




背景
工作中遇到了一个缓慢内存泄漏的问题,类linux开发环境,内存泄漏量2M/天,总体用了很长的周期才分析清楚,故而顺便记录一下苦痛经验,希望有缘人不要再受折磨。
缓慢内存泄漏问题分析的经验
- 首先对齐或记录复现条件,对问题进行复现,这是第一步,注意不是近似条件,而是完全对齐复现条件
- 排除潜在因素的干扰,潜在因素包括是否开启界面、设备是否有其他程序在运行、以及内存监控方式等,这些因素与内存泄漏问题可能没有直接关系,但是他们会导致内存波动,而在缓慢内存泄漏问题中,内存波动会极大影响我们对内存监控结果的判断
- 如果Demo可以复现问题,那么优先针对Demo进行排查,因为
1)产品端会涉及更多模块与系统,涉及更多人员的配合,使用Demo进行测试是最直接的屏蔽测试方式
2)如果Demo出现内存泄漏,那么这个泄漏问题大概率会映射到产品端
3)Demo端更加方便使用一些内存泄漏分析工具进行分析
4)如果Demo端不出现内存下降,那么就排除了主要代码中的内存泄漏,接下来就只需要针对Demo与产品端的不同进行分析就可以了 - 前期的实验以及决定关键排查方向的实验一定要长时间的监控内存,包括Demo。通过二分法屏蔽实验,我们能够进一步缩小泄漏范围,而如果出现错误的判断就会让我们的排查方向发生南辕北辙的错误,本身缓慢内存泄漏问题的实验周期就比较长,所以我们一定要尽力避免出现方向上的错误,一定要顶住压力,在前期实验以及决定排查方向上的实验中,让设备运行较长时间,以此得出准确结论。
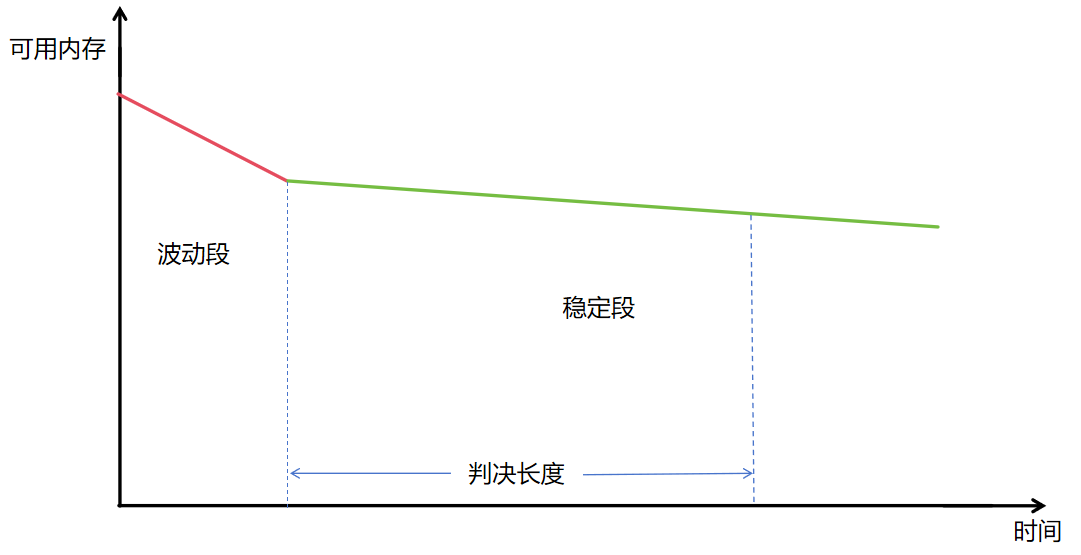
1) 程序在开始运行的时候,或会申请一块较大的内存作为缓冲,或者一些数据结构会随程序处理而变大,所以会存在一段内存下降较快的时间,我们将其称为波动段,那么在前期实验中,我们需要确认这段波动段的时间长度,即经过多久我们的内存才会进入到稳定状态,即内存基本稳定的状态,我们称之为稳定段,而缓慢内存泄漏问题的泄漏量也是在这一个稳定段去确定的
2)在复现实验中确定了波动段的时间长度后,我们设定一个时间长度作为稳定段的判决长度,即在稳定段监控这么长时间,我们就能确定是否依然存在内存下降的问题,并且能对内存下降的速度做一个粗略估计。这个判决长度应该根据实际的内存变化情况确定,下面放一张示意图。
3)为什么要在复现实验中确定? 是因为发现问题的产品端涉及的模块是最多的,后续的屏蔽实验,运行速度会只快不慢,即会更快的走出波动段,到达稳定端,从而展现出内存变化趋势。 - 采取二分法屏蔽实验,在屏蔽时一定确保进行屏蔽不会引入新的内存泄漏点。
- 定期对屏蔽实验的结果进行对比,一定要注意各个屏蔽实验的运行速度是不一样的,所以在对比时不要轻易的下结论,使用较好的数据分析工具对结果进行分析,注意我们的目标就是一条不持续下降的内存曲线。
内存泄漏结果
经过了长时间的折磨,最终发现了可恶的内存泄漏点,他是什么呢?
参考这个吧
使用全局单例类的时候还是需要非常注意的
内存泄漏分析工具
这回使用了AddressSanitizer(ASan)对Demo进行了分析,只分析出一个其他模块中的堆溢出错误,屏蔽了之后依然存在内存下降,与本次内存泄漏问题无关。但是不得不说相比于需要重新按平台编译的其他内存分析工具来讲,AddressSanitizer还是比较方便的。如果大家使用的话,问Deepseek大将军吧,累了
参考文献
[1] RapidJson内存泄漏:https://blog.youkuaiyun.com/Aquester/article/details/86681283?ops_request_misc=&request_id=&biz_id=102&utm_term=rapidjson::Document%E5%86%85%E5%AD%98%E6%B3%84%E6%BC%8F&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-5-86681283.142v102pc_search_result_base9&spm=1018.2226.3001.4187


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









