




 本文详细阐述了在数据处理中使用行转列的场景及方法,尤其针对具有多个有限重复属性的大类事物,如学生选课。通过实例,介绍了如何运用pivot函数进行数据转换,并深入解析了pivot语法及其应用技巧。
本文详细阐述了在数据处理中使用行转列的场景及方法,尤其针对具有多个有限重复属性的大类事物,如学生选课。通过实例,介绍了如何运用pivot函数进行数据转换,并深入解析了pivot语法及其应用技巧。
什么情形下需要使用行转列
对于同一类的事物下具有多个属性(属性是有限的),比如说学生选课,每一名可以选择多个课程,而且课程的数量也是有限重复的(对于不通学生选同一门科就相当于是课程重复)。比如说下面这样的数据:
| 姓名 | 班级 | 性别 | 课程 | 分数 |
|---|---|---|---|---|
| 张三 | 一班 | 男 | 高等数学 | 96 |
| 张三 | 一班 | 男 | 复变函数 | 78 |
| 张三 | 一班 | 男 | 英语 | 78 |
| 李四 | 二班 | 男 | 英语 | 98 |
| 李四 | 二班 | 男 | 复变函数 | 78 |
| 李四 | 二班 | 男 | 微积分 | 73 |
可以看到姓名这一列相当于是一个大类,其中包含的属性课程是有限重复的(不需要循环)虽然每个人选择的课程不一定完全相同但是课程总数是有限的。
使用行转列的函数pivot查询后出现如下的结果:
SELECT * FROM STUDENT PIVOT(MIN(S_SCORE) FOR S_COURSE IN ('高等数学', '复变函数', '英语', '微积分'))

下面讲解pivot的语法以及用法:
pivot基本语法格式
SELECT * FROM TABLE_NAME PIVOT(PIVOT_CLAUSE, PIVOT_FOR_CLAUSE, PIVOT_IN_CLAUSE);
语法解释
PIVOT_CLAUSE里面是聚合函数PIVOT_FOR_CLAUSE: for子句,后面接的字段是我们想要将其转换为列的字段PIVOT_IN_CLAUSE:in子句,代表的是对指定的列进行过滤,只会将指定的行转换成列(这里需要注意的是将指定的行转换成列的意思不是说将原来for后面的字段为in里面的内容的行距转换成列,
实际上即使for后面的字段得值不在in子句里面,也是会被转换,只是转换的结果中不会存在这一列而已)
测试数据
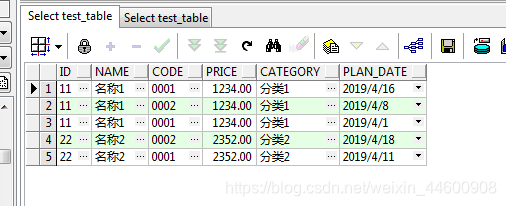
上面的测试数据中可以看到code也是重复的,可以将code转换成行显示,
SELECT * FROM TEST_TABLE PIVOT((MIN(PLAN_DATE) FOR CODE IN('0001' AS CODE_ONE, '0002' AS CODE_TWO));
可以得到如下结果:
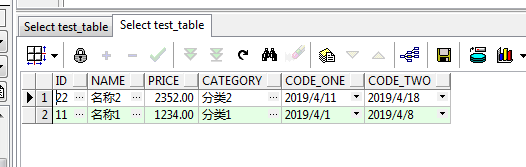
将上面测试数据中的第二条数据的分类改为分类3,得到如下的测试数据:
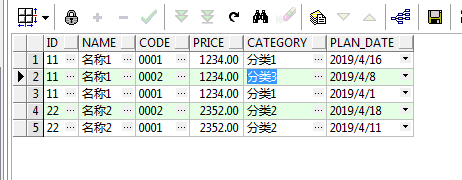
然后使用同样的转换语句:
SELECT * FROM TEST_TABLE PIVOT((MIN(PLAN_DATE) FOR CODE IN('0001' AS CODE_ONE, '0002' AS CODE_TWO));
发现此时的结果有三条。
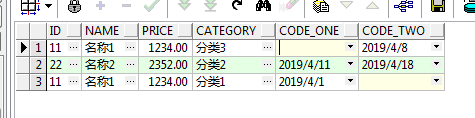
所以转换的结果行数也是有规律的,比如我们上面查询的时候使用的是*,也就是查询所有的列,这样的化去除PIVOT_CLAUSE 和 PIVOT_FOR_CLAUSE两个字段,然后再将其余所有字段分组查询,上面的例子中就是:
select id, name, price, category from test_table group by id, name, price, category;
这样得到的结果行数就是使用pivot后的行数。
查询的结果不仅仅是in子句里面的行数
上面使用pivot查询的时候in子句里面是包含了for子句后面对应字段的所有值,比如code的值有0001以及0002,在in里面也就使用了0001和0002,当我们只是使用其中一个比如0002时:
SELECT * FROM test_table PIVOT(MIN(plan_date) FOR CODE IN ('0002' AS CODE_ONE));
得到的结果如下:
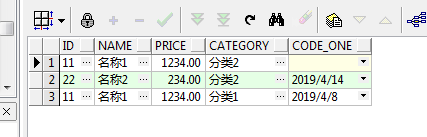
查询结果中是有三条结果的,但是原来的数据中code的值为0002的只有两条,所以这里不要被误导了,这里in里面只有code为0002的不是说原来的数据里面只有code=0002的才需要转换,实际上转换的还是所有的行,只是转换出来的列是少了一个的。
in子句不能使用子查询
上面的in子句里面的内容是固定的,如果在in里面想要使用子查询比如下面的sql:
SELECT * FROM test_table PIVOT(MIN(plan_date) FOR CODE IN (select distinct code from test_table));
使用这种方式是会报错的。在网上搜索的时候看到可以使用存储过程来实现in子句里面使用动态查询,下次再写咯。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









