




VideoPatchCore: An Effective Method to Memorize Normality for Video Anomaly Detection 论文阅读
文章信息:

发表于:ACCV 2024(CCF C)
原文链接:https://arxiv.org/pdf/2409.16225
源码:https://github.com/SkiddieAhn/Paper-VideoPatchCore
Abstract
视频异常检测(VAD)是计算机视觉中视频分析和监控领域的一项关键任务。近年来,基于存储正常帧特征的记忆技术使得VAD受到了越来越多的关注。这些存储的特征被用于帧重建,当重建帧与输入帧之间存在显著差异时即可识别异常。然而,这种方法在优化上面临着诸多挑战,因为需要同时优化记忆模块和编码器-解码器模型。这些挑战包括优化难度增加、实现复杂性高以及性能对记忆大小的依赖性较强。为了解决这些问题,我们提出了一种用于VAD的高效记忆方法,称为VideoPatchCore。该方法受到PatchCore的启发,引入了一种优先优化记忆的结构,并针对视频数据的特性设计了三种不同类型的记忆模块。这种方法有效克服了现有基于记忆的方法的局限性,取得了可与最新方法媲美的性能。此外,我们的方法不需要训练,且实现简单,使得VAD任务更为易用。
1 Introduction
视频异常检测(VAD)的任务是识别视频序列中的异常。通常,由于异常事件的稀少性以及难以精确定义其特征,基于深度学习的VAD方法采用单类分类(OCC)技术。OCC方法仅利用正常数据训练模型。在VAD中,主要的OCC方法包括基于重建和预测的方法 [10,18,25,36,38]。这些方法使用编码器-解码器模型,例如自编码器(AEs)、生成对抗网络(GANs)[9]等。在训练过程中,这些模型仅通过正常数据进行训练,以重建或预测帧,其假设是在测试阶段,异常数据将导致较高的重建或预测误差。然而,由于深度学习模型的卓越泛化能力,它们可能为异常数据生成合理的输出,这给这些方法带来了挑战 [12–14, 38]。
