







 本文详细解析LRU缓存机制原理,通过双向链表和哈希表优化数据结构,实现高效页面调度算法。深入探讨如何利用C++设计LRU缓存,包括关键数据结构的选择与操作逻辑。
本文详细解析LRU缓存机制原理,通过双向链表和哈希表优化数据结构,实现高效页面调度算法。深入探讨如何利用C++设计LRU缓存,包括关键数据结构的选择与操作逻辑。
一、题目描述

二、解题思路
先来看一下什么是
L
R
U
LRU
LRU缓存机制,假设只给一个进程分配三个页框,当发生缺页的时候,
O
S
OS
OS必须选择一个页面将其换出其所在的页框,这个被选择的页面,将是在现有页框中最久没有被使用过的那个。就拿下面这张图为例:
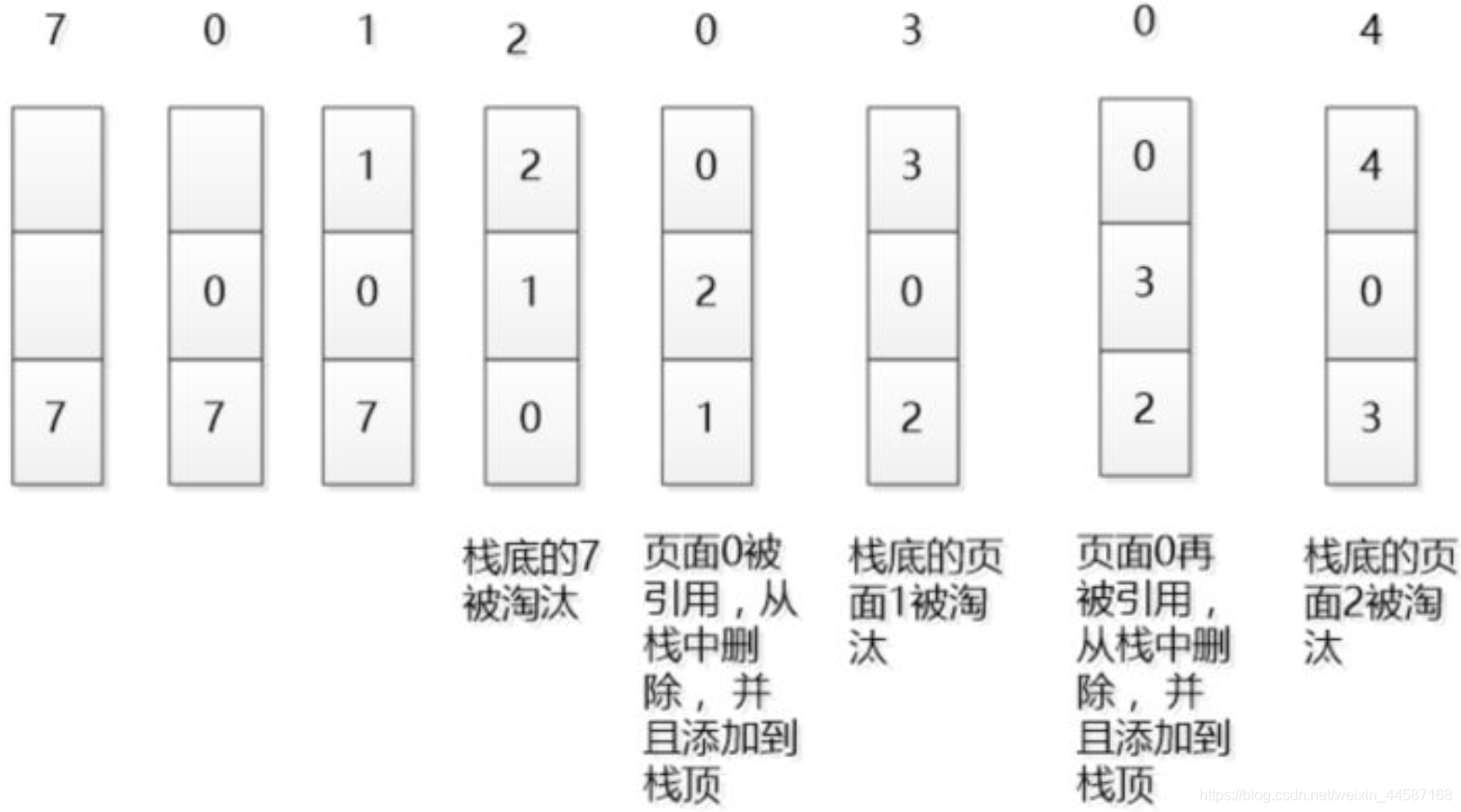
比如我们现在处于第六步:要调入
3
3
3号页面,那么应该从现有页面0、2、1中选择一个调出。由于在
3
3
3号页面前面的序列是
7
,
0
,
1
,
2
,
0
7, 0, 1, 2, 0
7,0,1,2,0,而现有页面是
0
,
2
,
1
0, 2, 1
0,2,1,那么就找
0
,
2
,
1
0, 2, 1
0,2,1这三个数字中在序列中最靠前的那个:第三个数字
1
1
1。
为此,我们可以维护一个序列,这个序列保存着分配的页框内的现存页面的访问顺序,其长度就是分配到的页框数:
- 序列不满(其
s
i
z
e
size
size没有达到分配的页框数
- 当前访问页面在序列内
- 找到该页面在序列中的位置
- 把该位置的元素挪移到序列尾
- 当前访问页面不在序列内
- 直接在序列末尾添加当前访问的页框
- 当前访问页面在序列内
- 序列满
- 当前访问页面在序列内
- 将该页面挪移到序列末尾
- 并更新该页面对应的值
- 当前访问页面不在序列内
- 由上面的分析我们其实可以发现,任意时刻序列的顺序就是访问的时间顺序,越靠前其访问得越早
- 删掉序列开头的元素
- 在序列末尾插入当前访问的序列
- 完成页面的调入
- 当前访问页面在序列内
这里还有两个地方有疑问
- 怎么确定页面是否在序列中,如果在,怎么确定其位置
- 怎么完成页面号与页面值的映射
对于第一个问题,当然可以每次都遍历序列,然后找到结论,但是由于时间复杂度太大,因为运行超时,无法通过最后一个(第
18
18
18个测试用例)。
对于第二个问题,解决映射问题完成
k
e
y
key
key和
v
a
l
u
e
value
value的对应,最好使用
u
n
o
r
d
e
r
e
d
unordered
unordered
m
a
p
map
map。
针对第一个问题进行改进,不应该采用顺序结构,比如数组或者
v
e
c
t
o
r
vector
vector之类,因为如果需要挪移元素将耗费大量的时间。所以应该采用找到位置后可以直接链接的结构,也就是双向链表
l
i
s
t
list
list。
针对第二个问题,
u
n
o
r
d
e
r
e
d
unordered
unordered
m
a
p
map
map的
k
e
y
key
key和
v
a
l
u
e
value
value都是什么?考虑这样一种情况,如果
k
e
y
key
key和
v
a
l
u
e
value
value分别是页号和页面的值,那么即使根据映射从页号得到了页面值,也还是需要在
l
i
s
t
list
list中找到对应
k
e
y
key
key的那个页面并进行操作,时间复杂度还是没有降低。
所以想要根据
u
n
o
r
d
e
r
e
d
unordered
