




 本文详细介绍了Linux中几个重要的文本处理命令,包括cut用于切割文件数据,通过指定分隔符和字段选择显示内容;sort进行排序,支持字典序和数值序,以及自定义分隔符和字段;wc命令统计文件的行数、单词数和字节数;awk则是一个强大的文本分析工具,支持自定义分隔符、条件判断和操作。文中给出了多个实战案例,帮助读者更好地理解和应用这些命令。
本文详细介绍了Linux中几个重要的文本处理命令,包括cut用于切割文件数据,通过指定分隔符和字段选择显示内容;sort进行排序,支持字典序和数值序,以及自定义分隔符和字段;wc命令统计文件的行数、单词数和字节数;awk则是一个强大的文本分析工具,支持自定义分隔符、条件判断和操作。文中给出了多个实战案例,帮助读者更好地理解和应用这些命令。
Linux文本操作
cut
cut:显示切割的行数据
-s:不显示没有分隔符的行
-d:指定分隔符对源文件的行进行分割
-f :选定显示哪些列
m-n m列到n列
-n 第1列到n列
m- 第m列到最后列
n 只显示第n列
–output-delimiter:输出的内容以什么进行分隔
cp /etc/passwd ./
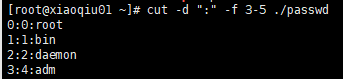
案例1:以:作为分隔符,切割passwd,输出从第3个字段到第5个字段
cut -d “:” -f 3-5 ./passwd
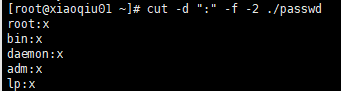
案例2:以:作为分隔符,切割passwd,输出前两列内容
cut -d “:” -f -2 ./passwd
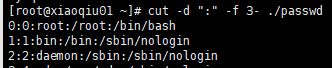
案例3:以:作为分隔符,切割passwd,输出字段3到最后一个字段
cut -d “:” -f 3- ./passwd
案例4:以:作为分隔符,切割passwd,输出字段3到最后一个字段,以_分隔输出
cut -d “:” -f 3- --output-delimiter="_" ./passwd

案例5:以:作为分隔符,切割passwd,输出第7个字段
cut -d “:” -f 7 ./passwd

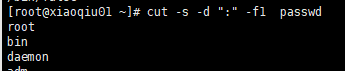
案例6:如果有的行没有分隔符,则输出会包含脏数据
可以使用-s选项,不打印没有分隔符的行
cut -s -d “:” -f1 passwd
案例6:显示1,3,7列
cut -d “:” -f 1,3,7 --output-delimiter="|" ./passwd

sort
排序:字典序和数值序
sort:排序文件的行
-n:按数值排序
-r:倒序 reverse
-t:自定义分隔符
-k:选择排序列
-f:忽略大小写
sort.txt
a b 1
dfdsa fdsa 15
fds fds 6
fdsa fdsa 8
fda s 9
aa dd 10
h h 11
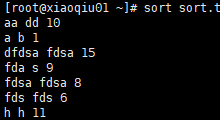
案例1:默认字典序排序
sort sort.txt
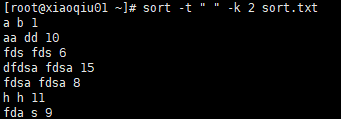
案例2:指定字段分隔符,按照第2个字段的字典序排序
sort -t " " -k 2 sort.txt
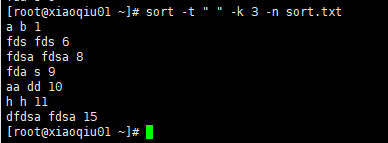
案例3:指定字段分隔符,按照第3个字段的值数值序排序
sort -t " " -k 3 -n sort.txt
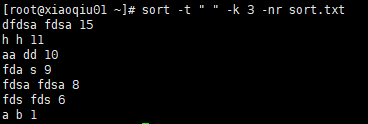
案例4:指定字段分隔符,按照第3个字段的值数值倒序
sort -t " " -k 3 -nr sort.txt
wc
wc [选项列表]… [文件名列表]…
wc命令的功能为统计指定文件中的行数、单词数、字节数, 并将统计结果显示输出
-c, --bytes, --chars 输出字节统计数。
-l, --lines 输出换行符统计数。
-L, --max-line-length 输出最长的行的长度。
-w, --words 输出单词统计数。
–help 显示帮助并退出
–version 输出版本信息并退出

