




1.排序原理:
%1.假如说以升序进行排列的话,下标为0的第一个元素作为参考值。
%2.插入排序是从元素为1开始的,尽可能插到前面(即按照排序的方式找到最适合自己的位置)。
%3.插入的时候分为插入位置和试探位置。
%4.第一层循环从1开始,到列表的长度终止。第二层循环主要是确定试探位置,从i的位置开始,到0终止。倒着进行循环
%5.如果被试探位置的元素比插入元素大,那么试探元素后移一位,插入元素前进一位,直到被试探元素小于插入元素或者插入元素位于第一位。
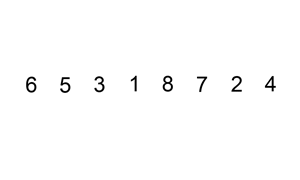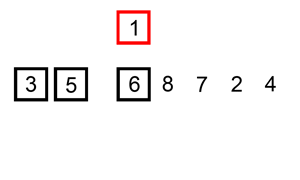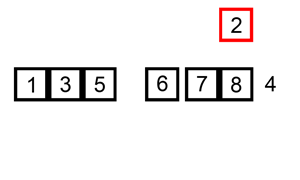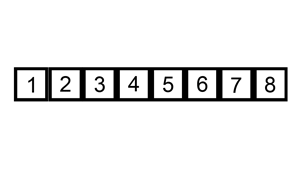
2.代码展示
def mm(a):
for i in range(1,len(a)):#外层循环
for j in range(i,0,-1):#内层循环决定试探位置
if a[j]<a[j-1]:
a[j],a[j-1]=a[j-1],a[j]
else:
break
a=[1,4,5,2,1,9,7,4,3,1,6]
print('排序前:',a)
mm(a)
print('排序后:',a)
3.代码优化
def mm(a):
for i in range(1,len(a)):
x=a[i]#加入一个临时变量x
for j in range(i,-1,-1):
if x<a[j-1]:
a[j]=a[j-1]
else:
break
a[j]=x#替换值
a=[1,4,5,2,1,9,7,4,3,1,6]
print('排序前:',a)
mm(a)
print('排序后':a)
这个代码优化的核心点在于添加了一个临时变量。使用临时变量来进行值的转化,即达到插入排序的效果。
到最后可能有些同学会存在疑惑,这。。。。。代码怎么和冒泡排序那么像呢?????

好了,现在由我来为你解答
首先从过程上看:冒泡排序是小白们学习排序算法的基础,他是一个比较相邻的元素,数据慢慢由无序变为有序的过程;而我们的插入排序是前面的是有序数据,后面的是无序的数据(分界点为是否符合要求的排序),他的整体过程是将无序的数据插入到有序的数据中,插入后仍然有序。
其次:他们的循环次数不一定是一样的。
好了,大家下去试试吧!(/≧▽≦)/(/≧▽≦)/。一定要注意他们两个是不一样的哦!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