最近,在训练过程中将正常数据特征存储在记忆模块中的方法表现出了在减少异常泛化能力方面的性能提升。基于记忆增强的视频异常检测(VAD)方法 [3,8,19,20,23,26,31,32,37] 将正常帧的特征存储在记忆中,并在测试时从记忆中检索相似的特征以生成输入或预测未来帧。在这种情况下,由于异常的相似特征未被存储在记忆中,异常会导致更高的重建或预测误差。图1a展示了这些记忆利用方法。尽管记忆增强方法表现出良好的性能,但它们也存在一些挑战。首先,模型与记忆的同步优化使得优化过程变得困难,且实现复杂。此外,记忆的大小对性能有显著影响 [2, 41]。尽管许多最近的研究 [26, 32] 致力于减少记忆大小,但在大型视频数据集上找到合适的记忆大小仍然是一个难题。
受到PatchCore [30] 的启发,我们提出了VideoPatchCore (VPC),以解决上述记忆利用方法的局限性。如图1b所示,VPC 利用预训练的 CLIP [27] 的视觉编码器,无需额外训练,并通过贪心核集子采样 [1] 优化记忆。这使得即使对于大型数据集,VPC 也能够以较小的记忆开销进行高效的VAD。与用于图像级别的 PatchCore 不同,VPC 通过两个流在视频级别执行异常检测:局部流和全局流。局部流用于检测单个目标的异常,而全局流用于检测整个帧的异常。局部流采用空间记忆库来识别外观异常,并使用时间记忆库检测动作异常。全局流利用高级语义记忆库来检测多个目标之间交互的异常以及需要通过场景分析才能识别的异常(例如错误的方向)。通过使用空间和时间记忆库,VPC 考虑了视频的时空特性;而通过双流方法,它能够检测多种形式的异常。
通过实验,我们验证了在视频领域中使用三种记忆库的有效性。此外,我们引入了两种高效记忆视频特征的方法,并展示了在大型数据集上对于记忆大小的性能鲁棒性。我们提出的 VPC 展现了可与最新技术媲美的良好性能。我们期待 VPC 能够提升视频异常检测领域的易用性,并促进其在实际应用中的落地。
我们的贡献如下:
- 我们提出了 VPC,这是一种基于 PatchCore 的扩展模型,由图像异常检测方法开发而来,用于高效的视频异常检测。
- VPC 采用局部流和全局流两种流式结构,以及空间、时间和高级语义三种记忆库,以捕捉视频的时空特性并检测多种形式的异常。
- VPC 取得了可与最新方法相媲美的良好性能。
2 Related Work
2.1 Reconstruction & prediction-based Video Anomaly Detection