awk
awk是linux下的一个命令,他对其他命令的输出,对文件的处理都十分强大,其实他更像一门编程语言,他可以自定义变量,有条件语句,有循环,有数组,有正则,有函数等。他读取输出,或者文件的方式是一行,一行的读,根据你给出的条件进行查找,并在找出来的行中进行操作,感觉他的设计思想,真的很简单,但是结合实际情况,具体操作起来就没有那么简单了。他有三种形势,awk,gawk,nawk,平时所说的awk其实就是gawk。
awk把文件逐行读入,以空格和制表符作为默认分隔符将每行切片,切开的部分再进行各种分析处理。
awk -F ‘{pattern + action}’ {filenames}
选项
-F 紧跟分隔符,表示读入的字段以输入的分隔符分割
-v 进入变量模式 可以进行变量的赋值及调用(调用不需要加$符)
- 变量
| 变 量 | 描述 |
|---|---|
| $n | 当前记录的第n个字段,字段间由 FS分隔。 |
| $0 | 完整的输入记录。 |
| ARGC | 命令行参数的数目。 |
| ARGIND | 命令行中当前文件的位置(从0开始算)。 |
| ARGV | 包含命令行参数的数组。 |
| CONVFMT | 数字转换格式(默认值为%.6g) |
| ENVIRON | 环境变量关联数组。 |
| ERRNO | 最后一个系统错误的描述。 |
| FIELDWIDTHS | 字段宽度列表(用空格键分隔)。 |
| FILENAME | 当前文件名。 |
| FNR | 同 NR,但相对于当前文件。 |
| FS | 字段分隔符(默认是任何空格)。 |
| IGNORECASE | 如 果为真,则进行忽略大小写的匹配。 |
| NF | 当前记录中的字段数。 |
| NR | 当前记录数。 |
| OFMT | 数字的输出格式(默认值是%.6g)。 |
| OFS | 输出字段分隔符(默认值是一个空格)。 |
| ORS | 输出记录分隔符(默认值是一个换行符)。 |
| RLENGTH | 由 match函数所匹配的字符串的长度。 |
| RS | 记录分隔符(默认是一个换行符)。 |
| RSTART | 由 match函数所匹配的字符串的第一个位置。 |
| SUBSEP | 数组下标分隔符(默认值是\034)。 |
- 运算符
| 运算符 | 描述 |
|---|---|
| = += -= *= /= %= ^= **= | 赋值 |
| ?: | C条件表达式 |
| || | 逻 辑或 |
| && | 逻辑与 |
| ~ !~ | 匹配正则表达式和不匹配正则表达式 |
| < <= > >= != == | 关系运算符 |
| 空格 | 连接 |
| + - | 加,减 |
| * / & | 乘,除与求余 |
| + - ! | 一元加,减和逻辑非 |
| ^ *** | 求幂 |
| ++ – | 增加或减少,作为前缀或后缀 |
| $ | 字段引用 |
| in | 数组成员 |
- awk的正则
| 匹配符 | 描述 |
|---|---|
| \Y | 匹配一个单词开头或者末尾的空字符串 |
| \B | 匹配单词内的空字符串 |
| \< | 匹配一个单词的开头的空字符串,锚定开始 |
| \> | 匹配一个单词的末尾的空字符串,锚定末尾 |
| \W | 匹配一个非字母数字组成的单词 |
| \w | 匹配一个字母数字组成的单词 |
| \’ | 匹配字符串末尾的一个空字符串 |
| \‘ | 匹配字符串开头的一个空字符串 |
- 字符串函数
| 函数名 | 描述 |
|---|---|
| sub | 匹配记录中最大、最靠左边的子字符串的正则表达式,并用替换字符串替换这些字符串。如果没有指定目标字符串就默认使用整个记录。替换只发生在第一次匹配的 时候 |
| gsub | 整个文档中进行匹配 |
| index | 返回子字符串第一次被匹配的位置,偏移量从位置1开始 |
| substr | 返回从位置1开始的子字符串,如果指定长度超过实际长度,就返回整个字符串 |
| split | 可按给定的分隔符把字符串分割为一个数组。如果分隔符没提供,则按当前FS值进行分割 |
| length | 返回记录的字符数 |
| match | 返回在字符串中正则表达式位置的索引,如果找不到指定的正则表达式则返回0。match函数会设置内建变量RSTART为字符串中子字符串的开始位 置,RLENGTH为到子字符串末尾的字符个数。substr可利于这些变量来截取字符串 |
| toupper和tolower | 可用于字符串大小间的转换,该功能只在gawk中有效 |
- 数学函数
| 函数名 | 返回值 |
|---|---|
| atan2(x,y) | y,x 范围内的余切 |
| cos(x) | 余弦函数 |
| exp(x) | 求 幂 |
| int(x) | 取整 |
| log(x) | 自然对 数 |
| rand() | 随机数 |
| sin(x) | 正弦 |
| sqrt(x) | 平方根 |
| srand(x) | x是rand()函数的种子 |
| int(x) | 取整,过程没有舍入 |
| rand() | 产生一个大于等于0而小于1的随机数 |
- format的使用
要点:
1、其与print命令的最大不同是,printf需要指定format;
2、format用于指定后面的每个item的输出格式;
3、printf语句不会自动打印换行符;\\n
format格式的指示符都以%开头,后跟一个字符;如下:
%c: 显示字符的ASCII码;
%d, %i:十进制整数;
%e, %E:科学计数法显示数值;
%f: 显示浮点数;
%g, %G: 以科学计数法的格式或浮点数的格式显示数值;
%s: 显示字符串;
%u: 无符号整数;
%%: 显示%自身;
修饰符:
N: 显示宽度;
-: 左对齐;
+:显示数值符号;
sed
