




 该博客主要围绕Hive SQL进行超前点播数据分析,包括统计每日购买笔数、金额、人数及新老用户,计算忠实与普通用户的平均购买集数,以及分析用户最大连续追剧天数的用户分布。内容涵盖视频应用的用户行为分析和指标体系设计。
该博客主要围绕Hive SQL进行超前点播数据分析,包括统计每日购买笔数、金额、人数及新老用户,计算忠实与普通用户的平均购买集数,以及分析用户最大连续追剧天数的用户分布。内容涵盖视频应用的用户行为分析和指标体系设计。
hiveSQL面试题整理学习(4)
背景说明:
用户在腾讯视频APP观看超前点播视频需付费购买,生成相应的购买流水表 (每次购买均对应一笔流水),表名为:cover_pay_flow。有以下字段信息:
imp_date:数据日期
ftime:购买时间(yyyy-MM-dd hh:mm:ss)
feq_no:流水号
user_id:账号
cid:专辑ID(电视剧ID)
vid:视频id(具体集ID)
fee:金额(分)
表格信息如下:

某电视剧(cid = ‘vbb35hm6m6da1wc’)排播周期如下:
超前点播周期为2019-12-23至2020-01-08,每天更新2集,合计更新32集。
(1)请统计超前点播期间,每日购买笔数、总金额、购买人数以及相应的新、老用户数;
注:当日为该剧首次购买,即为新用户
要求输出结果如下:

sql
(2)一个用户购买超前点播剧集集数的35%即为该剧忠实用户,其余为普通用户。请统计忠实与普通用户的平均购买集数 。
要求输出结果如下:
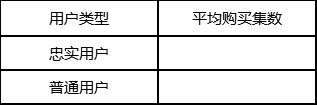
sql
(3)一个用户从第一次购买该剧开始,每天都购买或者未购买天数不超过1天,均视为连续追剧。未购买天数超过1天的均视为中断,需要重新统计连续追剧日期。请统计购买该剧超前点播的用户,最大的连续追剧天数,并按照最大连续追剧天数统计对应的用户数分布。
举例:
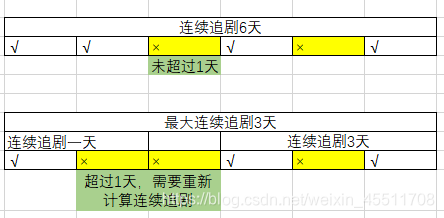
要求输出结果如下:

sql
背景说明:
腾讯视频新开发了一款针对少儿的视频APP:小企鹅乐园,作为数据分析人员,请你为小企鹅乐园设计合适的指标体系,并描述如何实现指标体系的落地。
本人的方案被说不是最优,所以删掉了,大神们可以评论区给出最优方案交流交流。

















 724
724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