基于重建的方法假设:一个训练用于重建正常视频帧的模型无法准确重建异常帧。Nguyen [25] 提出了一个由一个编码器和两个解码器组成的模型。该模型将第 t t t 帧作为输入,同时预测重建帧和第 t t t 帧与第 t + 1 t+1 t+1 帧之间的光流。Zaheer [38] 使用生成对抗网络(GANs)生成高质量的重建帧。在这种方法中,判别器被训练为将高质量帧分类为正常,将低质量帧分类为异常,同时利用生成器的先前状态来产生低质量帧。
基于预测的方法假设:当模型被训练用于预测正常视频序列的未来或过去帧时,它无法准确预测异常帧。Liu [18] 使用 FlowNet 和生成对抗网络(GANs)从第 t t t 帧预测第 t + 1 t+1 t+1 帧。Yang [36] 提出从第 t t t帧中选择关键帧,并仅基于这些关键帧预测所有第 t t t 帧。
2.2 Video Anomaly Detection using Memory
在视频异常检测(VAD)中,记忆被用来解决在单类分类(OCC)方法中准确生成异常帧的问题。Gong [8] 提出了一种方法,通过将正常帧的特征存储在记忆中,并使用这些存储的记忆项生成正常帧。Park [26] 提出了一种通过聚类相似特征并将聚类中心作为记忆项来学习正常数据的各种模式的方法,从而在紧凑的记忆中存储大量正常特征。Sun [32] 采用对比学习根据特征的类别进行聚类,并将每个特征存储在记忆中。这种技术通过利用物体的语义信息,能够创建一个紧凑的记忆。
2.3 Representation-based Image Anomaly Detection
在图像领域,基于表示的方法作为有效的异常检测方法受到了关注。这种方法利用在大型数据集(如ImageNet [7])上预训练的网络,通过比较正常图像和异常图像的嵌入来检测异常。Cohen [6] 提出了特征金字塔匹配方法,利用网络每一层的不同信息。训练数据的特征被存储在记忆中,并通过与存储在记忆中的特征进行k-NN比较来计算测试数据特征的异常分数。Roth [30] 指出,预训练网络的高级特征专门用于分类任务,这表明需要提取中间层的特征。这些特征被存储在记忆中,并通过核集子采样(Coreset Subsampling)实现记忆优化。
3 Method
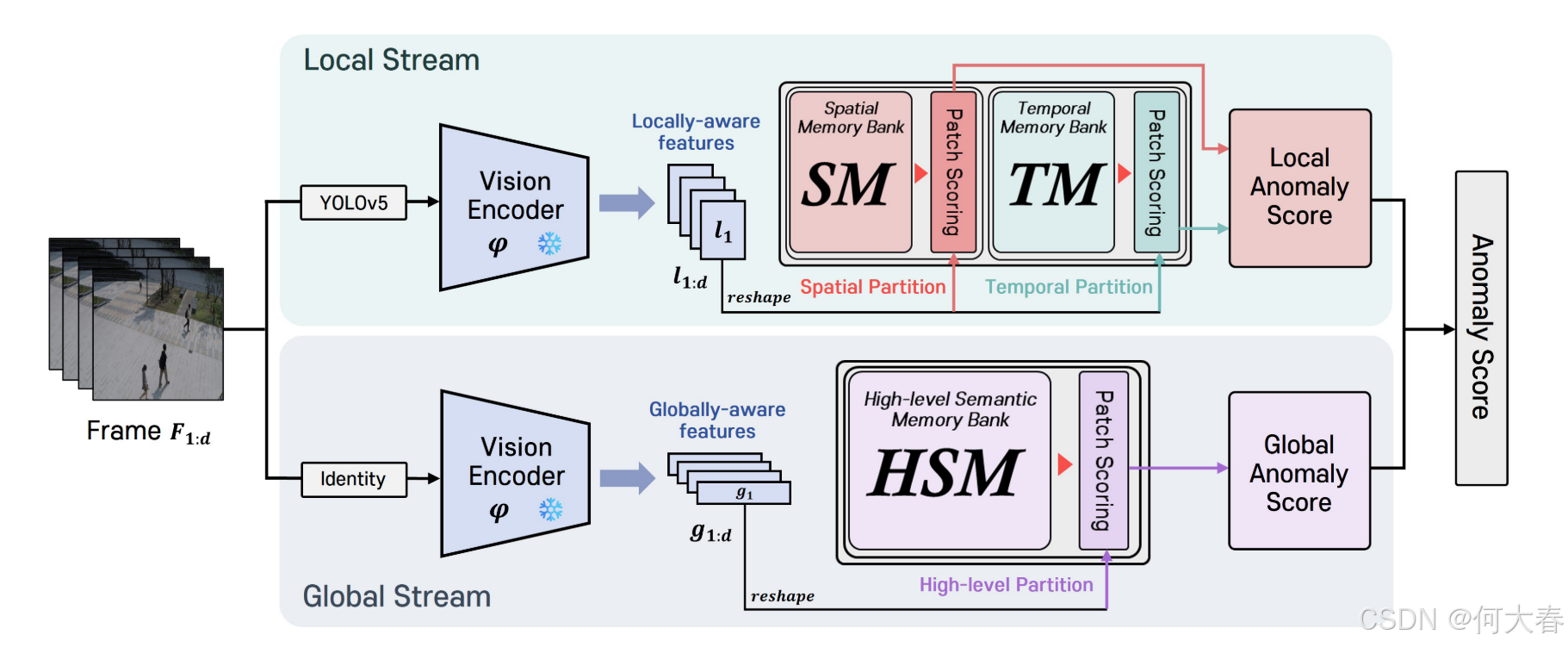
