







机器学习多层感知机MLP的Pytorch实现-以表格数据为例-含数据集和PyCharm工程
机器学习预处理-表格数据的分析与可视化中介绍了表格数据的多种可视化方法,帮助我们直观了解表格数据分布和数据格式。
机器学习预处理-表格数据的空值处理中介绍了表格数据的空值处理方法,具体包括均值替换、K类聚等等
现在简单介绍MLP的经典模型的训练流程
代码工程下载链接:机器学习多层感知机MLP的Pytorch实现-以表格数据为例-含数据集的Pycharm工程
目录
1、导入使用的python包
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch
from sklearn.metrics import r2_score, mean_absolute_error, median_absolute_error, mean_absolute_percentage_error
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from torch import optim
from torch.utils.data import TensorDataset, DataLoader
import matplotlib.pyplot as plt
from tqdm import tqdm
import pandas as pd
- numpy:用于高效的数值计算。支持多维数组和矩阵运算,提供大量的数学函数库。
- torch.nn:PyTorch的神经网络库。提供构建神经网络的模块和层,如全连接层(Linear)、卷积层(Conv2d)、循环层(LSTM)等。
- torch.nn.functional:包含神经网络中常用的函数,如激活函数(ReLU、sigmoid等)、损失函数(CrossEntropyLoss、MSELoss等)。这些函数通常用于定义前向传播的计算。
- torch:PyTorch的核心库。提供张量(Tensor)操作、自动微分(autograd)、优化器(optim)、数据加载(data loading)等功能。
- sklearn.metrics:包含评估机器学习模型性能的指标。如R²分数(r2_score)、平均绝对误差(mean_absolute_error)、中位数绝对误差(median_absolute_error)、平均绝对百分比误差(mean_absolute_percentage_error)和均方误差(mean_squared_error)等。
- sklearn.model_selection:提供模型选择和评估的工具。如train_test_split函数,用于将数据集分割为训练集和测试集。
- sklearn.preprocessing:提供数据预处理功能。如StandardScaler,用于特征缩放,使数据具有零均值和单位方差。
- torch.optim:提供各种优化算法,用于神经网络的训练。如SGD、Adam等优化器。
- torch.utils.data:提供数据加载和处理的工具。
- matplotlib.pyplot:用于数据可视化。
- tqdm:提供快速、可扩展的进度条。
- pandas:提供高性能、易于使用的数据结构和数据分析工具。
2、创建神经网络MLP
# 定义多层感知机(MLP)类,继承自nn.Module
class MLP(nn.Module):
# 类的初始化方法
def __init__(self):
# 调用父类nn.Module的初始化方法
super(MLP, self).__init__()
self.hidden1 = nn.Linear(in_features=8, out_features=50, bias=True)
self.hidden2 = nn.Linear(50, 50)
self.hidden3 = nn.Linear(50, 50)
self.hidden4 = nn.Linear(50, 50)
self.predict = nn.Linear(50, 1)
# 定义前向传播方法
def forward(self, x):
# x是输入数据,通过第一个隐藏层并应用ReLU激活函数
x = F.relu(self.hidden1(x))
x = F.relu(self.hidden2(x))
x = F.relu(self.hidden3(x))
x = F.relu(self.hidden4(x))
output = self.predict(x)
