







 本文详细阐述了Java中对象相等性判断的关键概念,包括`equals()`和`==`的区别,`hashCode()`的作用及其与`equals()`的关系。在Java中,`equals()`用于内容相等的判断,而`==`则比较对象的引用。`hashCode()`生成对象的哈希码,用于哈希表如HashSet中定位对象。当重写`equals()`时,通常也需要重写`hashCode()`以确保一致性。此外,文章还讨论了值传递的概念,强调Java方法参数传递始终是值传递,而非引用传递。
本文详细阐述了Java中对象相等性判断的关键概念,包括`equals()`和`==`的区别,`hashCode()`的作用及其与`equals()`的关系。在Java中,`equals()`用于内容相等的判断,而`==`则比较对象的引用。`hashCode()`生成对象的哈希码,用于哈希表如HashSet中定位对象。当重写`equals()`时,通常也需要重写`hashCode()`以确保一致性。此外,文章还讨论了值传递的概念,强调Java方法参数传递始终是值传递,而非引用传递。
hashCode equals ==关联与区别
hashCode方法 介绍
java 顶级父类Object类中
public native int hashCode();
这里面有个关键字native关键字的作用是调用底层代码,说明是本地方法栈而不是java生成的,通过JNI(Java Native Interface)这是一个本机编程的接口调用C/C++生成的返回内存地址),返回值是整数型int类型的值
equals方法 介绍
java 顶级父类Object类中
public boolean equals(Object obj) {
return (this == obj);
}
在没有重写equals方法的object类中 就是判断两个是不是同一个对象,在java中,几乎所有使用类中的equals方法都进行了重写
// Integer中value的定义是 The value of the {@code Integer}.value变量被初始化为传入的参数值
//一旦 value 被初始化,由于它是 final 的,所以不能再被修改 放在常量池中
private final int value;
public boolean equals(Object obj) {
if (obj instanceof Integer) { //首先判断是相同的对象类型
return value == ((Integer)obj).intValue();
}
return false;
}
代码解读:判断如果是相同的对象类型后 值是否相同
1.这里value是变量被初始化为传入的参数值,在如创建Interger对象值Interger a=new Interger(5) 或者Interger a = 5(这里自动装箱int转为Interger)那么value=5
2.然后通过return value == ((Integer)obj).intValue();这里比较已int类型(左边value又自动拆箱)进行比较
3.== 因为这里两边是基础数据类型int了 比较的就是值
需要注意的是,Integer的取值范围是和int一致的,如果超过2的32次方-1这个范围会报错,因为我们创建Integer对象给的参数值实际上是先有基础数据类型int值 然后引用的这个值
同样String 的equals里面方法也是重写了
/**用于字符存储*/
private final char value[];
/**缓存字符串的哈希码*/
private int hash; // Default to 0
public int hashCode() {
int h = hash;
//h值默认为0,"0"对应value.length应该为1
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
// 这一步对应的h=31*0 +'0' 字符型+数值,字符转换unicode数字,'0'编码对应48
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
在String类中,关于hasCode的值是一个算法(结合unicode编码),无论new多少个对象,只要值是字符串"0",hasCode值就是48,所以如果两个对象相等,则hashcode一定也是相同的
运算符 == 介绍
== 是一个运算符号,运算符== 和 hashCode没有关系
- 如果比较双方是基本数据类型,比较的是值是否相同
- 对于引用类型,== 比较两个变量是否引用的同一个对象,即它们所指向的对象是否为同一个对象
equals和 == 区别
==
- 基本数据类型 ==比较的是值是否相同
- 引用数据类型 ==比较的是否 相同对象