unordered
m
a
p
map
map的
k
e
y
key
key直接找到序列中对应的位置,必须将
u
n
o
r
d
e
r
e
d
unordered
unordered
m
a
p
map
map的
v
a
l
u
e
value
value直接映射成
l
i
s
t
list
list的迭代器,指向要挪移的那个元素在
l
i
s
t
list
list内的位置。所以
u
n
o
r
d
e
r
e
d
unordered
unordered_
m
a
p
map
map应该设计成unordered_map<int, list<pair<int, int>::iterator>,真正完成
k
e
y
key
key与
v
a
l
u
e
value
value的工作,由
l
i
s
t
list
list来做。
知道了思路,来整理下代码逻辑
-
g
e
t
get
get操作
- 如果 u n o r d e r e d unordered unordered_ m a p map map没有找到与 k e y key key对应的迭代器,直接返回 − 1 -1 −1
- 如果存在
k
e
y
key
key对应的迭代器
- 从 u n o r d e r e d unordered unordered_ m a p map map和 l i s t list list里把这个元素抹除
- 更新后再放回到 l i s t list list的末尾
- 重新建立 u n o r d e r e d unordered unordered_ m a p map map中关于 k e y key key的映射,注意此时映射的迭代器应该是 l i s t list list末尾
-
p
u
t
put
put操作:首先调用
g
e
t
get
get,
g
e
t
get
get一下
- 如果
g
e
t
get
get到元素
- 这一定会导致 l i s t list list内顺序的改变,于是交给 p u t put put的任务变成了更新 l i s t list list末尾元素值
- 如果没有
g
e
t
get
get到元素
- 如果
l
i
s
t
list
list未满
- 在 l i s t list list末尾插入元素,并在 u n o r d e r e d unordered unordered_ m a p map map内建立起 k e y key key和迭代器的对应
- 如果
l
i
s
t
list
list已满
- 说明此时应该从 l i s t list list内选择开头的那个旧的页面调出内存,换入新的页面
- 记录下要换出的页面的 k e y key key
- 抹掉 u n o r d e r e d unordered unordered_ m a p map map中和 k e y key key对应的元素
- 抹掉 l i s t list list开头的元素
- 在 l i s t list list末尾插入新的页面
- 在
u
n
o
r
d
e
r
e
d
unordered
unordered
m
a
p
map
map中建立起
k
e
y
key
key和
l
i
s
t
list
list末尾迭代器的映射
注意在 g e t get get操作的时候有一个大坑:抹掉 u n o r d e r e d unordered unordered m a p map map对应元素的之前,一定要先保存一个拷贝,否则从被抹掉的位置得到的迭代器将指向未知的位置引发程序崩溃。