# 将输出展平为一维张量
# out = output.view(-1)
return output
3、数据集的处理
3.1 数据集读取
# 读取 Excel 文件
file_path = 'datasets/housing/housing_fill_kmeans.csv' # 替换为你的 Excel 文件路径
data = pd.read_csv(file_path)
# 提取特征和目标变量 latitude housing_median_age total_rooms total_bedrooms population households median_income
X = data.loc[:, ['longitude', 'latitude', 'housing_median_age', 'total_rooms', 'total_bedrooms',
'population', 'households', 'median_income']]
Y = data.loc[:, ['median_house_value']] # 目标变量
3.2 数据集分割
此处70%用于训练,15%用于验证,15%用于测试:
x_train, x_test_tmp, y_train, y_test_tmp = train_test_split(X, Y, test_size=0.3,
random_state=42)
x_valid, x_test, y_valid, y_test = train_test_split(x_test_tmp, y_test_tmp, test_size=0.5,
random_state=42)
3.3 数据集的标准化
使用的是StandardScaler()的标准化函数进行:
scale_x = StandardScaler()
scale_y = StandardScaler()
x_train_s = scale_x.fit_transform(x_train)
x_valid_s = scale_x.transform(x_valid)
x_test_s = scale_x.transform(x_test)
y_train_s = scale_y.fit_transform(y_train)
y_valid_s = scale_y.fit_transform(y_valid)
y_test_s = scale_y.fit_transform(y_test)
4、迭代过程
4.1 优化器、学习率下降、损失函数设置
optimizer = optim.SGD(model.parameters(), lr)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10000, gamma=0.96)
loss_func = nn.MSELoss()
4.2 训练Train
# 遍历数据生成器gen提供的批次数据,enumerate会同时返回迭代次数(iteration)和批次数据(batch)
for iteration, batch in enumerate(gen):
# 如果迭代次数达到或超过设定的epoch大小,则跳出循环
if iteration >= epoch_size:
break
# 将批次中的数据和目标(标签)转移到指定的设备(如GPU)上
data, target = [b.to(device) for b in batch]
# 清零优化器的梯度,因为默认情况下梯度是累加的
optimizer.zero_grad()
# 将数据输入模型进行前向传播,得到输出
output = model(data)
# 计算输出和目标之间的损失
loss = loss_func(output, target)
# 反向传播,计算损失对模型参数的梯度
loss.backward()
# 使用优化器更新模型参数
optimizer.step()
# 累加损失值,用于后续计算平均损失
total_loss += loss.item()
# 计算当前迭代下的平均训练损失
train_loss = total_loss / (iteration + 1)
# 计算训练集上的R^2分数(决定系数),用于评估模型性能
# 注意:这里使用r2_score可能意味着目标变量是回归问题中的连续值
train_acc = r2_score(target.cpu().detach().numpy(), output.cpu().detach().numpy())