equals() : 它的作用也是判断两个对象是否相等。但它一般有两种使用情况:
- 类没有覆盖 equals() 方法。则通过 equals() 比较该类的两个对象时,等价于通过“==”比较这两个对象。
- 类覆盖了 equals() 方法,比较两个对象的内容相等;若它们的内容相等,则返回 true
hashCode 与 equals关联
为什么重写equals时 必须重写hashCode方法
先了解是对象存入哈希表的过程,存入步骤核心过程:哈希计算 → 定位桶 → 处理冲突 → 动态扩容
1.哈希计算:计算键的哈希码,并进行扰动处理
Ⅰ.调用hashCode():首先调用键对象的hashCode()方法获取原始哈希码,计算取得hash值的算法就叫hash算法,不是某个固定的算法,它代表的是一类算法,接受任意长度的二进制输入值并给出固定长度的二进制输出值,像取模运算(特定的加减乘除),MD5加密计算都是;
Ⅱ.二次哈希扰动处理:为防止低位哈希冲突,尽可能的减少出现相同哈希值的概率,HashMap通过扰动函数将原始哈希码的高位与低位混合,以减少哈希冲突
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
扰动处理 说白了就是尽可能的保证让不同对象的哈希码值不同
2.计算索引位置(取模运算):定位“桶”
已以下字符串为例
String a = "Aa";//a.hashCode() 2112
得到一个类似map<2112,“Aa”> 这样关键键对码值(Key value)
Ⅰ.将Key值也就是哈希值与一个数组长度进行求余运算得到一个整数值(索引值),这一步骤总得有个实现的方法吧,java中方法就叫函数,和哈希值处理有关,也叫hash函数(哈希函数 翻译中文 散列函数),计算的方法类似如下:
int index = hash(key) & (table.length - 1); // 等价于 hash % table.length
Ⅱ.存入数组桶中,如下图,数组中每个索引对应的一个位置就像一个 “桶”,像上面的通过hash函数计算后的索引值比如是0,那就将键对码值<2112,“Aa”> 存入下标为0的位置,当然如果长度不够了,数组扩容
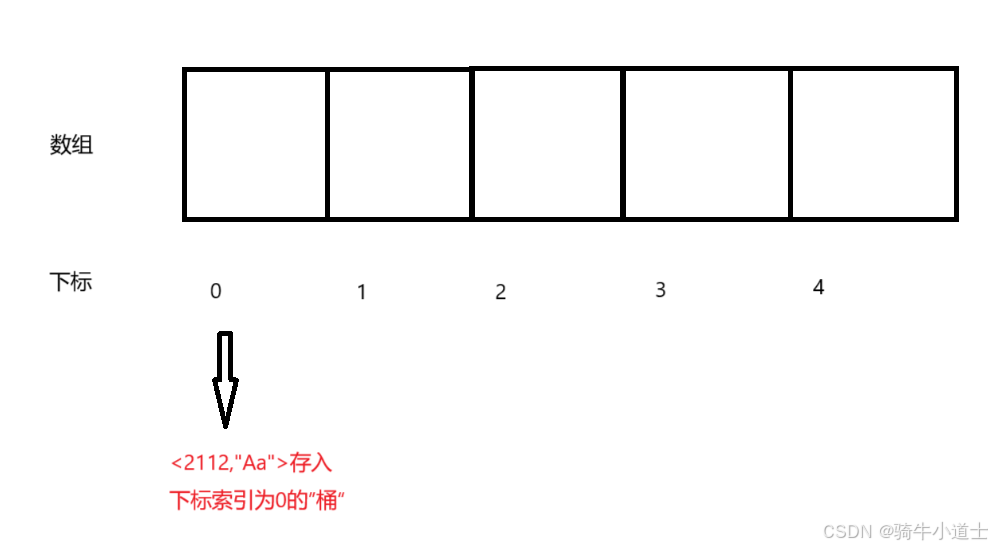
在存入的过程步骤中,比如0对应的位置 桶
①空桶:若目标桶为空,直接创建新节点(Node)并存入键值对
②非空桶:遍历链表或红黑树,检查键是否已存在。
非空桶这里就需要解释下,常见数组每个位置可能就是存放一个元素,比如数组或者字符等,但这里的数组每个位置存放的是链表,数组存放列表的方式代码示例
List<String> list1 = new ArrayList<>();
list1.add("Apple");
list1.add("Banana");
List<String> list2 = new ArrayList<>();
list2.add("Cherry");
list2.add("Date");
// 将列表存储在数组中
List<String>[] array = (List<String>[]) new List[2];
array[0] = list1;
array[1] = list2;
当链表长度超过阈值会转换为红黑树(二叉树),元素为链表或者二叉树的数组数据结构就是哈希表Hash table,翻译过来就是散列表,本质是数组,实现方式是 数组+链表 或者 数组+二叉树
非空桶下处理步骤:遍历冲突元素并比较哈希值
1.哈希值比对:若当前桶内的元素哈希值与新键的哈希值不同,直接插入(无需进一步比较内容)。
2.哈希值相同:新元素调用equals方法与旧元素比较内容是否相同
如果元素内容也相同就判断重复,覆盖旧值,如果元素内容不同,这就是哈希冲突了,按照冲突策略处理,如hashMap链地址法(拉链法):发生冲突时,新元素会被添加到链表的末尾,这就是存入过程
从存入过程也能看出为什么重写equals时 必须重写hashCode方法,这符合Java的哈希约定,能够保证哈希表的正确性和高效性。这个约定规定,如果两个对象在equals比较中被认为是相等的,那么它们的hashCode值也必须相同。这是因为哈希表(如HashSet、HashMap等)依赖于hashCode方法来定位对象,如果两个对象被认为是相等的,但它们的hashCode值不同,那么它们可能会被散列到哈希表的不同位置,这会导致哈希表的性能下降,并可能导致逻辑错误
总结:
1、如果两个对象相同(即用equals比较返回true),那么它们的hashCode值一定要相同;
2、但如果两个对象的hashCode相同,它们并不一定相同(即用equals比较返回false) (这就是哈希冲突)
举例说明存入过程:张伟同学的名字编入学校名册,学校根据学生姓名首字母排序
学生姓名张伟 学号2 比如哈希值18
学校学生名册 一个长度27的数组
