







本篇内容以知识整理为主,会结合萨特吉-萨尼的数据结构书籍和网络上的一些知识整理做一下总结,语言使用c++,有问题请及时指正,欢迎交流。
数组与链表
在开始内容整理之前,我们先比较一下数组和链表的优劣,数组的优势在于可以快速找到我们所需要的元素,只要知道元素所在位置就可以以O(1)的时间复杂度找到我们想要的元素;数组的缺点就在于插入和删除的时候,一个位置的变动需要其后所有位置的变动,时间复杂度相对较高,达到了O(n)。链表就是数组优劣的相反方面了,插入和删除比较简单,查找某一数据时就很难受了。
数组
1、定义与初始化
数组是有序数据的集合,存储相同类型的数据
定义一维数组:类型名 数组名 [常量表达式]
例如一个整型数组:
int a[10]; //表示数组名为a,此数组为整型,有10个元素
int a[2*5];
int a[n*2]; //假设前面定义了n为常变量
引用一维数组的元素:数组名[下标]
初始化一维数组:
(1)在定义数组时给全部数组元素赋值:int a[10]={0,1,2,3,4,5,6,7,8,9};
(2)可以只给一部分元素赋值:int a[10]={1,2,3,4,5};//后面五个元素默认为0
(3)对全部元素赋值时可以不指定数组长度:int a[]={1,2,3,4,5};//与int a[5]一样
定义二维数组:类型名 数组名 [常量表达式][常量表达式]
引用二维数组的元素:数组名[下标][下标]
初始化一维数组:
(1)按行给二维数组全部元素赋值:int a[2][3]={{1,2,3},{4,5,6}};
(2)所有数据写在一个花括号内按数组排列的顺序赋值:int a[2][3]={1,2,3,4,5,6};
(3)可以对部分元素赋值:int a[2][3]={{1},{5},{9}};其余元素自动设为0
(4)对全部元素赋值时,可以省略第一维的长度,第二维长度不能省略:int a[][3]={1,2,3,4,5,6};
2、数组常见操作
1、返回数组大小:
int a[]={1,2,3,4};
int num = sizeof(a)/sizeof(a[0]);
2、不允许拷贝和赋值
int a[]={1,2,3};
int b[]=a; //错误
b=a; //错误
3、动态数组:在动态数组初始化时给其一个默认大小,当默认数组大小无法满足操作需要时,扩充数组大小,在扩充数组大小时,每次将数组扩充为原有的 2 倍大小,直到满足要求,realloc 重新定义数组大小时,若新分配内存大于原有内存,则数组数据不会丢失,若内存比原有内存小则丢失数据。
int dynamicArry(int nums,int numSize,int newSize)
{
if (newSize < numSize) return nums;
int size = numSize;
while (size < newSize)
size *= 2;
nums = (int *)realloc(nums,size*sizeof(int));//重新分配内存大小
numSize = size;
return nums;
}
4、定长数组删除某元素
int arrayDelete(int nums, int numSize, int deleteIndex) {
if (deleteIndex >= numSize || deleteIndex < 0) {
cout << "删除元素不在数组内";
return nums;
}
for (int i = deleteIndex; i < numSize - 1; i++) {
nums[i] = nums[i + 1];
}
return nums;
}
3、动态数组
很多情况下,在预编译过程阶段,数组的长度是不能预先知道的,必须在程序运行时动态的给出,但是问题是,c++要求定义数组时,必须明确给定数组的大小,要不然编译通不过,例如:
int Array[5];//正确
int i=5;
int Array[i]; //错误 因为在编译阶段,编译器并不知道 i 的值是多少
我们可以用new 动态定义数组来解决定义长度未知的数组,因为new 就是用来动态开辟空间的,所以当然可以用来开辟一个数组空间。
int size=50;
int *p=new int[size]; //是正确的
但是二维动态数组能不能也这样定义呢,比如:
int size=50,Column=50;
int (*p)[Column]=new int [size][Column]
这样的语句,编译器通不过,为什么呢?
首先 new int[size][Column] 就是动态生成时确定的,所以它没有错
那么就是 int(*p)[Column],这句有问题了,这句为什么不对呢, 那是因为,这是一个定义语句,而定义语句先经过编译器进行编译,当编译器运行到此处时,发现Column 不是常数,因此不能通过编译。 而之所以编译器认为Column 不是常数,是因为编译阶段,编译器起的作用是查语法错误,和预分配空间,它并不执行程序,因此,没有执行那个赋值语句(只是对这个语句检查错误,和分配空间),因此编译阶段,它将认为column 是个变量。所以上面的二维数组定义是错误的, 它不能通过编译。
int size=50
int (*p)[50]=new int [size][50]//正确
new关键字的过程:1、获得一块内存空间 2、调用构造函数 3、返回正确的指针。
4、Vector有关问题
1、Vector初始化
vector<int> vec; //声明一个int型向量
vector<int> vec(5); //声明一个初始大小为5的int向量
vector<int> vec(10, 1); //声明一个初始大小为10且值都是1的向量
vector<int> tmp;
vector<int> vec(tmp); //声明并用tmp向量初始化vec向量
vector<int> tmp(vec.begin(), vec.begin() + 3); //用向量vec的第0个到第2个值初始化tmp