# 计算训练集上的均方根误差(RMSE),也是评估回归模型性能的常用指标
val_rmse = np.sqrt(mean_squared_error(target.cpu().detach().numpy(), output.cpu().detach().numpy()))
# 更新进度条(假设pbar是一个进度条对象),显示当前的总损失、学习率和训练集上的RMSE
pbar.set_postfix(**{"total_loss": train_loss,
"learning_rate:": optimizer.state_dict()['param_groups'][0]['lr'], # 获取当前学习率
"train_rmse": val_rmse})
# 更新进度条,表示当前批次处理完成
pbar.update(1)
4.3 每个epoch迭代的验证部分
# 遍历验证集数据生成器gen_val提供的批次数据
for iteration, batch in enumerate(gen_val):
# 如果迭代次数达到或超过验证集的epoch大小(或批次数量),则跳出循环
if iteration >= epoch_size_val:
break
# 将批次中的数据和目标(标签)转移到指定的设备(如GPU)上
data, target = [b.to(device) for b in batch] # 转移到GPU
# 注意:在验证过程中,我们不需要清零梯度或进行反向传播
# optimizer.zero_grad() # 这行在验证过程中应该被注释掉或省略
# 将数据输入模型进行前向传播,得到输出
output = model(data)
# 计算输出和目标之间的损失
loss = loss_func(output, target)
# 累加验证集上的损失值,用于后续计算平均损失
total_val_loss += loss.item()
# 计算当前迭代下的平均验证损失
val_loss = total_val_loss / (iteration + 1)
# 计算验证集上的R^2分数(决定系数),用于评估模型性能
val_acc = r2_score(target.cpu().detach().numpy(), output.cpu().detach().numpy())
# 注意:虽然这里使用了变量名val_acc,但R^2分数通常用于回归问题,不是分类准确率
# 计算验证集上的均方根误差(RMSE),也是评估回归模型性能的常用指标
val_rmse = np.sqrt(mean_squared_error(target.cpu().detach().numpy(), output.cpu().detach().numpy()))
# 更新进度条(假设pbar是一个进度条对象),显示当前的验证损失和RMSE
pbar.set_postfix(**{"val_loss": val_loss,
"val_rmse": val_rmse})
# 更新进度条,表示当前批次处理完成
pbar.update(1)
5、数据绘图和结果打印
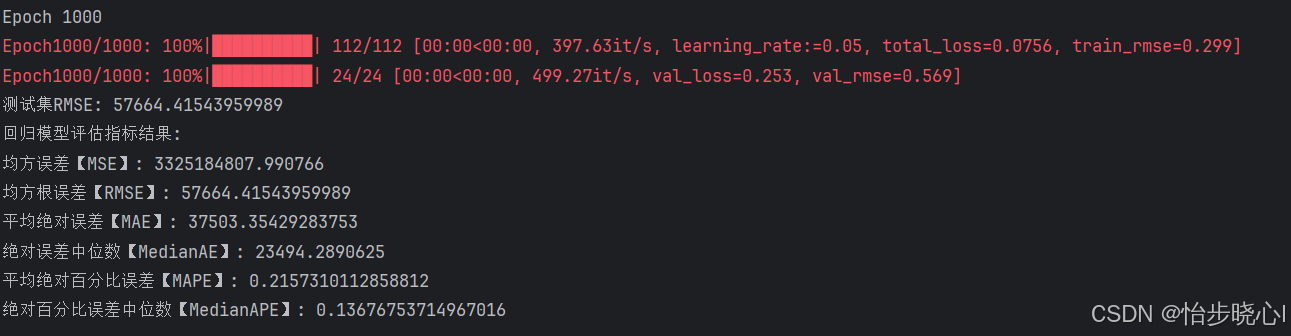
5.1 评估指标结果
def regression_metrics(true, pred):
print('回归模型评估指标结果:')
print('均方误差【MSE】:', mean_squared_error(true, pred))
print('均方根误差【RMSE】:', np.sqrt(mean_squared_error(true, pred)))
print('平均绝对误差【MAE】:', mean_absolute_error(true, pred))
print('绝对误差中位数【MedianAE】:', median_absolute_error(true, pred))
print('平均绝对百分比误差【MAPE】:', mean_absolute_percentage_error(true, pred))
print('绝对百分比误差中位数【MedianAPE】:', median_absolute_percentage_error(true, pred))
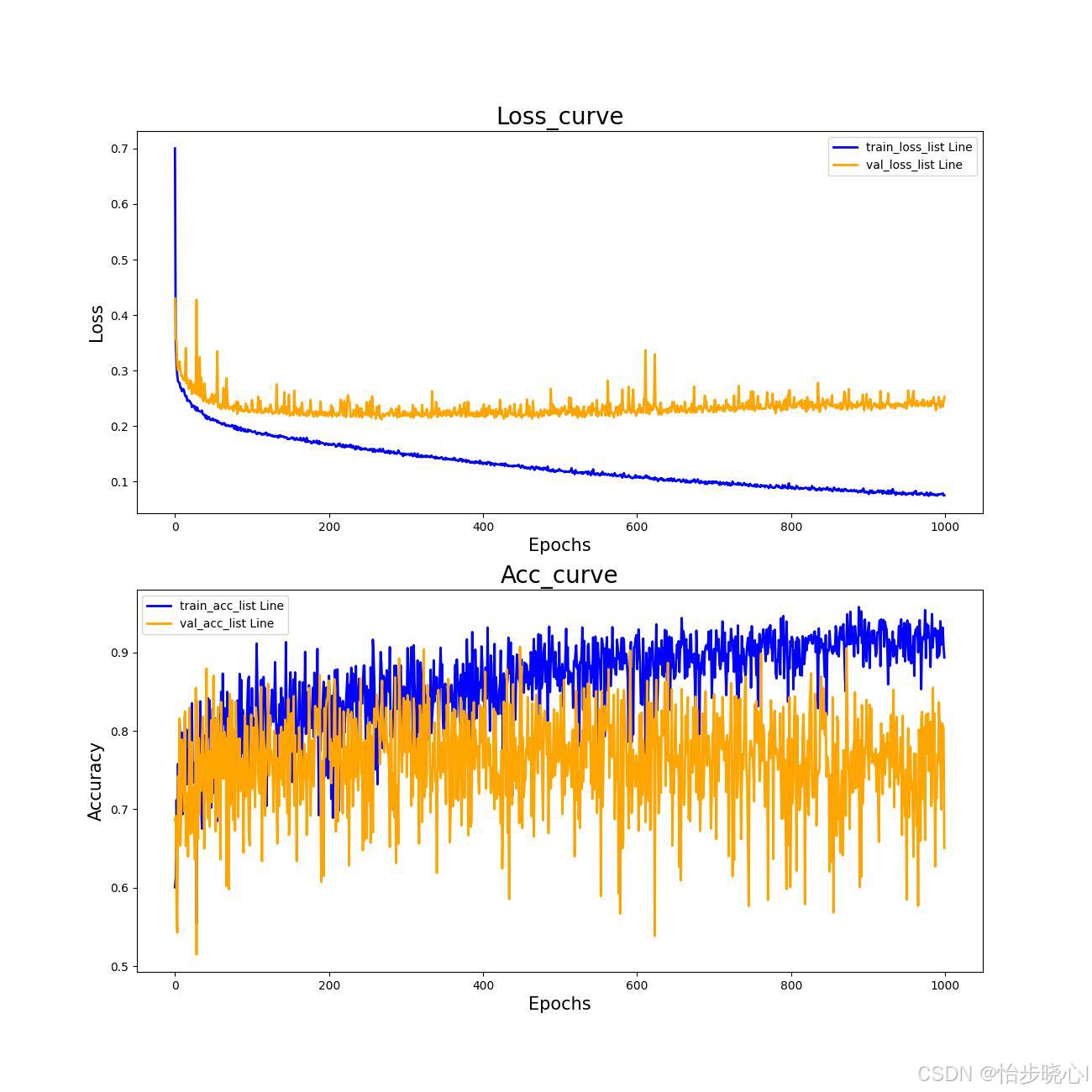
5.2 训练准确率和Loss曲线
def draw_plot(Full_Epoch, train_loss_list, train_acc_list, val_loss_list, val_acc_list):
x = range(0, Full_Epoch)
y1 = train_loss_list