做完这些,我们可以确保从 u n o r d e r e d unordered unordered_ m a p map map中根据 k e y key key取得的任意一个迭代器指向的都是要进行操作的 l i s t list list的位置,降低了时间复杂度。
- 如果
l
i
s
t
list
list未满
- 如果
g
e
t
get
get到元素
三、解题代码
class LRUCache
{
private:
unordered_map<int, list<pair<int, int>>::iterator> ump;
list<pair<int, int>> Lst;
int MaxSize;
int HowMuch;
public:
LRUCache(int capacity)
{
HowMuch = 0;
MaxSize = capacity;
}
int get(int key)
{
if (MaxSize <= 0)
return -1;
auto it = ump.find(key);
int ret = -1;
if (it != ump.end())
{ //找到了
ret = it->second->second; //val
auto tmp = it->second;
ump.erase(ump.find(key));
Lst.erase(tmp);
Lst.push_back(pair<int, int>(key, ret));
ump.insert(make_pair(key, --Lst.end()));
}
return ret;
}
void put(int key, int value)
{
if (MaxSize <= 0)
return;
if (get(key) != -1)
{ //找到了
Lst.rbegin()->second = value;
return;
}
else
{
if (HowMuch < MaxSize)
{
Lst.push_back(make_pair(key, value));
ump.insert(make_pair(key, --Lst.end()));
HowMuch++;
return;
}
else if (HowMuch == MaxSize)
{
auto rm_it = Lst.begin();
ump.erase(ump.find(rm_it->first));
Lst.erase(Lst.begin());
Lst.push_back(make_pair(key, value));
ump.insert(make_pair(key, --Lst.end()));
return;
}
}
}
};
四、运行结果
五、总结
Lst.begin()和Lst.rbegin()不是同一类型的迭代器Lst.begin()是正常的 l i s t list list迭代器Lst.rbegin()是反向 l i s t list list迭代器
- J a v a Java Java有 L i n k e d H a s h M a p LinkedHashMap LinkedHashMap结构,如果 C + + C++ C++也有的话,就不用费劲设计 l i s t list list了

















 927
927

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