图2:VideoPatchCore (VPC) 的架构。它由两个流(局部流和全局流)和三个记忆库(空间记忆、时间记忆和高级语义记忆)组成。空间记忆库处理目标的外观信息,以识别不合适的目标。时间记忆库处理目标的运动信息,以检测不合适的动作。高级语义记忆库处理帧的全局上下文信息,以识别与多个目标或场景相关的异常。
3.1 Overview
图2展示了所提出的VPC模型,该模型由两个流组成:局部流(针对目标级别)和全局流(针对帧级别)。每个流通过CLIP的视觉编码器提取特征,CLIP已在大规模数据集上进行了预训练,这些特征根据记忆的类型进行分割,并存储在记忆库中进行访问。在此过程中,进行记忆和推理阶段。在记忆阶段,特征被存储在记忆中,并通过来自PatchCore的贪心核集子采样进行优化。在推理阶段,通过计算记忆和特征之间的距离来得出异常分数。接下来将详细描述所提出的VPC的每个组件。
Vision Encoder.我们采用基于CNN的CLIP模型作为编码器,并利用类似于PatchCore的第2层和第3层 φ2、φ3。通常,网络的浅层捕捉局部特征,而深层捕捉全局特征。然而,第一层捕捉到过于详细的特征,如边缘和角落,而最后一层捕捉到偏向分类的特征,这些特征对异常检测没有帮助。因此,我们处理并利用来自中间层 φ2、φ3 的特征。
Local Stream.局部流由YOLOv5 [15] 进行目标检测、视觉编码器 φ 用于特征提取,以及空间记忆(SM)和时间记忆(TM)组成,用于存储目标的外观和运动信息。给定一系列 d 个连续帧 F 1 , F 2 , … , F d ∈ R 3 × H × W F_1, F_2, \dots, F_d \in \mathbb{R}^{3 \times H \times W} F1,F2,…,Fd∈R3×H×W,YOLOv5 为每帧生成一组 n 个目标 O 1 , O 2 , … , O d ∈ R n × 3 × H × W O_1, O_2, \dots, O_d \in \mathbb{R}^{n \times 3 \times H \times W} O1,O2,…,Od∈Rn×3×H×W。随后,生成的局部感知特征 l 1 , l 2 , … , l d ∈ R n × c × h × w l_1, l_2, \dots, l_d \in \mathbb{R}^{n \times c \times h \times w} l1,l2,…,ld∈Rn×c×h×w 代表目标的特征。