y2 = val_loss_list
y3 = train_acc_list
y4 = val_acc_list
plt.figure(figsize=(13, 13))
plt.subplot(2, 1, 1)
plt.plot(x, train_loss_list, color="blue", label="train_loss_list Line", linewidth=2)
plt.plot(x, val_loss_list, color="orange", label="val_loss_list Line", linewidth=2)
plt.title("Loss_curve", fontsize=20)
plt.xlabel(xlabel="Epochs", fontsize=15)
plt.ylabel(ylabel="Loss", fontsize=15)
plt.legend()
plt.subplot(2, 1, 2)
plt.plot(x, train_acc_list, color="blue", label="train_acc_list Line", linewidth=2)
plt.plot(x, val_acc_list, color="orange", label="val_acc_list Line", linewidth=2)
plt.title("Acc_curve", fontsize=20)
plt.xlabel(xlabel="Epochs", fontsize=15)
plt.ylabel(ylabel="Accuracy", fontsize=15)
plt.legend()
plt.savefig("Loss&acc.jpg")
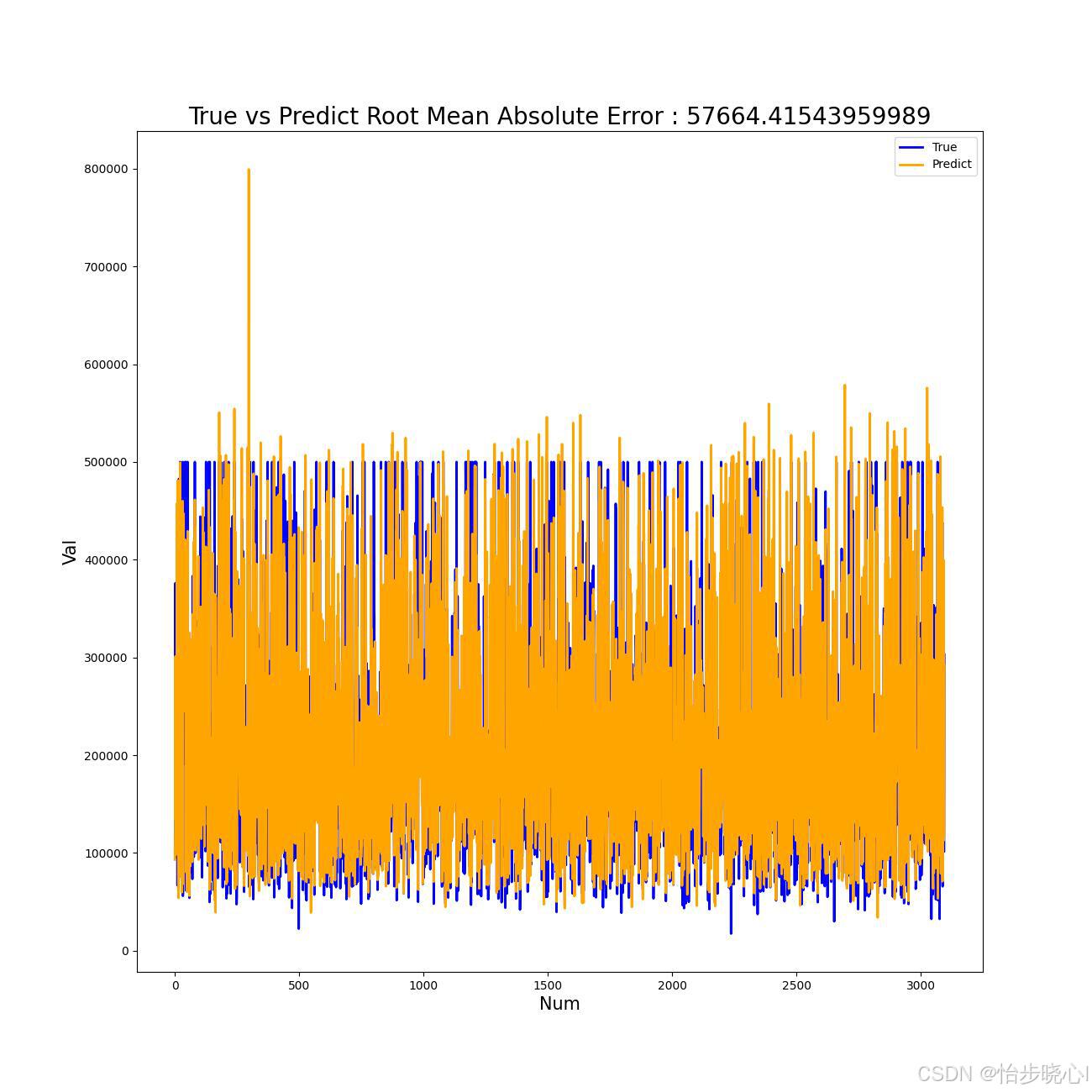
5.3 预测值和真实值对比
# 误差绘图
x = range(0, y_test.shape[0])
plt.figure(figsize=(13, 13))
plt.plot(x, y_test[::, 0], color="blue", label="True", linewidth=2)
plt.plot(x, predict[::, 0], color="orange", label="Predict", linewidth=2)
plt.title(f"True vs Predict Root Mean Absolute Error : {val_rmse}", fontsize=20)
plt.xlabel(xlabel="Num", fontsize=15)
plt.ylabel(ylabel="Val", fontsize=15)
plt.legend()
plt.savefig("MLP_Out.jpg")
6 完整代码
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch
from sklearn.metrics import r2_score, mean_absolute_error, median_absolute_error, mean_absolute_percentage_error
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from torch import optim
from torch.utils.data import TensorDataset, DataLoader
import matplotlib.pyplot as plt
from tqdm import tqdm
import pandas as pd
# 定义多层感知机(MLP)类,继承自nn.Module
class MLP(nn.Module):
# 类的初始化方法
def __init__(self):
# 调用父类nn.Module的初始化方法
super(MLP, self).__init__()
self.hidden1 = nn.Linear(in_features=8, out_features=50, bias=True)
self.hidden2 = nn.Linear(50, 50)
self.hidden3 = nn.Linear(50, 50)
self.hidden4 = nn.Linear(50, 50)
self.predict = nn.Linear(50, 1)
# 定义前向传播方法
def forward(self, x):
