




| 主机IP |
角色 |
所属服务层 |
部署服务 |
| 192.168.11.11 |
日志生产 |
采集层 |
filebeat |
| 192.168.11.12 |
日志缓存 |
数据处理层、缓存层 |
Zookeeper+kafka+logstash |
| 192.168.11.13 |
|||
| 192.168.11.14 |
日志展示 |
持久、检索、展示层 |
Logstash+elasticsearch+kibana |
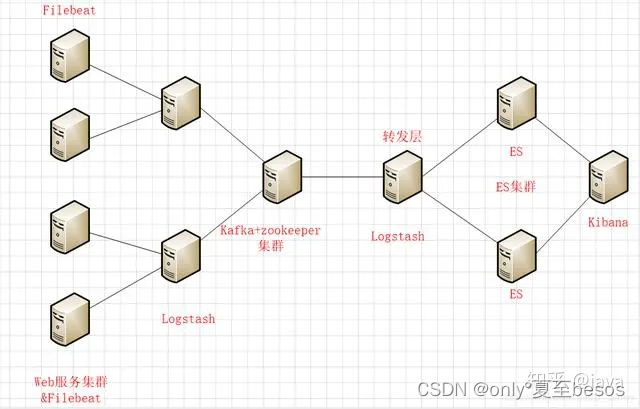
数据流向 filebeat---->logstash---->kafka---->logstash---->elasticsearch
第一层:数据采集层
最左边的是业务服务器集群,上面安装了filebeat做日志采集,同时把采集的日志分别发送给两个logstash服务
第二层:数据处理层,数据缓存层
logstash服务把接收到的日志经过格式处理,转存到本地的kafka broker+zookeeper集群中
第三层:数据转发层
单独的logstash节点会实时去kafka broker集群拉数据,转发至ES DataNode
第四层:数据持久化存储
ES DataNode会把收到的数据,写磁盘,建索引库
第五层:数据检索,数据展示
ES Master + Kibana主要协调ES集群,处理数据检索请求,数据展示
部署ELK
ELK集群部署(略)
ELK集群配置
(1)配置logstash
[root@zookeeper01 ~]# cd /data/program/software/logstash
[root@zookeeper01 logstash]# cat conf.d/logstash_to_es.conf
input {
kafka {
bootstrap_servers => "192.168.11.12:9092,192.168.11.13:9092"
topics => ["ecplogs"]
}
}
output {
elasticsearch {
hosts => ["192.168.11.12:9200","192.168.11.13:9200"]
index => "dev-log-%{+YYYY.MM.dd}"
}
}
注: ecplogs字段是kafka的消息主题,后边在部署kafka后需要创建
部署zookeeper+kafka+logstash
1、部署zookeeper集群
[webapp@localhost ~]$ tar -xzf zookeeper-3.4.9.tar.gz -C /data/webapp/
[webapp@localhost ~]$ cd /data/webapp/zookeeper-3.4.9/conf/
[webapp@localhost conf]$ cp zoo_sample.cfg zoo.cfg
[webapp@localhost conf]$ vim zoo.cfg
dataDir=/data/webapp/zookeeper-3.4.9/zookeeper
server.1=192.168.11.12:12888:13888
server.2=192.168.11.13:12888:13888
[webapp@localhost conf]$ echo 1 > /data/webapp/zookeeper-3.4.9/zookeeper/myid注:在另外一台配置文件相同,只需要将myid重置为2
[webapp@localhost conf]$ echo 2 > /data/webapp/zookeeper-3.4.9/zookeeper/myid2、启动zookeeper服务(在两台服务器中都启动)
[webapp@localhost zookeeper-3.4.9]$ bin/zkServer.sh start2.1、查看两台zookeeper集群状
[webapp@localhost zookeeper-3.4.9]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/webapp/zookeeper-3. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1160
1160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









