



 本文详细介绍Maven项目结构、常用指令、环境配置、依赖管理、插件使用及子父工程概念,帮助开发者掌握Maven核心操作,提升项目管理效率。
本文详细介绍Maven项目结构、常用指令、环境配置、依赖管理、插件使用及子父工程概念,帮助开发者掌握Maven核心操作,提升项目管理效率。
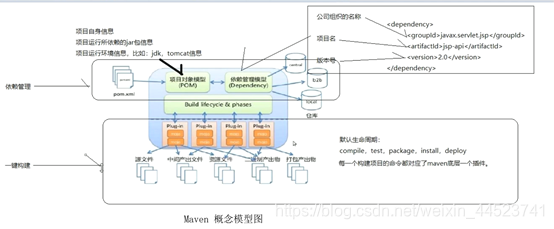
一、Maven项目结构图
项目结构

关系图
二、常用指令
![]() ①
①
![]() ②
②
![]() ③
③
![]() ④
④
查看Maven 版本号: mvn -v
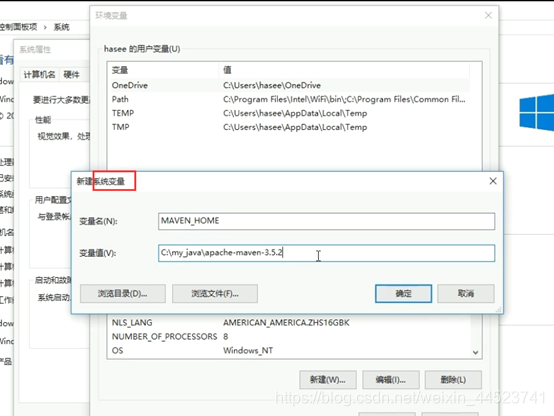
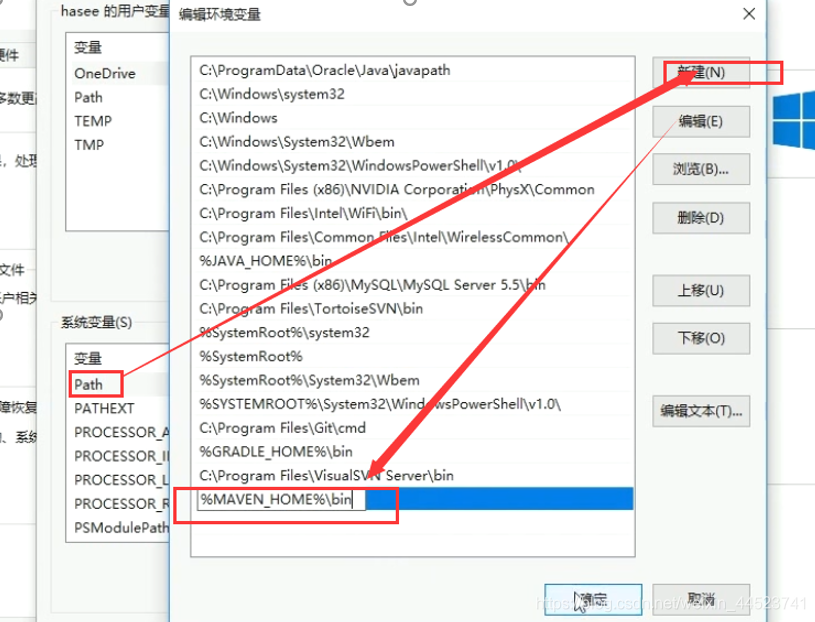
三、配置环境变量
四、修改本地lib地址
①在哪里改:
D:\Maven\apache-maven-3.5.2\conf\settings.xml②改什么

五、依赖管理系统
1、搜索坐标