# x是输入数据,通过第一个隐藏层并应用ReLU激活函数
x = F.relu(self.hidden1(x))
x = F.relu(self.hidden2(x))
x = F.relu(self.hidden3(x))
x = F.relu(self.hidden4(x))
output = self.predict(x)
# 将输出展平为一维张量
# out = output.view(-1)
return output
scale_x = StandardScaler()
scale_y = StandardScaler()
# 使用 fetch_california_housing 函数从 sklearn.datasets 模块中加载加州房价数据集。
# 这个数据集包含了20640个样本和8个特征变量(如房屋中位年龄、总收入中位数等),以及一个目标变量(房屋价格中位数)。
def dataset():
# 读取 Excel 文件
file_path = 'datasets/housing/housing_fill_kmeans.csv' # 替换为你的 Excel 文件路径
data = pd.read_csv(file_path)
# 提取特征和目标变量 latitude housing_median_age total_rooms total_bedrooms population households median_income
X = data.loc[:, ['longitude', 'latitude', 'housing_median_age', 'total_rooms', 'total_bedrooms',
'population', 'households', 'median_income']]
# X = data.loc[:, ['housing_median_age', 'total_rooms',
# 'population', 'median_income']]
# 样本数据
Y = data.loc[:, ['median_house_value']] # 目标变量
x_train, x_test_tmp, y_train, y_test_tmp = train_test_split(X, Y, test_size=0.3,
random_state=42)
x_valid, x_test, y_valid, y_test = train_test_split(x_test_tmp, y_test_tmp, test_size=0.5,
random_state=42)
# 创建一个 StandardScaler 对象,用于特征缩放。
x_train_s = scale_x.fit_transform(x_train)
x_valid_s = scale_x.transform(x_valid)
x_test_s = scale_x.transform(x_test)
# print(scale_x.mean_)
# print(scale_x.scale_)
# joblib.dump(scale_x, 'scaler_x.joblib')
y_train_s = scale_y.fit_transform(y_train)
y_valid_s = scale_y.fit_transform(y_valid)
y_test_s = scale_y.fit_transform(y_test)
# print(scale_y.mean_)
# print(scale_y.scale_)
# joblib.dump(scale_y, 'scaler_y.joblib')
return x_train_s, x_valid_s, x_test_s, y_train_s, y_valid_s, y_test_s
def draw_plot(Full_Epoch, train_loss_list, train_acc_list, val_loss_list, val_acc_list):
x = range(0, Full_Epoch)
y1 = train_loss_list
y2 = val_loss_list
y3 = train_acc_list
y4 = val_acc_list
plt.figure(figsize=(13, 13))
plt.subplot(2, 1, 1)
plt.plot(x, train_loss_list, color="blue", label="train_loss_list Line", linewidth=2)
