




 本文深入探讨了Hadoop生态系统,包括Hadoop Distributed FileSystem (HDFS) 的架构与工作原理,如存储模型、文件块管理、分布式计算支持等,以及NameNode和DataNode的角色。同时,文章还提及了归并算法、倒排索引等数据处理技术。
本文深入探讨了Hadoop生态系统,包括Hadoop Distributed FileSystem (HDFS) 的架构与工作原理,如存储模型、文件块管理、分布式计算支持等,以及NameNode和DataNode的角色。同时,文章还提及了归并算法、倒排索引等数据处理技术。
你无论学到顶尖,还得回来思考这件事,你只有一颗大脑,你只有一颗知识体系,在真正的知识体系面前太弱小了,九牛一毛,
每个人学的知识不一样,所以共享大脑,讨论方案,从心里学来讲:
人虽然是孤独的希望找到朋友,但是人是带有攻击性的,也就是在互相讨论的时候,你是处在敌视的状态,你的肾上腺素激发,然后你的大脑飞速运转是平时自学的几倍的思考能力,应为对方想出各种的观点时你要反驳他,或质疑他,这样获取知识的速度是极快的应为从一个学过这知识的人手里总结知识里获取。
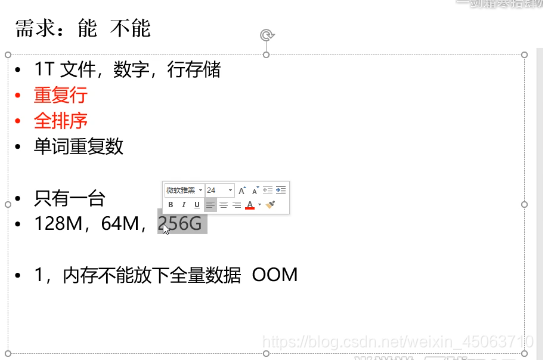
归并算法
倒排索引
小时:
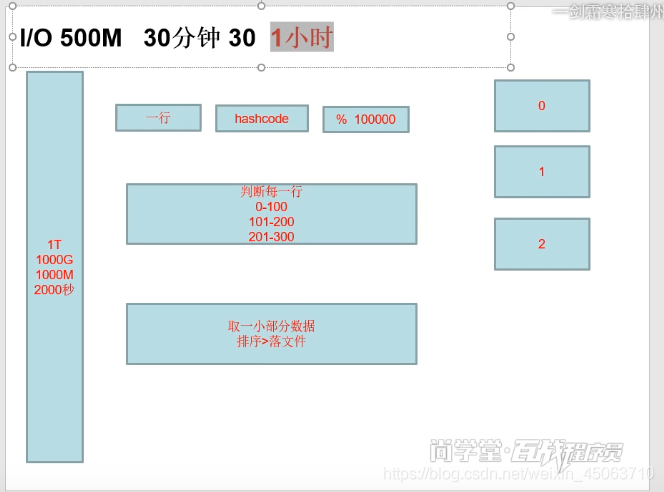
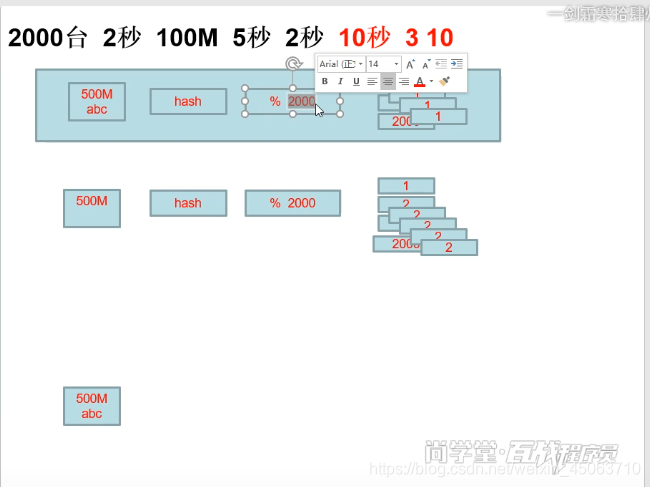 小知识:千兆网卡等于百兆宽带1000(bit)100字节
小知识:千兆网卡等于百兆宽带1000(bit)100字节

