




 该博客通过示例代码展示了多线程环境下,普通变量、原子变量以及互斥锁在并发计数中的性能差异。实验中创建了三个函数,分别使用普通变量、原子变量和互斥锁进行10000次递增操作。结果显示,原子变量和互斥锁相比普通变量能避免数据竞争,但原子操作通常具有更高的效率。
该博客通过示例代码展示了多线程环境下,普通变量、原子变量以及互斥锁在并发计数中的性能差异。实验中创建了三个函数,分别使用普通变量、原子变量和互斥锁进行10000次递增操作。结果显示,原子变量和互斥锁相比普通变量能避免数据竞争,但原子操作通常具有更高的效率。
#include <iostream>
#include <vector>
#include <atomic>
#include <thread>
#include <mutex>
using namespace std;
long long a = 0;
atomic<long long> b(0);
long long c = 0;
mutex mt;
void fun1(){
for(int i = 0; i < 10000; i++){
a++;
}
}
void fun2(){
for(int i = 0; i < 10000; i++){
b++;
}
}
void fun3(){
for(int i = 0; i < 10000; i ++){
mt.lock();
c++;
mt.unlock();
}
}
int main(){
vector<thread> save1;
vector<thread> save2;
vector<thread> save3;
clock_t start_time1,end_time1,start_time2,end_time2,start_time3,end_time3;
cout << "P1 ,GO" <<endl;
cout << "P2, GO" <<endl;
cout << "P3, GO" <<endl;
start_time1 = clock();
for(int i = 0; i < 10000; i++){
save1.push_back(thread(fun1));
}
for(auto& a: save1){
a.join();
}
end_time1 = clock();
start_time2 = clock();
for(int i = 0; i < 10000; i++){
save2.push_back(thread(fun2));
}
for(auto& b: save2){
b.join();
}
end_time2 = clock();
start_time3 = clock();
for(int i = 0; i < 10000; i++){
save3.push_back(thread(fun3));
}
for(auto& c: save3){
c.join();
}
end_time3 = clock();
cout << a << " waste time:"<<end_time1- start_time1<<endl;
cout << b << " waste time:"<<end_time2- start_time2<<endl;
cout << c << " waste time:"<<end_time3- start_time3<<endl;
cout << "Final" << endl;
return 0;
}
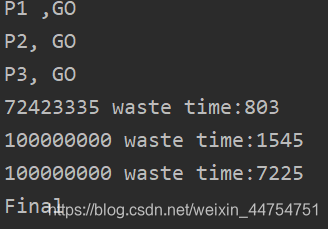
输出结果

















 6851
6851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