a b c...x y z #
通过哈希值和数组长度哈希函数调用返回结果索引值,比如26对应下标的是z
z位置里面的链表元素 如:张三哈希值3 张良哈希值4 张伟哈希值18
新元素进来遍历比较,发现有相同的哈希值,那就equals方法比较具体内容,发现学号不同不是重复元素,那么在链接尾上插入新元素(冲突策略解决哈希冲突),这样就存入了
哈希冲突代码示例
hashCode()是一个返回的一个int数值,那么也就是2^32 -1范围,不同的对象的hashCode值一致的情况可能会出现的
总结:如果两个不同对象的hashCode相同,这种现象称为哈希冲突,是正常且无法避免的现象
String a = "Aa";
String b = "BB";
System.out.println(a.hashCode());//2112
System.out.println(b.hashCode());//2112
System.out.println(a.equals(b));//false
hash冲突是不可避免的正常现象,重写hashCode方法时候,在计算hashCode取值时候尽量避免简单重复计算逻辑
代码hashCode()与equals() 和== 关联
如下String类的hasCode()和equals()说明,先写一段代码
public class Hashcode {
public static void main(String[] args) {
String a = new String("0");
String b = new String("0");
String c = "1";
String d = "1";
System.out.println(a.hashCode());// 48
System.out.println(b.hashCode());// 48
System.out.println(a==b); // false
System.out.println(a.equals(b));// true
System.out.println(c.hashCode());// 49
System.out.println(d.hashCode());// 49
System.out.println(c==d); // true
System.out.println(c.equals(d));// true
}
先看hasCode()的介绍,这里拿String类说明,hasCode是object中的方法,在String类中有重写,我们结合String a = new String(“0”);计算下hasCode的值
/**用于字符存储*/
private final char value[];
/**缓存字符串的哈希码*/
private int hash; // Default to 0
public int hashCode() {
int h = hash;
//h值默认为0,"0"对应value.length应该为1
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
// 这一步对应的h=31*0 +'0' 字符型+数值,字符转换unicode数字,'0'编码对应48
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
在String类中,关于hasCode的值是一个算法(结合unicode编码),无论new多少个对象,只要值是字符串"0",hasCode值就是48,符合如果两个对象相等,则hashcode一定也是相同的
再来看下equals()的说明解释String类对于equals方法覆写
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
// 这一步拆分循环比较每个字符串内容,不一样返回false,所以这里是内容比较
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
String类对于equals方法覆写,循环比较每个字符串内容,不一样返回false, 两个对象相等,对两个对象分别调用equals方法都返回true
最后来看==的两个比较
①先看 == 那个输出为false的,a和b分别是new的对象,这是两个对象,hasCode值都是48,但是a == b比较输出为false,两个对象有相同的hashcode值,它们也不一定是相等的 ,即使这两个对象指向相同的数据,equals()方法进行覆盖过,输出为true,**equals()方法被覆盖过,则 hashCode 方法也必须被覆盖,hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),否则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)**其实hasCode是一个算法,返回int类型