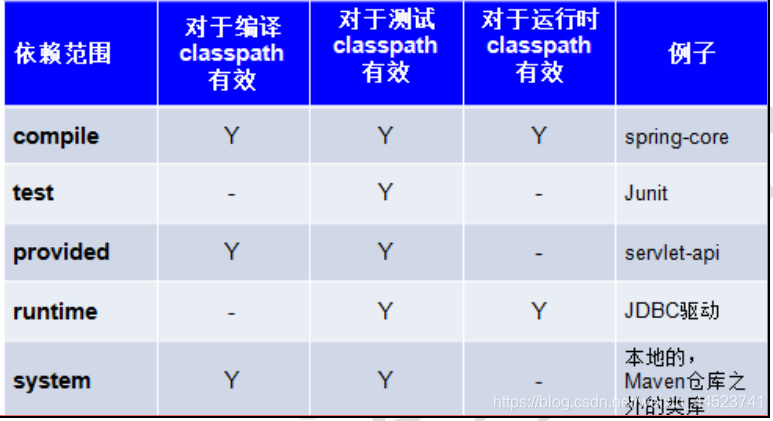
2、依赖范围
3、依赖传递
依赖中放入一个依赖 :写着其他依赖的组名 id
可能产生依赖冲突问题 就近原则 、先加载先生效原则
六、必备插件
在依赖<dependencies>外部添加 插件组:
<build>
<plugins>
。。。中间嵌套插件
</plugins>
</build>1、jdk
2、tomcat
1、jdk
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.7</source>
<target>1.7</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
2、tomcat
<plugin>
<groupId>org.apache.tomcat.maven</groupId>
<artifactId>tomcat7-maven-plugin</artifactId>
<configuration>
<port>8080</port>
<path>/</path>