具体来说,对来自 φ2 和 φ3 的特征进行平均池化,并基于 φ2进行拼接。此策略旨在整合目标级别异常检测(VAD)所需的细粒度和粗粒度信息。然而,由于 φ2 和 φ3 的感受野相对较小,因此使用池化来整合更大范围的信息。构造 l i l_i li 的公式如下:
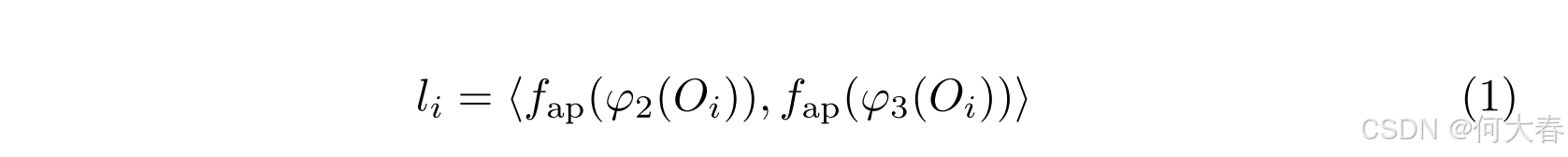
其中, f a p f_{ap} fap表示平均池化, ⟨ ⋅ , ⋅ ⟩ \langle \cdot, \cdot \rangle ⟨⋅,⋅⟩ 表示张量拼接。
随后,将 l 1 : d l_{1:d} l1:d 重塑为 l f ∈ R n × c × d × h × w lf \in \mathbb{R}^{n \times c \times d \times h \times w} lf∈Rn×c×d×h×w。然而, l f lf lf 的维度对于视频处理来说过于庞大。因此,我们采用一种称为分割池化(split pooling)的方法来减少通道数,将其转换为 R n × c ′ × d × h × w \mathbb{R}^{n \times c' \times d \times h \times w} Rn×c′×d×h×w( c ≫ c ′ c \gg c' c≫c′)。该方法的详细信息可参见第4.6节。随后,通过空间分割和时间分割将 l f l_f lf 分别划分为空间块和时间块,并存储在空间记忆(SM)和时间记忆(TM)中。
Global Stream.全局流构建了全局感知特征 g 1 , g 2 , … , g d ∈ R c × 1 × 1 g_1, g_2, \dots, g_d \in \mathbb{R}^{c \times 1 \times 1} g1,g2,…,gd∈Rc×1×1,以捕捉帧的整体上下文,这与局部流专注于帧内单个目标的特点不同。我们利用 φ2 和 φ3,通过全局池化来获取全局信息。具体来说,对每一层的特征应用平均池化,并基于处理更多全局信息的 φ3 进行拼接。在全局池化过程中,同时使用平均池化和最大池化技术,以实现更好的表示。构造 g i g_i gi 的公式如下:
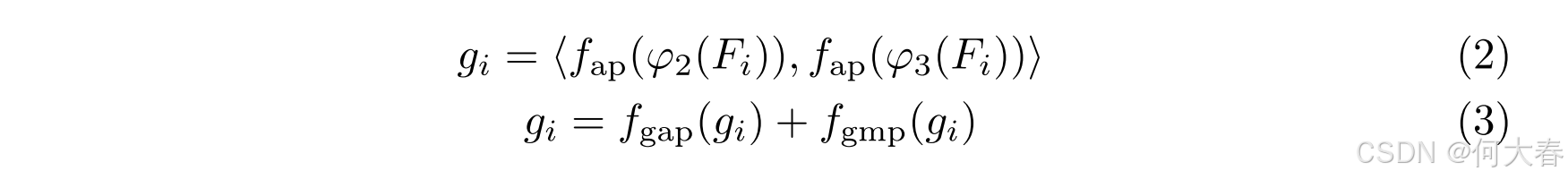