plt.plot(x, val_loss_list, color="orange", label="val_loss_list Line", linewidth=2)
plt.title("Loss_curve", fontsize=20)
plt.xlabel(xlabel="Epochs", fontsize=15)
plt.ylabel(ylabel="Loss", fontsize=15)
plt.legend()
plt.subplot(2, 1, 2)
plt.plot(x, train_acc_list, color="blue", label="train_acc_list Line", linewidth=2)
plt.plot(x, val_acc_list, color="orange", label="val_acc_list Line", linewidth=2)
plt.title("Acc_curve", fontsize=20)
plt.xlabel(xlabel="Epochs", fontsize=15)
plt.ylabel(ylabel="Accuracy", fontsize=15)
plt.legend()
plt.savefig("Loss&acc.jpg")
# 修改训练循环以确保数据和模型都在GPU上
def train_one_epoch(model, loss_func, epoch, epoch_size, epoch_size_val, gen, gen_val, Full_Epoch):
train_loss = 0
val_loss = 0
total_loss = 0
total_val_loss = 0
print(f"Epoch {epoch + 1}")
with tqdm(total=epoch_size, desc=f'Epoch{epoch + 1}/{Full_Epoch}', postfix=dict, mininterval=0.3) as pbar:
for iteration, batch in enumerate(gen):
if iteration >= epoch_size:
break
data, target = [b.to(device) for b in batch] # 将数据转移到GPU
optimizer.zero_grad()
output = model(data)
loss = loss_func(output, target)
loss.backward()
optimizer.step()
total_loss += loss.item()
train_loss = total_loss / (iteration + 1)
train_acc = r2_score(target.cpu().detach().numpy(), output.cpu().detach().numpy())
val_rmse = np.sqrt(mean_squared_error(target.cpu().detach().numpy(), output.cpu().detach().numpy()))
pbar.set_postfix(**{"total_loss": train_loss,
"learning_rate:": optimizer.state_dict()['param_groups'][0]['lr'],
"train_rmse": val_rmse})
pbar.update(1)
# 验证过程同样需要确保数据和模型在GPU上
with tqdm(total=epoch_size_val, desc=f'Epoch{epoch + 1}/{Full_Epoch}', postfix=dict, mininterval=0.3) as pbar:
for iteration, batch in enumerate(gen_val):
if iteration >= epoch_size_val:
break
data, target = [b.to(device) for b in batch] # 转移到GPU
optimizer.zero_grad()
output = model(data)
loss = loss_func(output, target)
total_val_loss += loss.item()
val_loss = total_val_loss / (iteration + 1)
