






转自博客园用户(Excaliburer)
原文链接——原文链接
用法拓展
1、我们以上的实例针对的是函数原型1的用法,对于函数原型2,我们仍然使用上述实例,只不过unique的用法变成:
unique(it_1,it_2,myfunc);
即自定义的元素相等的准则,其中myfunc在上述实例中有其源码,分析可知,只有i+1 == j的时候我们才认为i和j“相等”;实例结果如下:
也就是说,按照我们自定义的规则,这个实例中只有3和4”相等的”,4和5是”相等的”,5和6,6和7是”相等的”。所以最终结果是上图的样子。
2.unique函数通常和erase函数一起使用,来达到删除重复元素的目的。(注:此处的删除是真正的删除,即从容器中去除重复的元素,容器的长度也发生了变换;而单纯的使用unique函数的话,容器的长度并没有发生变化,只是元素的位置发生了变化)关于erase函数的用法,可以参考:http://www.cnblogs.com/wangkundentisy/p/9023977.html。下面是一个具体的实例:
#include<iostream>
#include<algorithm>
#include<cassert>
using namespace std;
int main()
{
vector<int> a ={1,3,3,4,5,6,6,7};
vector<int>::iterator it_1 = a.begin();
vector<int>::iterator it_2 = a.end();
vector<int>::iterator new_end;
new_end = unique(it_1,it_2); //注意unique的返回值
a.erase(new_end,it_2);
cout<<"删除重复元素后的 a : ";
for(int i = 0 ; i < a.size(); i++)
cout<<a[i];
cout<<endl;
}
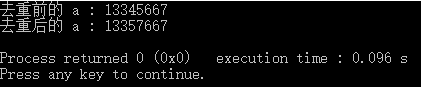
运行结果如下:

可以看到,相比之前的结果,a的长度确实发生了改变,真正的删除了a中的重复元素。


















 747
747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