</configuration>
</plugin>3、
七、子父工程
1、父工程:一般不写代码主要用来管理内部的子工程
<packaging>pom</packaging1
<modules>
<module>子工程id</module>
</modules>
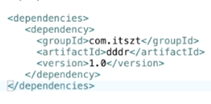
2、子工程:普通maven工程 指定父工程
<parent>
<artifactId>dddr4</artifactId>
<groupId>com.itszt</grgupId>
<version>1.0</version>
</parent>
3、父工程管理所有依赖
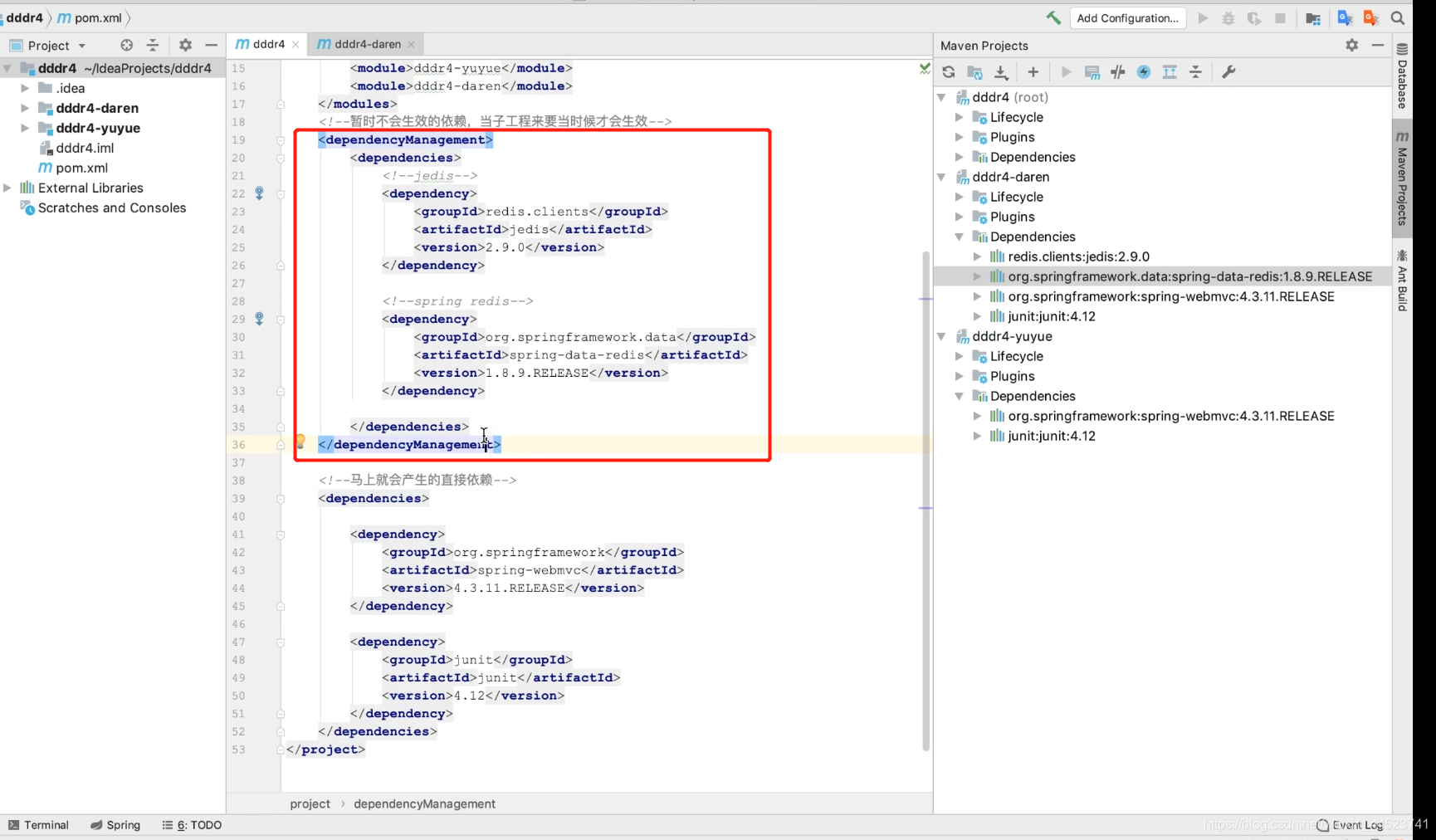
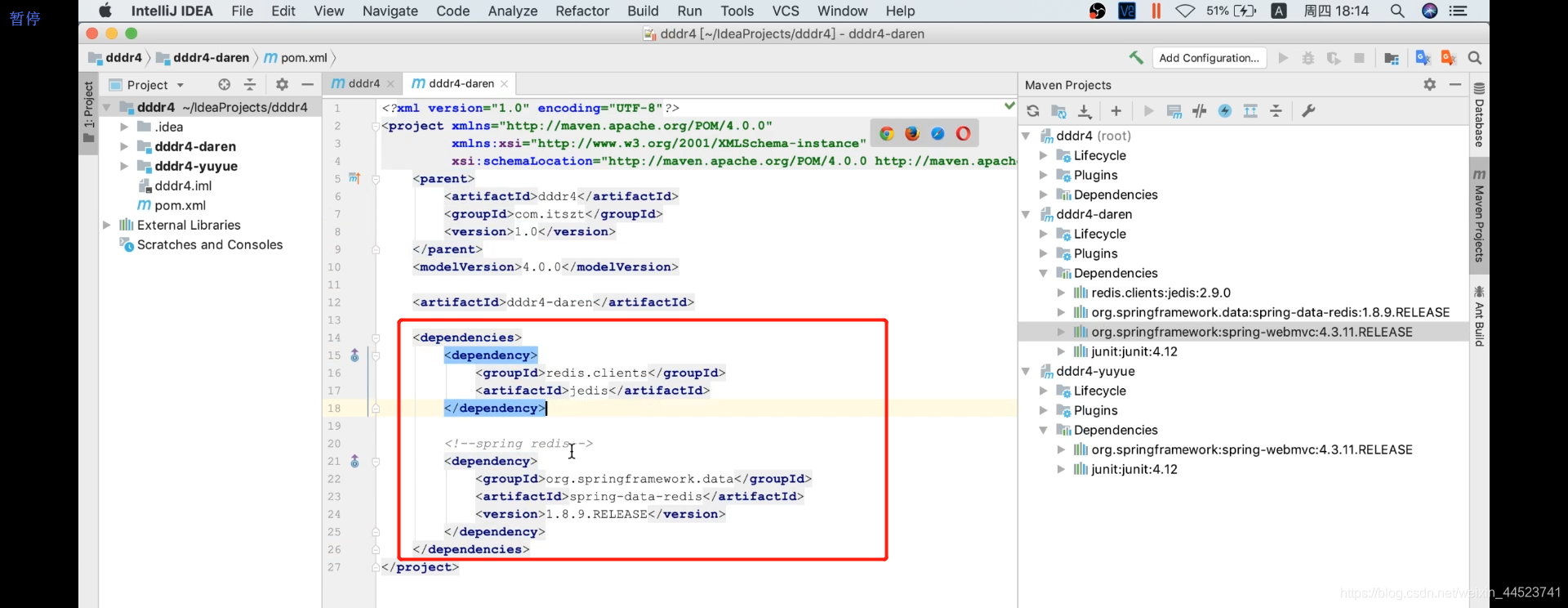
4、子工程再获取需要的依赖:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









