



📢 家人们谁懂啊!现在的AI不仅能看图说话,还能自创表情包(真·脑洞比黑洞大)。今天咱们用"暴躁版科普"拆解多模态LLM原理,建议搭配82年的小文哥的酒食用⬇️
🔥Part 1:百亿参数的"套娃"艺术——多模态LLM的推理流程(GPU都干烧了!)
以DeepSeek多模态版为例,推理流程宛如炼丹师搓火球:
-
前方核能预警(输入阶段)
- 图片:被视觉ViT模型剁成16x16的像素块(仿佛菜刀切土豆)
- 文本:被Tokenizer拆解成语素[CLS][SEP]UNK
(某程序员os:ViT这切图方式比我妈切西瓜还残暴)
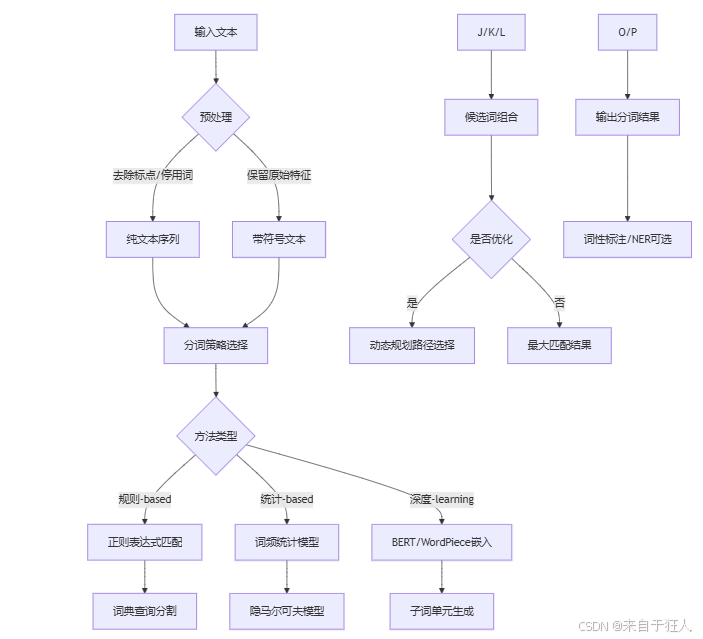 ps:哈哈哈哈看不懂吧
ps:哈哈哈哈看不懂吧
-
跨模态贴贴现场(特征融合)
DeepSeek祭出跨模态注意力矩阵:当文生图时:文本词向量vs图像patch键值对疯狂互动(这比相亲角还热闹)
当图生文时:图像特征劫持了文本输出的概率分布(霸道总裁强制爱既视感) -
暴力解码环节(Transformerの咏唱)
每一层transformer都在搞"量子纠缠":# 简化版解码代码(伪代码) while token != "[EOS]": 预测结果 = 数学魔法(图像特征 × 文本权重 + 位置编码) 选择概率 = roulette_wheel(防止输出变精神污染) (程序员注:这个while循环让显存哭晕在厕所)(网友辣评:像极了考试时瞎蒙选择题的我)
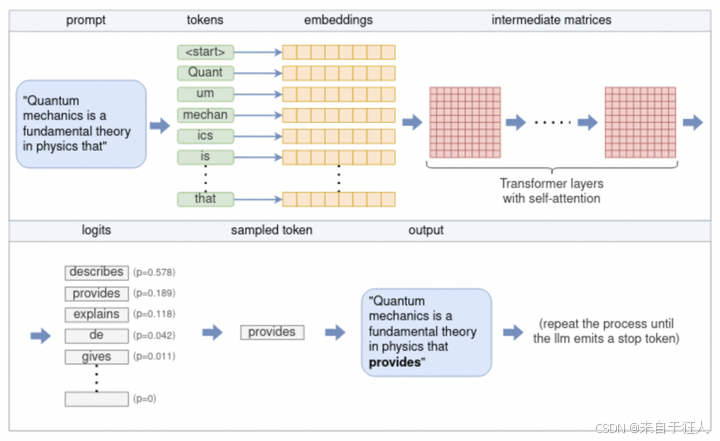 正经的LLM的推理流程,“魔塔的图”
正经的LLM的推理流程,“魔塔的图”
🤯Part 2:多模态LLM的"作弊器"原理(内含行业不能说的秘密)
🧠 黑科技1:注意力熔断机制
DeepSeek的跨模态Attention自带"开关" 👉 根据输入动态冻结80%注意力(内心os:躺平才是效率密码)
学术名:Mixture-of-Experts (MoE)
实际效果:比原神抽卡还看脸的选择性激活
🌉 黑科技2:玄学特征桥接
用CLIP-style对比学习把文字和图片硬锁CP:
图像向量 - 文本向量 = 余弦相似度² + 欧氏距离³(数学の魔法咒语)
(打工汪落泪:这公式比女朋友的心思还难懂)
⚡ 黑科技3:FlashDecoding暴击
参考vLLM的PagedAttention技术👉把KV Cache塞进虚拟内存(堪比把大象装冰箱的分步教学)
实验数据:吞吐量↑300%,时延↓50%(老板狂喜.jpg)
🚀Part3:行业の骚操作盘点
- GPU极限压榨术:QLoRA量化让模型暴瘦90%(医美看了都直呼专业)
- 推理玄学大法:temperature调到0.7后AI秒变人间清醒(别问,问就是超参数调参の神秘力量)
- 硬件省钱秘籍:用异构计算让GPU/TPU/NPU上演"宫斗剧"(端水大师の硬件管理哲学) "V我50查看隐藏秘籍”
- 各种量化的模型:某些模型的回答准确度:“妈妈生的!”
📈未来预言(暴论预警):
2025年多模态LLM终将进化成👉赛博炼金术师:
- 看图写诗只是基操(鲁迅看了都点外卖)
- 视频生成自带剧情解说(导演要集体转行送外卖?)
- 跨模态RLHF让AI学会阴阳怪气(某乎用户恐成最大受害者)
(掀桌)写到这里才发现:DeepSeek的技术文档比《百年孤独》的人物关系还复杂!建议各位看官点个收藏,下次看不懂的时候…再看一遍呗(狗头保命)。免责声明:我不生产博客只不过是ai的搬运工,有错的就是ai写的



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









