433035804190&start_time=1622190000&end_time=16221900

















 3632
3632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