------------分割线
今天规定十节课
hadoop-HDFS
 这个架构如何支持分布式计算(hdfs唯一优势)??????
这个架构如何支持分布式计算(hdfs唯一优势)??????
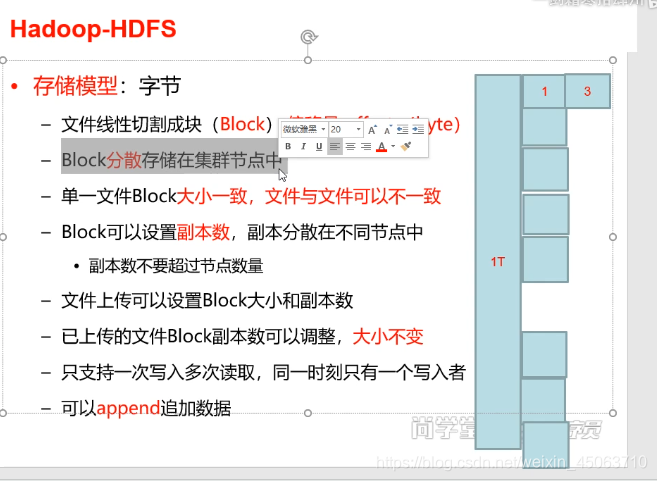
-存储模型:字节
-文件切割成块-----》面向字节偏移量
-block分散存储在集群节点中
-单一文件block大小一致,文件与文件可以不一致
-block可以设置副本数,副本分散在不同节点中·副本数不能超过节点数
文件上传可以设置block大小和副本数
-已上传的文件block副本数俩可以调整,大小不变
-只支持一次写入多次读取,同一时刻只有一个写入者
-可以append追加数据
磁盘的 IOPS,也就是在一秒内,磁盘进行多少次 I/O 读写。
每秒 I/O 吞吐量= IOPS* 平均 I/O SIZE。从公式可以看出: I/O SIZE 越大,IOPS 越高,那么每秒 I/O 的吞吐量就越高。因此,我们会认为 IOPS 和吞吐量的数值越高越好。实际上,对于一个磁盘来讲,这两个参数均有其最大值,而且这两个参数也存在着一定的关系。
Hadoop Common: The common utilities that support the other Hadoop modules.
Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
Hadoop YARN: A framework for job scheduling and cluster resource management.
Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.

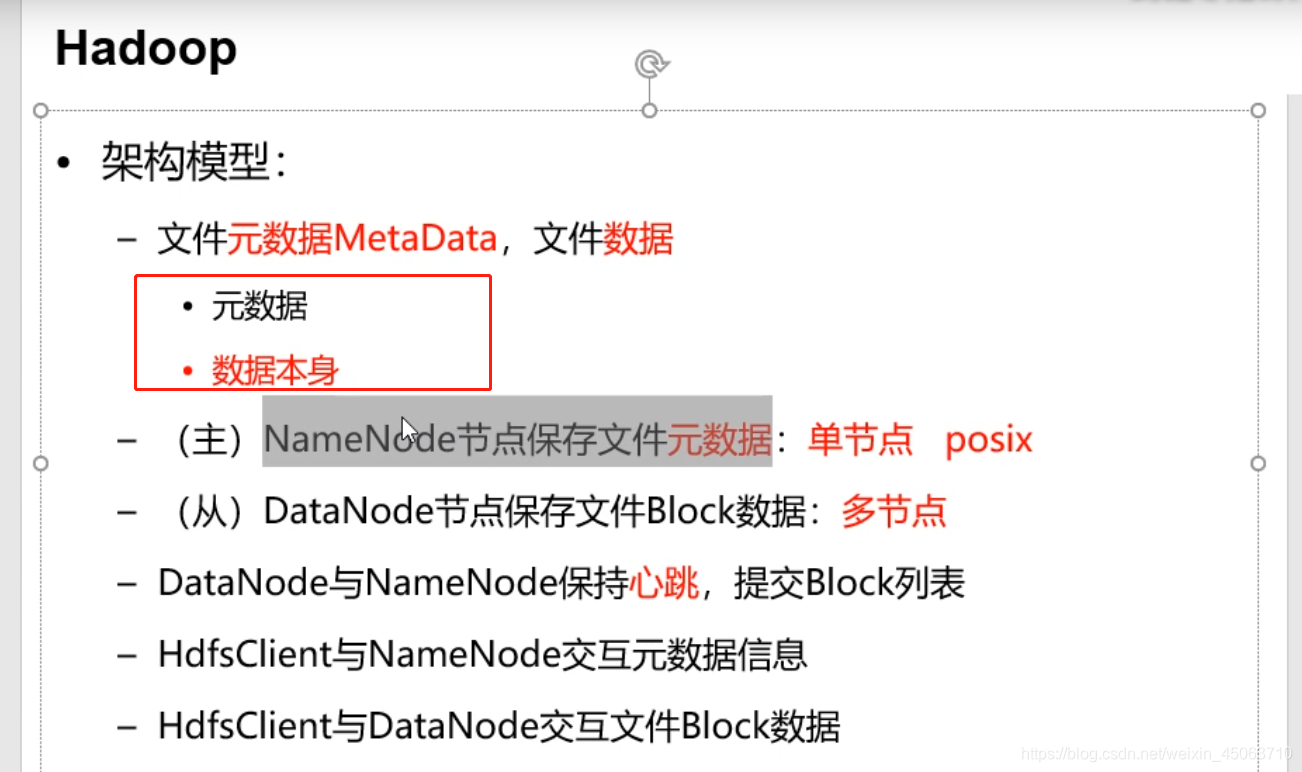
NameNode
-基于内存存储:不会和磁盘发生交换
只存在内存中
持久化
-功能
接受客户端的读写服务
收集DataNode汇报的block列表信息
-NameNode保存在metadata
-NameNode保存metdata信息包括
-文件owership和permissions
-文件大小时间
-block列表:block偏移量,位置信息
-block每副本信息(由DataNode上报)

md5文件映射地址。block
 CPU热插拔
CPU热插拔

















 1337
1337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