2、Vector常用函数
1、push_back 在数组的最后添加一个数据
2、insert 增加
3、pop_back 去掉数组的最后一个数据
4、clear 清空当前的vector
5、erase 删除
6、at 得到编号位置的数据
7、front 得到数组头的引用 (begin、end返回的是指针)
8、back 得到数组的最后一个单元的引用
9、begin 返回第一个元素的指针
10、end 返回最后一个元素的指针
11、size 当前使用数据的大小
12、max_size 最大可允许的vector元素数量值
13、capacity vector实际能容纳的大小
14、empty 判断vector是否为空
15、swap 交换
16、assign 使用括号内的值设置当前的vector
链表
1、链表定义与结构
链表是一种动态结构,创建链表时,无须知道链表长度,插入一个节点时,只需为新节点分配内存,然后调整指针,每一个节点都明确包含另一个相关节点的位置信息,这个信息称为链或指针。具体结构可以对照下图:
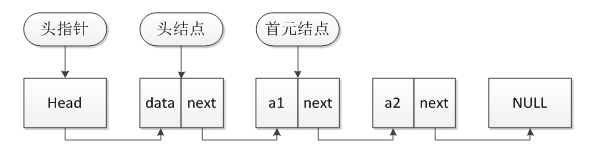
2、链表的创建以及相关操作的实现
1、单向链表创建
//创建链表节点结构,包括存储数据和指针
struct ListNode
{
int data;
ListNode *pNext;
};
//创建链表
//n为存储元素个数
Node creatList(int n) {
int t_num = n;
//先定下头指针
Node *head = new(Node);
if (NULL == head) cout << "分配内存失败";
Node *start = new(Node);
head->next = start;
Node *tmp;
start->data = 1;
int a;
for (int i = 1; i < t_num; i++) {
tmp = new(Node);
cout << "请输入数值:";
cin >> a;
tmp->data = a;
start->next = tmp;
start = tmp;
}
//最后一个
start->next = NULL;
return *head;
}
2、链表输出
//链表输出
void printList(Node *head) {
Node *start = head->next;
while (start != NULL) {
cout << start->data;
start = start->next;
}
cout << endl;
}
3、链表倒序(反转链表)
Node *reverseList(Node *head) {
if (head == NULL && head->next == NULL) return 0;
Node *start, *pre;
start = head->next;
pre = start->next;
Node *tmp = NULL;
while (pre != NULL) {
tmp = pre->next;
pre->next = start;
start=pre;
pre = tmp;
}
head->next = start;
return head;
}
4、链表尾部增加节点
void insertNode(Node*head,int data) {
Node *newNode = new(Node);
newNode->data = data;
newNode->next = NULL;
if (head = NULL) {
head->next = newNode;
}
else {
Node *start = head->next;
while (start->next != NULL) {
start = start->next;
}
start->next = newNode;
}
}
5、链表删除指定值节点
void deleteNode(Node*head, int data) {
if (head == NULL || head->next == NULL) return;
Node*start = head->next;
Node*dNode = NULL;
if (head->data == data) {
dNode = head;
head = head->next;
}
else {
while (start->data != data&&start->next!= NULL) {
start = start->next;
}
dNode = start;
start = start->next;
}
if (dNode != NULL) {
delete dNode;
dNode == NULL;
}
return;
}
6、循环链表
循环链表的结构和单链表结构一样,不过对于单链表,每个结点只存储了向后的指针,到了尾标志就停止了向后链的操作,这样知道某个结点却无法找到它的前驱结点。将单链表中的终端点的指针由空指针改为指向头结点,就使整个单链表形成一个环,这种头尾相接的单链表称为循环单链表,简称循环链表。
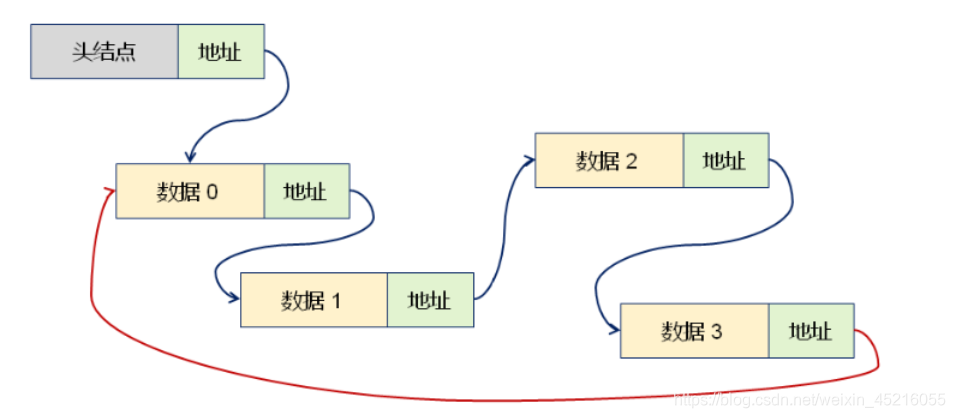
7、双向链表
双向链表创建的过程中,每一个结点需要初始化数据域和两个指针域,一个指向直接前趋结点,另一个指向直接后继结点。
1、创建:

struct DoubleList {
int data;
DoubleList *last;//指向上一个节点
DoubleList *next;//指向下一个节点
};
2、插入:
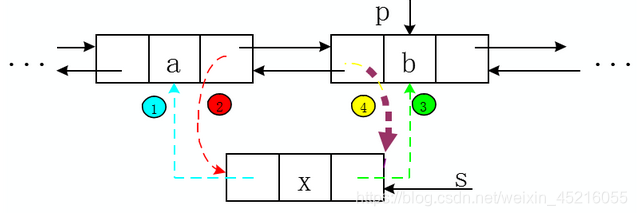
3、删除:
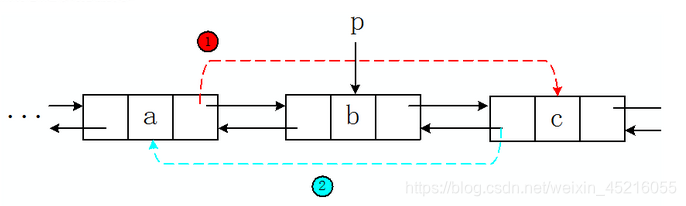


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









