 分布式ID生成详解
分布式ID生成详解





 本文深入探讨了分布式ID生成的重要性及三种主流解决方案:UUID、Redis自增ID与雪花算法。UUID确保ID唯一但长度过长;Redis自增ID依赖数据库但能保证线程安全;雪花算法由Twitter提出,性能高效且无需第三方服务。
本文深入探讨了分布式ID生成的重要性及三种主流解决方案:UUID、Redis自增ID与雪花算法。UUID确保ID唯一但长度过长;Redis自增ID依赖数据库但能保证线程安全;雪花算法由Twitter提出,性能高效且无需第三方服务。
分布式ID生成
1.1 为什么使用分布式ID
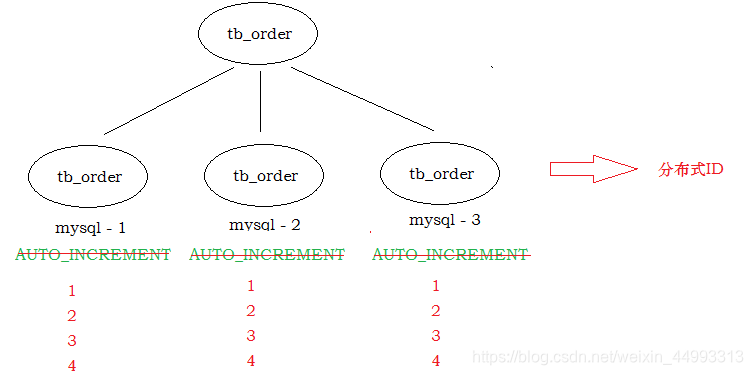
1.2 分布式ID解决方案
1). UUID
UUID 可以保证每一次生成的ID不重复 ;
缺点 :
- 长度比较长 , 占用磁盘空间
- 无法排序
2). Redis
通过redis的指令 incr指令, 来实现一个自增的主键 , 可以保证ID不会重复 , 并且线程安全 ;
实现:
incr orderid
缺点 : - 借助于redis数据库 ;

3). 雪花算法
自己编写的一种算法实现 , 是推特网站提供的一种分布式ID生成机制 ; 不需要借助于第三方服务, 性能高;

64 = 1 + 41 + 10(5 + 5) + 12 ;
5: 代表数据中心ID
5: 代表机器ID
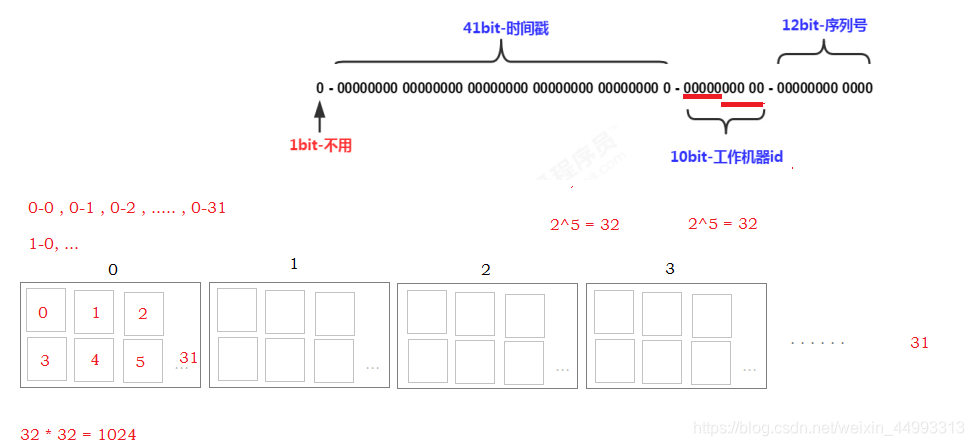
1.3 雪花算法实现
IdWorker idWorker = new IdWorker(0,0);
for(int i=0;i<1000;i++){
long id = idWorker.nextId();
System.out.println(id);
}
将IdWorker交给Spring管理 :
@Value("${workerId}")
private Integer workerId;
@Value("{datacenterId}")
private Integer datacenterId;
@Bean
public IdWorker idWorker(){
return new IdWorker(workerId,datacenterId);
}

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









