




 本文深入探讨使用Networkx进行网络图的构建与可视化,包括从不同格式文件中读取数据,以及通过numpy和pandas进行高效数据存储、读取与分析。同时,介绍了统计随机网络特性的方法和电影评分数据集的分析流程。
本文深入探讨使用Networkx进行网络图的构建与可视化,包括从不同格式文件中读取数据,以及通过numpy和pandas进行高效数据存储、读取与分析。同时,介绍了统计随机网络特性的方法和电影评分数据集的分析流程。
一、Networkx读取文件绘图

已知一个网络矩阵如下,请输出这个网络的边,并将网络绘制出来

import networkx as nx
G = nx.Graph()#创建一个空的网络
with open( 'Karate_club.txt', 'r' )as file:
lines = file. readlines( )
for i in range(len(lines)):
lines[i] = lines[i].strip('\n').split(' ')
#lines[i].strip('\n')得到了[0 1 1 1...]
#lines[i].strip('\n').split(' ')得到了['0', '1', '1', '1'...,'0','']
for j in range(len(lines[i])):
if lines[i][j] == '1':
G.add_edge(i + 1, j + 1)
nx.draw(G,with_labels=True)
print(list(G.edges))


已知一个网络连边如下,请将网络绘制出来

import networkx as nx
G = nx.Graph()
with open('karate_edges.txt', 'r' )as file:
for line in file:
a,b=line.strip('\n').split('\t')#\t 跳格,一个tap键的大小(下面有\t的解释)
#也可以是a,b=line.strip('\n').split(' ')
G.add_edge(a,b)
nx.draw(G,with_labels=True)
print(list(G.edges))


\t是什么
#\t就是一个tap键
print("123")
print("\t123")
print("123\t456\t789")
print("\n123\n456\n789")
print("自然数:\n\t123\n\t456\n\t789")
print("\t\n123\t\n456\t\n789")

二、numpy的存储与读取
①二维数组的存储与读取






②多维数组的存储与读取






三、pandas读取文件
①csv文件
import pandas as pd
# read csv file directly from a URL and save the results
data = pd.read_csv('text.csv', index_col=0)
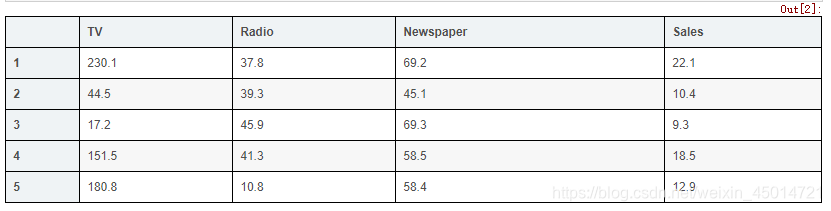
# display the first 5 rows
data.head()
# display the last 5 rows
data.tail()
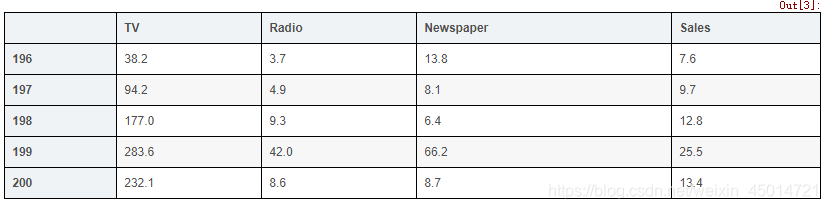
# check the shape of the DataFrame(rows, colums)
data.shape
输出:(200, 4)
#200行数据,四列特征值
②txt文件如下:
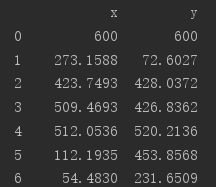
这些数据表示的是每个城市的(x,y)坐标。(中间是用空格分开的)
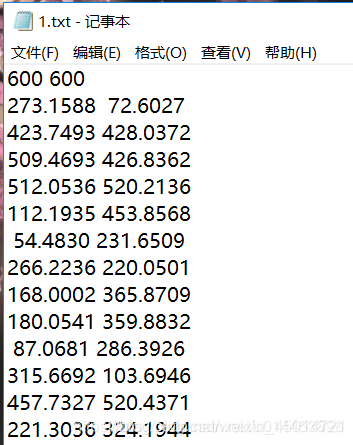
import pandas as pd #引入pandas包
citys=pd.read_table('./1.txt',sep='\t',header=None) #读入txt文件,分隔符为\t;若不写head=None,则会把第一行当成列名,读取时会没了第一行数据
print(citys)
打印结果:
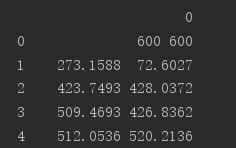
可以看到全部数据就只有一列了,因为分割符为制表符,而制表符存在于txt文件每行的末尾。
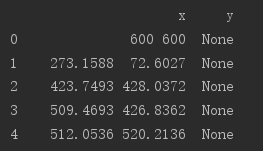
接着把第一列的名字改成x,并添加一列,名字为y,y这一列的数值全是None:
citys.columns=['x']
citys['y']=None
print(citys)
最后把 x列中的数据,以空格为分割符,分给y一个数:
for i in range(len(citys)): #遍历每一行
coordinate = citys['x'][i].split() #分开第i行,x列的数据。split()默认是以空格等符号来分割,返回一个列表
citys['x'][i]=coordinate[0] #分割形成的列表第一个数据给x列
citys['y'][i]=coordinate[1] #分割形成的列表第二个数据给y列
print(citys)
可以看到,已经给txt的数据打上了x和y的标志了。
③pandas实例-----电影评分数据集分析




