




数据倾斜的定义
由于各种原因造成数据分布不均匀,造成数据大量集中在一点,造成数据热点。
数据倾斜产生的现象
- 执行任务的时候,任务进度卡在99%,打开监控查看,只有一个或N个reduce任务处于运行未完成的状态。 这是因为处理的数据数量相比较其他reduce节点数据要大
- 单一reduce处理数据量比平均reduce处理的数据量要大,通常是3倍甚至更多。处理时间也大于平均时长。
数据倾斜的情况
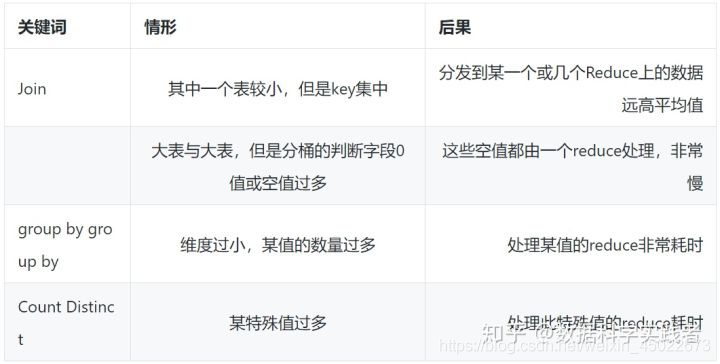
数据倾斜的原因
- Key 分布不均匀
- 业务本身对某些维度需求较集中
- 建表的时候未考虑周到
- 某些SQL语句执行的时候,底层结构会造成数据倾斜
数据倾斜的解决方案
MAP端聚合
–Map端部分聚合,相当于Combine
hive.map.aggr= true;
–有数据倾斜的时候进行负载均衡
hive.groupby.skewindate=true;
解释 :默认为true的时候,查询计划会有两个MR,第一个MR执行的时候,Map操作会将结果数据随机分到Reduce中,每个Reduce做部分聚合操作,并输出结果
**作用:**可以将相同的key值放在不同的reduce端处理
第二个MR job的作用是,是将第一个 MR job散落在不同的reduce端的数据聚合起来。完成最后的聚合操作。
关于数据负载均衡方面的调优操作
如何进行 JOIN
关于驱动表的选取,使用key值分布平均的表作为基准表,在进行JOIN操作的时候,可以做基准表进行列裁剪和filter 操作,达到基准表数据量变少的效果。
JOIN的情况:
- 大小表相互JOIN, 使用 map join 使得小表先进内存。
- 大表JOIN大表,将key为null值的数据变成一个字符串+随机数,反正null值也关联不上null值,处理后并不影响最终结果。
- count distinct 大量相同特殊值
可以事先将空值过滤掉,等到最终结果+1处理 - group by 维度过小
维度过小导致产出数据 <data,count()> 值过多,可以使用 group by + sum的方式
替换 count (distinct )操作。 - 特殊情况特殊处理
在不更改逻辑的前提下,将造成倾斜的数据单独拿出来做处理,最后在 union 回去。

















 1067
1067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