ed对文本的处理很强大,并且sed非常小,参数少,容易掌握,他的操作方式根awk有点像。sed按顺序逐行读取文件。然后,它执行为该行指定的所有操作,并在完成请求的修改之后的内容显示出来,也可以存放到文件中。完成了一行上的所有操作之后,它读取文件的下一行,然后重复该过程直到它完成该文件。在这里要注意一点,源文件(默认地)保持不被修改。sed 默认读取整个文件并对其中的每一行进行修改。说白了就是一行一行的操作。我用sed主要就是用里面的替换功能,真的很强大。下面以实例,详细的说一下,先从替换开始,最常用的。
sed -h
| -n, --quiet, --silent | 取消自动打印模式空间 |
| -e 脚本, --expression=脚本 | 添加“脚本”到程序的运行列表 |
| -f 脚本文件, --file=脚本文件 | 添加“脚本文件”到程序的运行列表 |
| –follow-symlinks | 直接修改文件时跟随软链接 |
| -i[扩展名], --in-place[=扩展名] | 直接修改文件(如果指定扩展名就备份文件) |
| -l N, --line-length=N | 指定“l”命令的换行期望长度 |
| –posix | 关闭所有 GNU 扩展 |
| -r, --regexp-extended | 在脚本中使用扩展正则表达式 |
| -s, --separate | 将输入文件视为各个独立的文件而不是一个长的连续输入 |
| -u, --unbuffered | 从输入文件读取最少的数据,更频繁的刷新输出 |
| –help | 打印帮助并退出 |
| –version | 输出版本信息并退出 |
| -a | 新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~ |
| -c | 取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行! |
| -d | 删除,因为是删除啊,所以 d 后面通常不接任何咚咚; |
| -i | 插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行); |
| -p | 列印,亦即将某个选择的资料印出。通常 p 会与参数 sed -n 一起运作~ |
| -s | 取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法 |
sed命令
| a\\ | 在当前行下面插入文本。 |
| i\\ | 在当前行上面插入文本。 |
| c\\ | 把选定的行改为新的文本。 |
| d | 删除,删除选择的行。 |
| D | 删除模板块的第一行。 |
| s | 替换指定字符 |
| h | 拷贝模板块的内容到内存中的缓冲区。 |
| H | 追加模板块的内容到内存中的缓冲区。 |
| g | 获得内存缓冲区的内容,并替代当前模板块中的文本。 |
| G | 获得内存缓冲区的内容,并追加到当前模板块文本的后面。 |
| l | 列表不能打印字符的清单。 |
| n | 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令。 |
| N | 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码。 |
| p | 打印模板块的行。 |
| P(大写) | 打印模板块的第一行。 |
| q | 退出Sed。 |
| b lable | 分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾。 |
| r file | 从file中读行。 |
| t label | if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。 |
| T label | 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。 |
| w file | 写并追加模板块到file末尾。 |
| W file | 写并追加模板块的第一行到file末尾。 |
| ! | 表示后面的命令对所有没有被选定的行发生作用。 |
| = | 打印当前行号码。 |
| # | 把注释扩展到下一个换行符以前。 |
sed替换标记
| g | 表示行内全面替换。 |
| p | 表示打印行。 |
| w | 表示把行写入一个文件。 |
| x | 表示互换模板块中的文本和缓冲区中的文本。 |
| y | 表示把一个字符翻译为另外的字符(但是不用于正则表达式) |
| \\1 | 子串匹配标记 |
| & | 已匹配字符串标记 |
sed元字符集
| ^ | 匹配行开始,如:/^sed/匹配所有以sed开头的行。 |
| $ | 匹配行结束,如:/sed$/匹配所有以sed结尾的行。 |
| . | 匹配一个非换行符的任意字符,如:/s.d/匹配s后接一个任意字符,最后是d。 |
| * | 匹配0个或多个字符,如:/*sed/匹配所有模板是一个或多个空格后紧跟sed的行。 |
| [] | 匹配一个指定范围内的字符,如/[sS]ed/匹配sed和Sed。 |
| [^] | 匹配一个不在指定范围内的字符,如:/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行。 |
| \\(…\\) | 匹配子串,保存匹配的字符,如s/\\(love\\)able/\\1rs,loveable被替换成lovers。 |
| & | 保存搜索字符用来替换其他字符,如s/love/**&**/,love这成**love**。 |
| \\< | 匹配单词的开始,如:/\\\\> 匹配单词的结束,如/love\\>/匹配包含以love结尾的单词的行。 |
| x\\{m\\} | 重复字符x,m次,如:/0\\{5\\}/匹配包含5个0的行。 |
| x\\{m,\\} | 重复字符x,至少m次,如:/0\\{5,\\}/匹配至少有5个0的行。 |
| x\\{m,n\\} | 重复字符x,至少m次,不多于n次,如:/0\\{5,10\\}/匹配5~10个0的行。 |

















 676
676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