②再看第二个 == 输出为true的,c和d的hasCode值也是一样的,这里输出为true是因为,定义一个字符串"1",相当于创建了一个String对象值为"1",存放在元数据内,String对象c和d分别引用这个String对象,这里属于相同的对象引用:比较的是他们指向的内存地址是否相等引用的同一个对象,所以相等,下面在解释下值传递和引用传递
Java只有值传递 没有引用传递
值传递(Pass by Value)
定义:方法接收的是调用者提供的变量值的副本,而非变量本身。在方法内部对参数修改不影响原始变量
基本数据类型
- 示例:
int,char,boolean等。 - 行为:
- 传递的是变量值的副本。
- 方法内部修改参数的值不会影响原始变量。
public static void main(String[] args) {
int a = 10;
modify(a); // 传递a的副本(值为10)
System.out.println(a); // 输出10(原值未变)
}
public static void modify(int num) {
num = 20; // 修改的是副本,不影响原始变量a
}
对象引用的值传递(Object References Passed by Value)
定义:对象类型的变量存储的是对象的引用(内存地址),传递的是引用的副本,而非对象本身。通过副本引用可以修改对象的状态,但无法改变原始引用的指向,在java 对象原始指向就是this指针指向
引用类型或者叫对象类型(Object Types)
- 示例:
String,List, 自定义类对象等。 - 行为:
- 传递的是对象引用的副本(即内存地址的副本)。
- 方法内部通过引用修改对象属性时,会影响原始对象状态。但没改变原始引用的指向
- 方法内部重新赋值引用参数时,不会改变原始引用变量的指向。
public static void main(String[] args) {
StringBuilder sb = new StringBuilder("Hello");
modifyObject(sb); // 传递sb引用的副本(指向"Hello"的地址)
// 输出"Hello World"(对象状态被修改)但没改变原始引用的指向 sb.this 依然是对象sb,不是其他对象
System.out.println(sb);
}
public static void modifyObject(StringBuilder builder) {
builder.append(" World"); // 通过副本引用修改原对象内容 ✅
builder = new StringBuilder("New"); // 重新赋值副本引用,不影响原始sb ❌
}
关键对比表
| 场景 | 基本数据类型 | 对象引用 |
|---|---|---|
| 传递内容 | 变量值的副本 | 对象引用的副本(内存地址的副本) |
| 修改参数值 | 不影响原始变量 | 不影响原始引用的指向 |
| 修改对象状态 | 不适用(基本类型无状态) | 影响原始对象的内容 |
| 重新赋值参数 | 仅修改副本,不影响原始变量 | 仅修改副本引用,不影响原始引用变量 |
常见误区澄清
误区1:Java有引用传递
- 真相:Java严格遵循值传递。对象引用的传递本质上是传递引用的副本(值传递),而非传递引用本身(引用传递)
误区2:修改对象属性等同于引用传递
- 解释:修改对象属性是通过引用副本操作原对象,但这不改变参数传递的机制(仍是值传递)
误区3:认为数组和集合是例外
- 示例:数组作为对象引用,行为与其他对象一致:
public static void main(String[] args) {
int[] arr = {1, 2, 3};
modifyArray(arr); // 传递数组引用的副本
System.out.println(arr[0]); // 输出100(修改原数组内容)
}
public static void modifyArray(int[] array) {
array[0] = 100; // 通过副本修改原数组 ✅
array = new int[]{4, 5, 6}; // 重新赋值副本引用,不影响原始arr ❌
}
Java只有值传递总结
- 值传递是唯一机制:无论是基本类型还是对象引用,Java参数传递均为值传递。
- 对象引用的特殊性:通过引用副本可以修改对象状态,但无法改变原始引用的指向。
- 设计意义:确保方法内部无法意外修改调用者的变量指向,同时允许合理操作对象内容。

















 5387
5387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