import pandas as pd
#读取电影的评分人的数据
unames=['uid','age','gender','occupation','zip']
users=pd.read_table('E:\\快乐的程序猿\\test6\\u_user.txt',sep='|',header=None,names=unames) #sep='|'是分隔符,header=None就是没有行标题,unames是映射关系
print(users[:5])
#读取电影的评分数据
rnames=['uid','mid','rating','timestamp']
ratings=pd.read_table('E:\\快乐的程序猿\\test6\\u_data.txt',sep='\t',header=None,names=rnames) #分隔符是table键
print(ratings[:5])
#读取电影数据
mnames=['mid','title','date1','date2','url',
'unkown','Action','Adventure','Animation','Children','Comedy','Crime','Documentary','Drama','Fantasty','File-Noir','Horror','Muscial','Mystery','Romance','Sci-Fi','Thriller','War','Weatern']
movies=pd.read_table('E:\\快乐的程序猿\\test6\\u_item.txt',sep='|',header=None,names=mnames)
print(movies[:5])

四、类似于文件读取的思想
如何统计100幅图片的平均值
①如何统计100幅随即网络的平均度、平均集聚系数、平均最短距离、平均最大联通集团
N=100
pro=[0.2,0.4,0.6,0.8,1.0,1.2,1.4,1.6]
Avg_deg=[]
Avg_cls=[]
Avg_spl=[]
Avg_gcc=[]
for p in pro:
avg_deg=[]
avg_cls=[]
avg_spl=[]
avg_gcc=[]
for _ in range(100):
g=nx.erdos_renyi_graph(N,p,directed=False) #根据每一个p与N绘制一个随即网络图
avg_deg.append(np.mean(nx.degree(g).values()))
avg_cls.append(nx.average_clustering(g))
avg_gcc.append( max([len(x) for x in nx.connected_components(g)] )
avg_spl.append(nx.average_shorteest_path_length(g))
Avg_deg.append(np.mean(avg_deg))
Avg_cls.append(np.mean(avg_cls))
Avg_spl.append(np.mean(avg_spl))
Avg_gcc.append(np.mean(avg_gcc))
'''avg_deg里面存放着100个随即网络图的平均度
avg_cls里面存放着100个随即网络图的平均集聚系数
avg_gcc里面存放着100个随即网络图的最大连通集团
avg_spl里面存放着100个随即网络图的平均最短距离
'''
②

③如何统计100次实验的平均数据
已知我们有一个函数,suspect_infect_recovery(g, sources, beta, gamma),g是一个网络,sources是一个列表涵盖了这个网络最先得了传染病的那个节点,beta=0.3是感染概率,gamma=1是恢复概率;这个函数可以返回一个state,state里面记录了本次传染病盛行后各个节点得状态是“I”还是“R”还是“S”(I是感染,R是感染后恢复,S是未感染)
g=nx.karate_club_graph() #空手道俱乐部
res=[[] for i in g] #res事实上就是[[], [], [], [], []...]
for _ in range(100): #让g中的每一个节点都循环100次得到较为客观的值
for i in g:
state=suspect_infect_recovery(g, [i], 0.3, 1)#让g中的每一个节点都做一次sources(第一个被感染的人)
s=sum([1 for i in state if state[i] !="S"])#统计共有多少人受到了感染
res[i].append(s) #res[i]就是列表中的列表,它当然可以调用列表的方法
#此时的res就是[[24, 16, 5, 24, 24..],[21, 8, 25, 15, 7..]...]
impact=[sum(r)/len(r) for r in res] #让g中的每一个节点都循环100次再做平均得到一个客观的值
#impact就是[18.02, 15.69, 17.07, 14.68...]的样子
Impact_sort=sorted([(i,impact[i]) for i in range(len(impact))],key=lambda x:x[1],reverse=True)
for i in Impact_sort:
print(i)




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











