




文字转语音目前在人们的生活和工作中发挥着很大的作用;没事的时候人们总是喜欢看看手机新闻或者玩玩电脑游戏,我们在看新闻的内容时,长时间的盯着屏幕看文字,很快会让眼睛变的疲劳,如果想要让眼睛得到休息又能够获取新闻内容的话,有一个办法可以帮到你!

文字转语音少不了下面这个方法:
使用方法介绍:
1:打开这个转换小助手后,页面会停留在文字转语音的界面上。
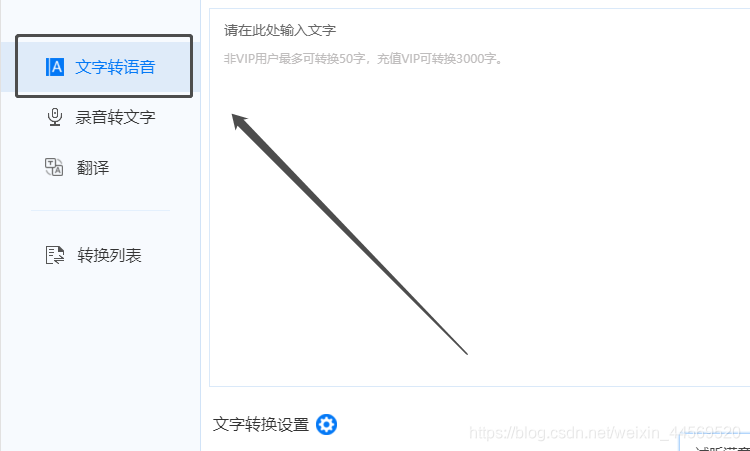
2:我们在旁边的界面上开始输入要进行转换的文字内容,在页面中有输入文字的提示,鼠标单击就可以进行文字输入。
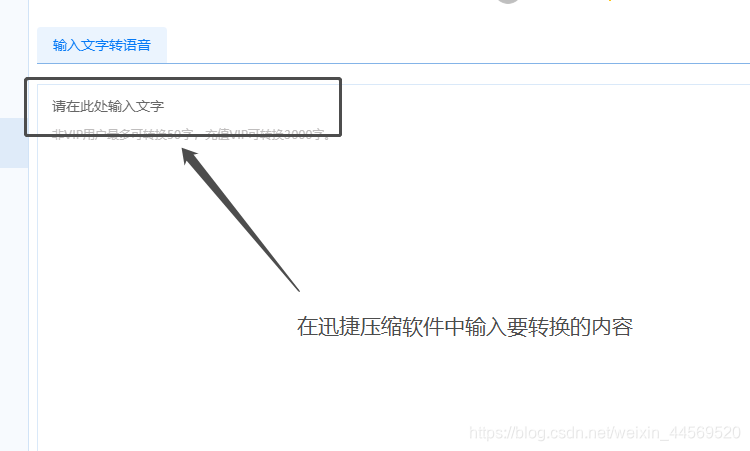
3:文字输入完成后,如果想换掉这段文字,最方便的方法就是点击清空文本的按钮,一键就可以将文字全部清空。
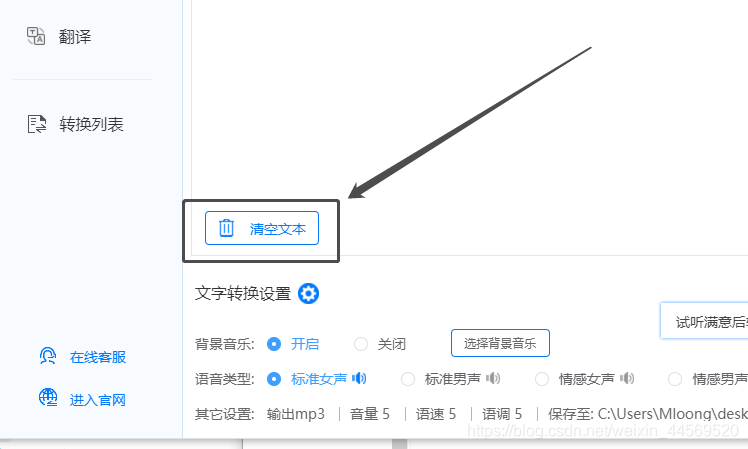
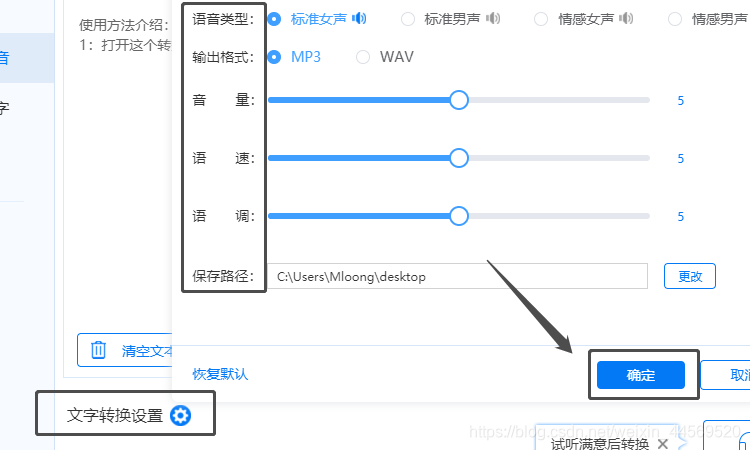
4:等确定好要进行转换的文字后,选择一个文字转换设置,页面下方设置的有语音类型和其他设置,我们可以点击蓝色的设置按钮,会有一个弹窗,里面有更多的设置,调节至自己适合的就可以,然后点击确定就好了呀。
5:等都设置完成后,这时候就可以进行文件转换了,点击开始转换的按钮即可。
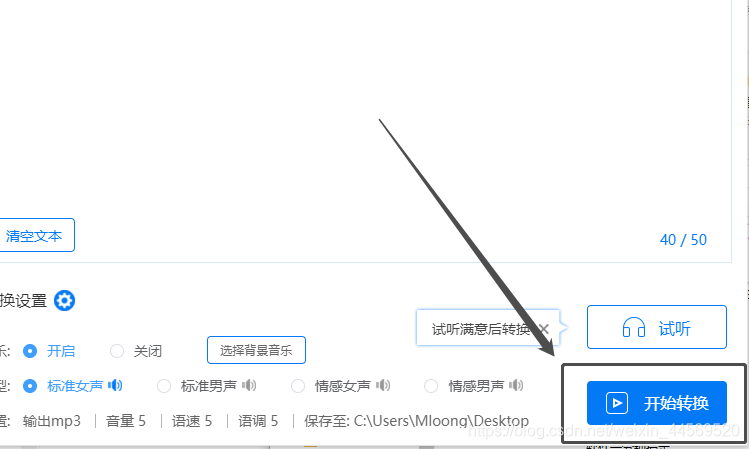
6:转换文件的过程只需要几秒钟就可以完成,等待转换完成,文件会保存到自己选择的位置中,我们也会在转换列表看到这份文件哦!

借助上面介绍的迅捷文字转语音软件,可以很轻松的实现文字转语音,如果下次你还需要将文字变成语音,试试这个方法吧;相信会帮到你的!
怎样能把文字变成语音
最新推荐文章于 2024-04-02 11:27:30 发布

















 1039
1039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