val_acc = r2_score(target.cpu().detach().numpy(), output.cpu().detach().numpy())
val_rmse = np.sqrt(mean_squared_error(target.cpu().detach().numpy(), output.cpu().detach().numpy()))
pbar.set_postfix(**{"val_loss": val_loss,
"val_rmse": val_rmse})
pbar.update(1)
if epoch + 1 == Full_Epoch:
torch.save(model.state_dict(),
'weights/mlp_weights-epoch%d-Total_loss%.4f-val_loss%.4f.pkl' % (
(epoch + 1), train_loss, val_loss / (iteration + 1)))
return train_loss, train_acc, val_loss, val_acc
def median_absolute_percentage_error(y_true, y_pred):
return np.median(np.abs((y_pred - y_true) / y_true))
def regression_metrics(true, pred):
print('回归模型评估指标结果:')
print('均方误差【MSE】:', mean_squared_error(true, pred))
print('均方根误差【RMSE】:', np.sqrt(mean_squared_error(true, pred)))
print('平均绝对误差【MAE】:', mean_absolute_error(true, pred))
print('绝对误差中位数【MedianAE】:', median_absolute_error(true, pred))
print('平均绝对百分比误差【MAPE】:', mean_absolute_percentage_error(true, pred))
print('绝对百分比误差中位数【MedianAPE】:', median_absolute_percentage_error(true, pred))
# tensor = torch.zeros(64,8).requires_grad_(True)
# net = model(tensor)
# #结构可视化
# net_strc = make_dot(net, params = dict(list(model.named_parameters()) + [('tensor',tensor)]))
# net_strc.view()
# 检查是否有可用的GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
Full_Epoch = 1000
Batch_size = 128
lr = 5e-2
loss_and_acc_curve = True
train_loss_list = []
val_loss_list = []
train_acc_list = []
val_acc_list = []
x_train_s, x_valid_s, x_test_s, y_train_s, y_valid_s, y_test_s = dataset()
x_train_st = torch.from_numpy(x_train_s.astype(np.float32)).to(device)
x_valid_st = torch.from_numpy(x_valid_s.astype(np.float32)).to(device)
x_test_st = torch.from_numpy(x_test_s.astype(np.float32)).to(device)
y_train_t = torch.from_numpy(y_train_s.astype(np.float32)).to(device)
y_valid_t = torch.from_numpy(y_valid_s.astype(np.float32)).to(device)
y_test_t = torch.from_numpy(y_test_s.astype(np.float32)).to(device)
train_dataset = TensorDataset(x_train_st, y_train_t)
valid_dataset = TensorDataset(x_valid_st, y_valid_t)