其中, f g a p f_{gap} fgap 和 f g m p f_{gmp} fgmp 分别表示全局平均池化和全局最大池化。
随后, g 1 : d g_{1:d} g1:d 被重塑为 g f ∈ R c × d × 1 × 1 g_f \in \mathbb{R}^{c \times d \times 1 \times 1} gf∈Rc×d×1×1。以这种方式构造的 g f g_f gf 包含了每帧的全局信息,并通过高级分割转换为高级块。之后,这些块被存储在高级语义记忆(HSM)中。
3.2 Patch Partition

图 3:补丁分区方法。‘objects’ 表示物体的数量(n),并且物体在考虑批处理的情况下并行处理。
图3展示了所提出的块划分方法,包括空间划分、时间划分和高级划分。空间划分关注目标的外观信息,在生成块时忽略时间信息;时间划分强调目标的运动信息,在生成块时忽略空间信息;高级划分利用广泛的时空信息生成块,以理解跨帧的上下文信息。以下是对每种划分的详细描述。
Spatial Partition.外观信息对于评估目标异常至关重要,可以从空间特征中提取。我们通过时间全局池化 [16] 对输入特征图 l f lf lf进行压缩,以保留空间信息,同时忽略时间方面的影响。随后,应用平均池化以考虑目标的多个区域。例如,在评估一个人的姿势时,必须结合考虑多个关节。生成 SpatialPatches 的公式如下:
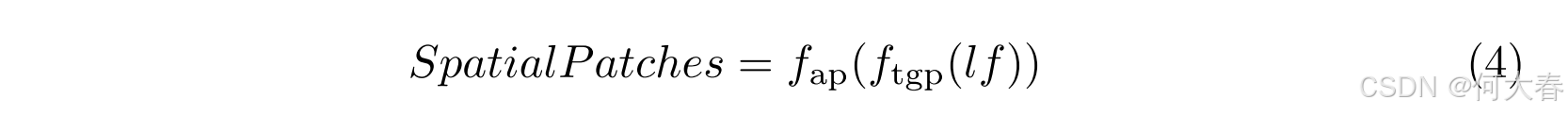
其中, f t g p f_{tgp} ftgp 表示时间全局池化。最终结果被重塑为 R ( n ⋅ h ^ ⋅ w ^ ) × c ′ \mathbb{R}^{(n \cdot \hat{h} \cdot \hat{w}) \times c'} R(n⋅h^⋅w^)×c′,其中 h ≥ h ^ h \geq \hat{h} h≥h^ 且 w ≥ w ^ w \geq \hat{w} w≥w^。
Temporal Partition.目标的运动信息表示随时间的变化,这对于视频异常检测(VAD)至关重要。我们利用 l f lf lf 中相邻的时间信息生成运动特征 m f mf mf。为此,首先计算特征差异,然后通过全局平均池化确定具有代表性的运动值。生成 TemporalPatches 的公式如下:
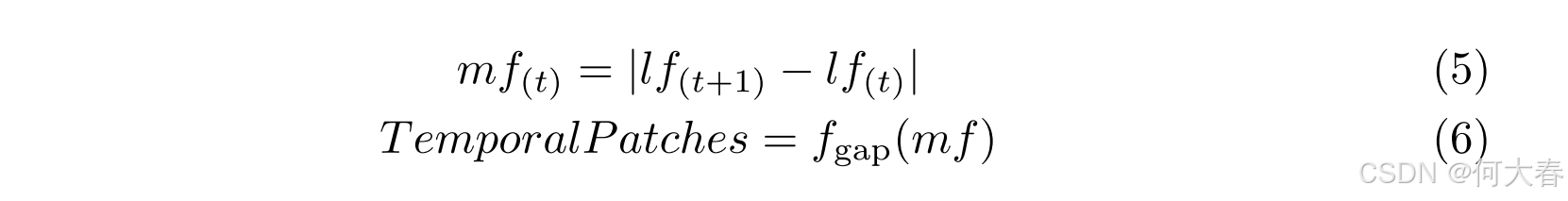
m f ( t ) ∈ R n × c ′ × h × w mf{_{(t)}} \in \mathbb{R}^{n \times c' \times h \times w} mf(t)∈Rn×c′×h×w表示 l f lf lf 中第 t t t帧和第 t + 1 t+1 t+1帧之间的差异,并属于 m f ∈ R n × c ′ × d ^ × h × w mf \in \mathbb{R}^{n \times c' \times \hat{d} \times h \times w} mf∈Rn×c′×d^×h×w,其中 d ^ = d − 1 \hat{d} = d - 1 d^=d−1。最终结果被重塑为 R ( n ⋅ d ^ ) × c ′ \mathbb{R}^{(n \cdot \hat{d}) \times c'} R(n⋅d^)×c′。
High-level Partition.在帧中,全局上下文处理目标与场景之间的关系,并考虑不同目标之间的交互,从而实现更精确的视频异常检测(VAD)。由于 g f gf gf 已经从空间角度包含了全局上下文,因此采用时间金字塔池化来获取高级的时间信息。此外,该方法能够捕获多尺度的时间信息,从而弥补了时间划分方法仅使用相邻时间信息的局限性。生成 HighlevelPatches 的公式如下:
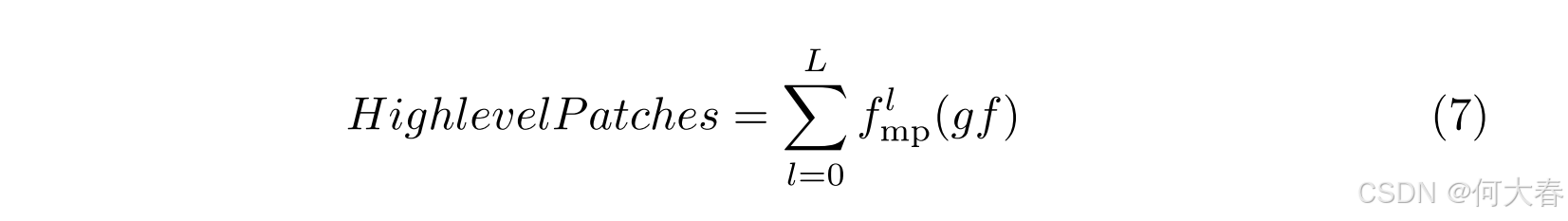
时间金字塔池化通过 f m p l f^l_{mp} fmpl 实现。在这种情况下, f m p l f^l_{mp} fmpl 表示对输入数据执行 l l l次最大池化操作。最终结果被重塑为 R d × c \mathbb{R}^{d \times c} Rd×c。
3.3 Inference
与记忆阶段类似,采用了前述的 Patch Partition 方法。在此过程中,为了提升视频异常检测(VAD)性能,使用了不匹配池化技术。以下是该技术的具体内容及异常分数的计算方法:
