







 在一个启用Kerberos的CDH集群中,由于node2和node3上缺少业务用户hs_abc,导致Spark on YARN任务执行失败。解决方法是在缺少用户的节点上创建对应用户,如在node2和node3执行'useradd hs_abc'命令,然后重新执行任务,问题得到解决。了解Kerberos的管理员可以通过kadmin.local命令进行管理。
在一个启用Kerberos的CDH集群中,由于node2和node3上缺少业务用户hs_abc,导致Spark on YARN任务执行失败。解决方法是在缺少用户的节点上创建对应用户,如在node2和node3执行'useradd hs_abc'命令,然后重新执行任务,问题得到解决。了解Kerberos的管理员可以通过kadmin.local命令进行管理。
1.基本情况
CDH集群, 节点分别为node1/node2/node3, 已安装Kerberos安全认证, 执行spark任务, 执行模式为spark on yarn 集群模式。
2.报错信息
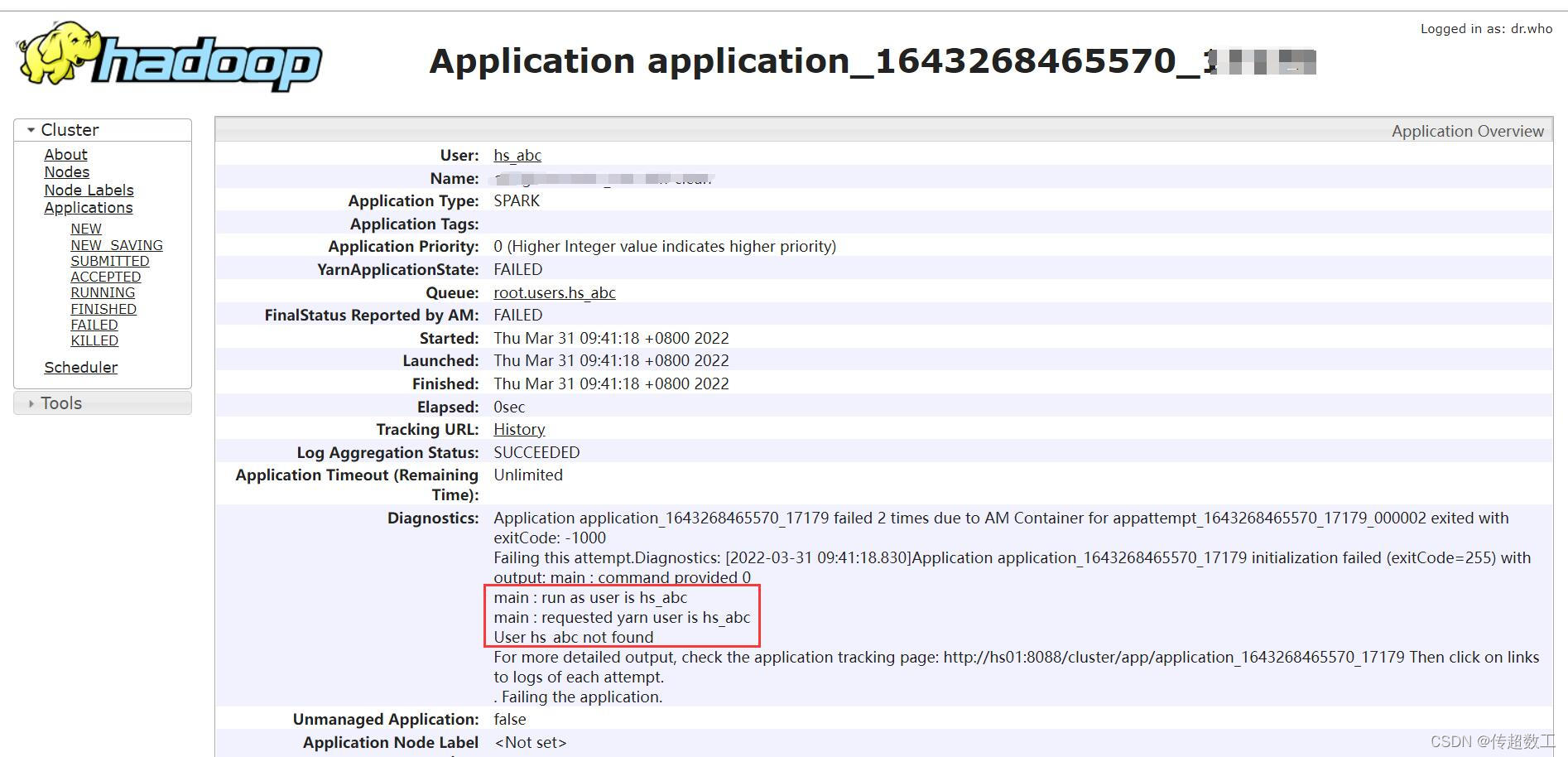
核心提示信息如下:
main : run as user is hs_abc
main : requested yarn user is hs_abc
User hs_abc not found
3.原因分析
在一个没有开启 Kerberos 安全的集群里,启动 container进程可以使用 DefaultContainerExecutor 或 LinuxContainerExecutor;但是启用了Kerberos 安全的集群里,启动 container进程只能使用LinuxContainerExecutor,在底层会使用 setuid 切换到业务用户以启动container进程,所以要求所有 nodemanager 节点必须有业务用户。
当仅仅在KDC中添加了业务用户的pricipal,而没有在所有nodemanager节点建立业务用用户的话,就会无法启动AM/mapper/reducer等container 而报错。
4.解决方案
4.1 查看集群节点用户情况
节点node1存在用户hs_abc
节点node2没有用户
节点node3没有用户
4.2 在node2及node3节点新增用户
node2节点: useradd hs_abc
node3节点: useradd hs_abc
4.3 重新执行任务
此时任务执行成功,完美解决。
5.kerberos管理员常用命令
1) 登录Kerberos Server服务命令:
root用户:
[root@hadoop01 ~]# kadmin.local
非root用户:
[root@hadoop01 ~]# kadmin.local 用户名
2) 列出Principal: list_principals, listprincs命令
[root@hadoop01 ~]# /usr/sbin/kadmin.local
[root@hadoop01 ~]# kadmin.local: listprincs

















 1614
1614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