gen = DataLoader(train_dataset, batch_size=Batch_size, num_workers=0,
pin_memory=False, drop_last=True, shuffle=True)
gen_val = DataLoader(valid_dataset, batch_size=Batch_size, num_workers=0,
pin_memory=False, drop_last=True, shuffle=True)
# 定义模型并将其转移到GPU
model = MLP().to(device)
optimizer = optim.SGD(model.parameters(), lr)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10000, gamma=0.96)
loss_func = nn.MSELoss()
# loss_func = MAPELoss()
# nn.Loss
epoch_size = y_train_t.size(0) // Batch_size
epoch_size_val = y_valid_t.size(0) // Batch_size
for epoch in range(0, Full_Epoch):
train_loss, train_acc, val_loss, val_acc = train_one_epoch(model, loss_func, epoch, epoch_size, epoch_size_val, gen,
gen_val, Full_Epoch)
scheduler.step()
train_loss_list.append(train_loss)
train_acc_list.append(train_acc)
val_loss_list.append(val_loss)
val_acc_list.append(val_acc)
# 模型测试
output = model(x_test_st)
predict = scale_y.inverse_transform(output.cpu().detach().numpy())
y_test = scale_y.inverse_transform(y_test_s)
# val_rmse = np.sqrt(mean_squared_error(y_test_t.cpu().detach().numpy(), output.cpu().detach().numpy()))
# print('测试集RMSE: ' + val_rmse.__str__())
# regression_metrics(y_test_t.cpu().detach().numpy(), output.cpu().detach().numpy())
val_rmse = np.sqrt(mean_squared_error(y_test, predict))
print('测试集RMSE: ' + val_rmse.__str__())
regression_metrics(y_test, predict)
# 误差绘图
x = range(0, y_test.shape[0])
plt.figure(figsize=(13, 13))
plt.plot(x, y_test[::, 0], color="blue", label="True", linewidth=2)
plt.plot(x, predict[::, 0], color="orange", label="Predict", linewidth=2)
plt.title(f"True vs Predict Root Mean Absolute Error : {val_rmse}", fontsize=20)
plt.xlabel(xlabel="Num", fontsize=15)
plt.ylabel(ylabel="Val", fontsize=15)
plt.legend()
plt.savefig("MLP_Out.jpg")
if loss_and_acc_curve:
draw_plot(Full_Epoch, train_loss_list, train_acc_list, val_loss_list, val_acc_list)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