Mismatched Pooling.在时间划分过程中,记忆阶段和推理阶段应用了不同的全局池化方法。记忆阶段使用全局平均池化(GAP),而推理阶段则使用全局最大池化(GMP)。由于正常目标通常表现出比异常目标更为静态的特征,我们预计正常的运动特征在平均值和最大值上会相似,而异常运动特征则会在这些值上出现显著差异。通过采用这种方法,可以防止在输入异常数据时从记忆中检索到相似的时间补丁,从而提高VAD性能。该方法有效性的实验验证将在第4.6节中详细描述。
Anomaly Scoring.所有最近邻在从测试帧生成的补丁 X X X和记忆库 M M M 之间计算。随后,从 X X X 中选择代表性补丁 x ∗ x^* x∗,并从 M M M 中选择其最近邻 m ∗ m^* m∗。 x ∗ x^* x∗ 和 m ∗ m^* m∗ 之间的距离 s ∗ s^* s∗被赋值为表示该帧的分数。
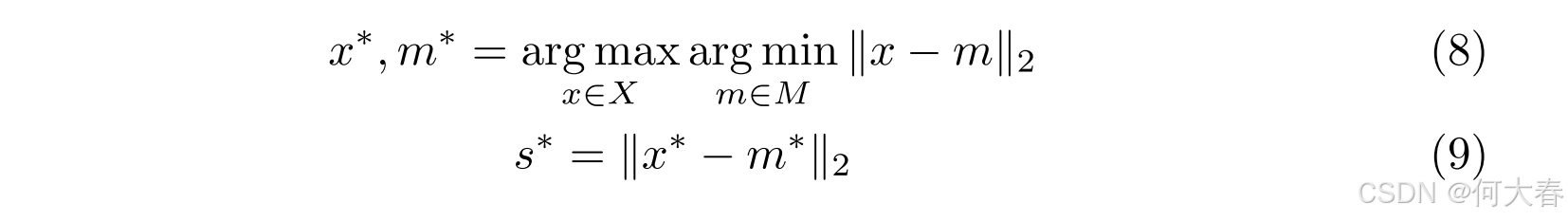
由于使用了三种类型的记忆,因此分别对 SM、TM 和 HSM 计算三次 s ∗ s^* s∗。从 SM 计算的 s ∗ s^* s∗ 空间和从 TM 计算的 s ∗ s^* s∗ 时间决定了局部流中的局部异常分数(LAS)。相反,从 HSM 计算的 s ∗ s^* s∗ 高级被用作全局异常分数(GAS)。最终,LAS 和 GAS 结合起来得出异常分数。计算异常分数的公式如下:
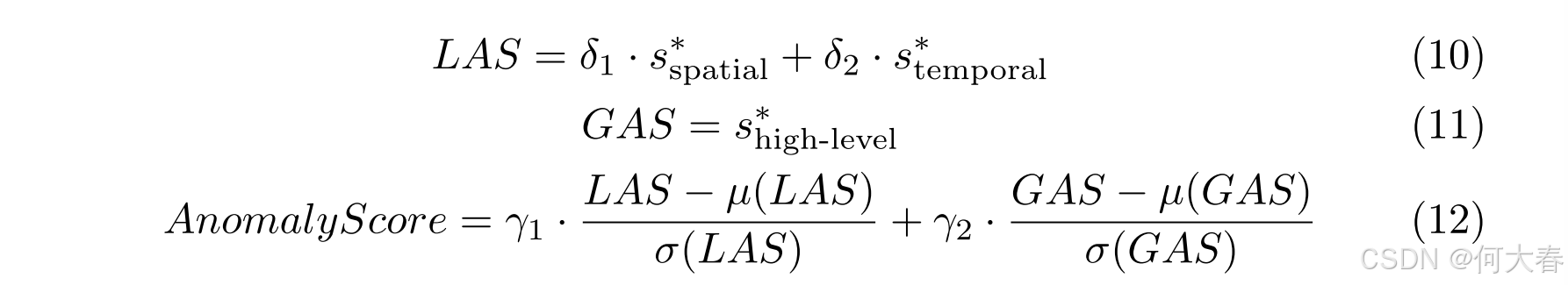
4 Experiments
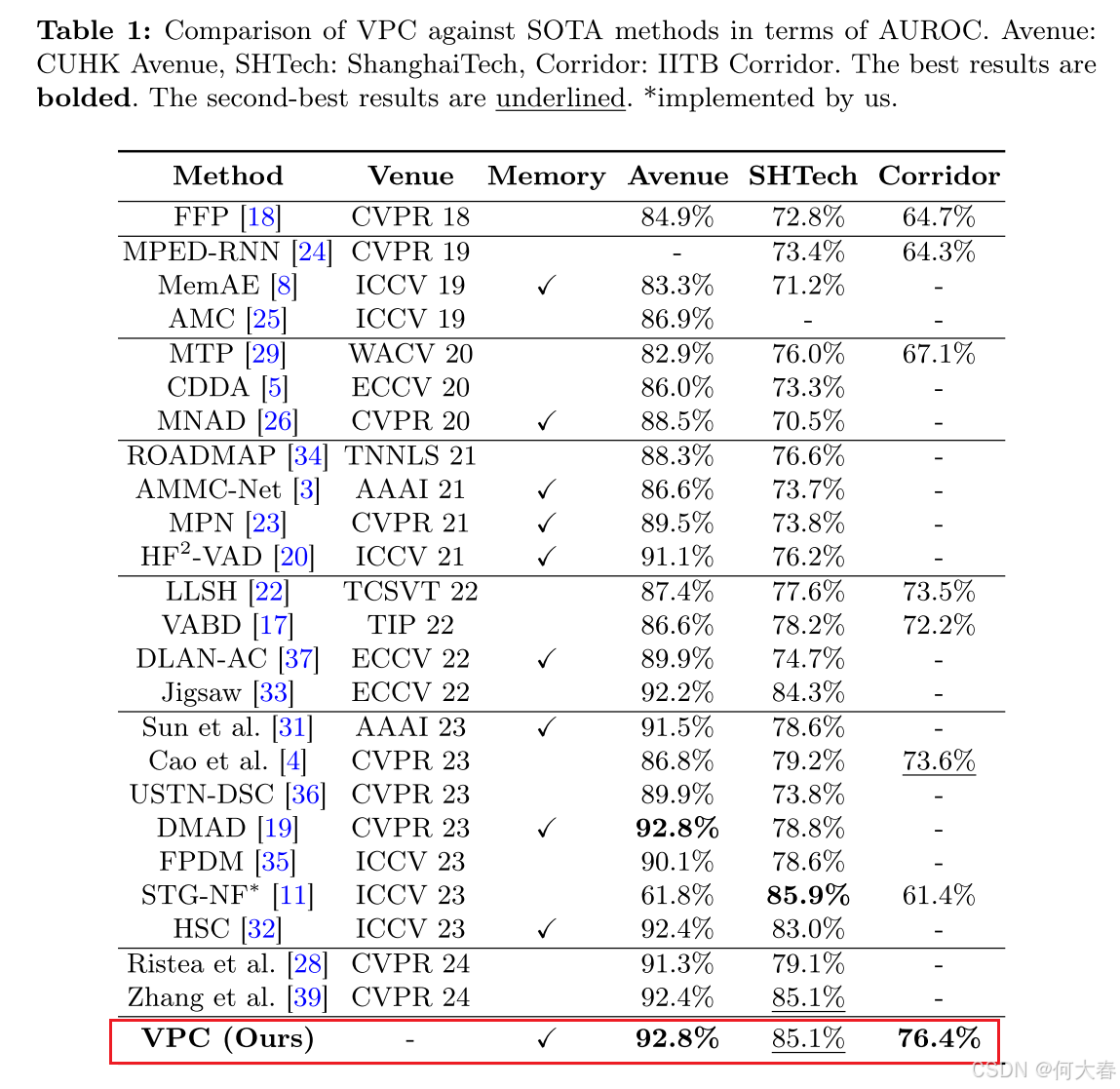
5 Conclusion
我们提出了一个将PatchCore扩展到视频层级的VPC模型。该模型根据视频的特性设计了三种类型的记忆,并通过使用核心集子采样进行记忆优化,从而保持高AUC和FPS。这种方法通过解决传统记忆方法的三个问题(优化难度增加、实现复杂性以及性能对记忆大小的依赖性),可作为VAD中有效的记忆机制。此外,VPC在所有基准数据集上表现出色,并且不需要训练,增加了VAD领域的可访问性。我们预计VPC将在VAD领域做出重要贡献。
阅读总结
这种存储方式会不会稍微简单了一点。时间,空间,全局,局部,感觉深度学习都在这方面不断排列组合,这几个词换一个表达方式又变得高大上了。
最近实验效果总是不理想,到底是idea垃圾还是怎么,感觉对深度学习失去信心了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









