




 在进行机器学习文本分类实践中,若遇到20新闻数据集加载时的SSL错误,可以尝试手动下载数据集,将其重命名为20news-bydate.tar.gz并放置于sklearn设定的数据目录下。修改_twent_newsgroups.py中的archive_path,如问题依然存在,可重启开发环境如PyCharm或JupyterNotebook。
在进行机器学习文本分类实践中,若遇到20新闻数据集加载时的SSL错误,可以尝试手动下载数据集,将其重命名为20news-bydate.tar.gz并放置于sklearn设定的数据目录下。修改_twent_newsgroups.py中的archive_path,如问题依然存在,可重启开发环境如PyCharm或JupyterNotebook。
进行机器学习的文本分类练习时候,如果用到的20新闻数据集加载如果发生错误,比如ssl错误等,需要如下修复
1、手工下载数据集:
下载地址是:
链接:https://pan.baidu.com/s/1xjF1O6s_sL44psOqnsx6Iw
提取码:3hxn
2、复制下载后的20newsbydate.tar.gz文件到指定文件夹,进行更名,更改为20news-bydate.tar.gz。但注意无需解压。需要复制到的文件夹需要从代码里获取,代码如下:
import sklearn
print(sklearn.datasets.get_data_home())
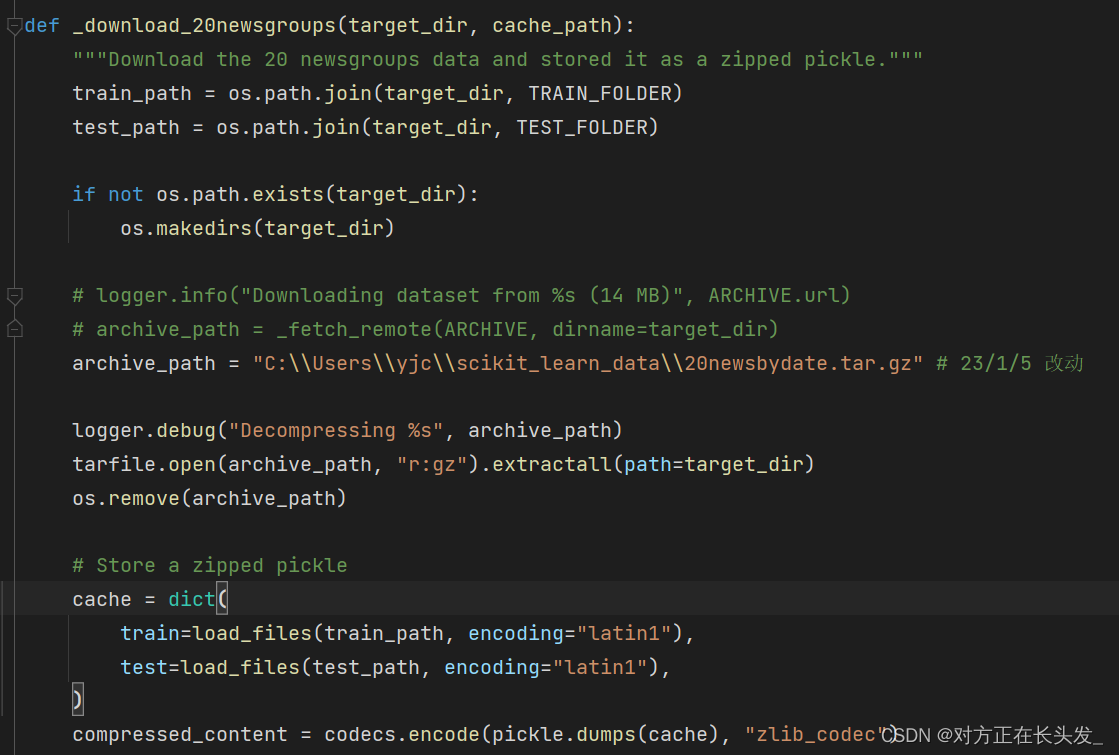
3. 打开_twenty_newsgroups.py这个文件,进行编辑(archive_path改为数据集所在路径即可)


















 1747
1747





 到【灌水乐园】发言
到【灌水乐园】发言









