






这个文章是上班摸鱼的时候随便写的笔记,不成体系,仅供参考!
文章目录
SpaCy介绍
SpaCy是著名的NLP开源工具包,自带超过60种语言的预训练语言模型和词向量。SpaCy侧重NLP工业界应用,针对部署和计算速度进行了优化。
https://explosion.ai/demos/displacy 网站提供SpaCy的可视化,也可以用Python画Dependency Tree。
SpaCy文本处理流程示意图:
 SpaCy的结构图:
SpaCy的结构图:
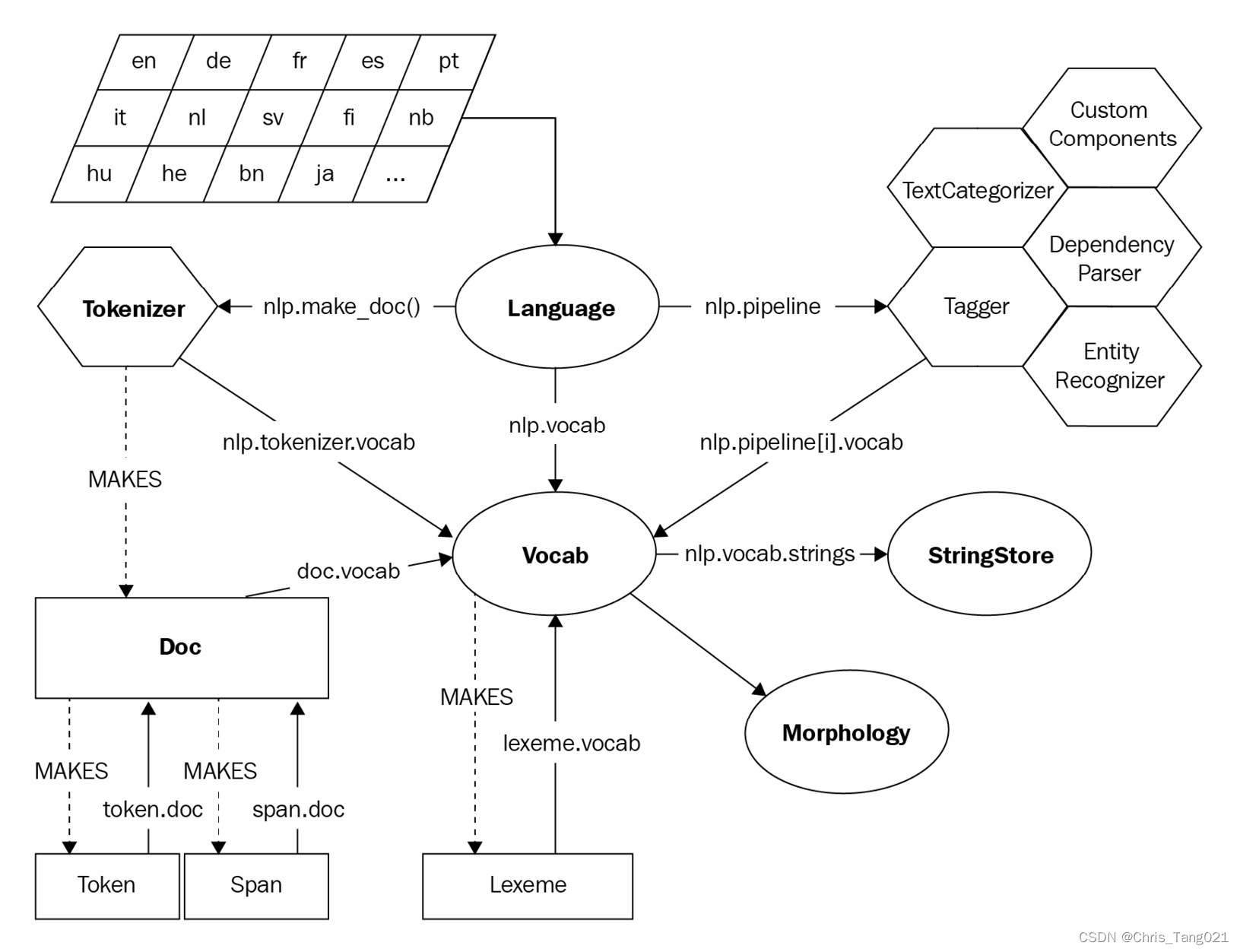
Python调用SpaCy的常见代码:
import spacy
nlp = spacy.load("en_core_web_md") # load the pipeline
doc = nlp("I went there")
# print the tokenization result
print ([token.text for token in doc])
上面的doc变量包含句子的标记、分词和实体等。
SpaCy还有配套的标注网站Prodigy
SpaCy工具库中的类别(Class)们
Doc类别代表文本,它包括该文本的分词、实体等信息。Token类别代表字。Span类别代表文本中连续的一部分。
基于规则的匹配
一些规则可以帮助匹配字符、提取信息,比如
- 正则表达式
在SpaCy中的代码实现:
import spacy
from spacy.matcher import Matcher
nlp = spacy.load("en_core_web_md")
doc = nlp("Good morning, I want to reserve a ticket.")
matcher = Matcher(nlp.vocab)
pattern = [{"LOWER": "good"}, {"LOWER": "morning"},
{"IS_PUNCT": True}]
matcher.add("morningGreeting", [pattern])
matches = matcher(doc)
for match_id, start, end in matches:
m_span = doc[start:end]
print(start, end, m_span.text)
# output: 0 3 Good morning,
SpaCy的PhraseMatcher可以用比较大的字典对文本进行匹配。
import spacy
from spacy.matcher import PhraseMatcher
nlp = spacy.load("en_core_web_md")
matcher = PhraseMatcher(nlp.vocab)
terms = ["Angela Merkel", "Donald Trump", "Alexis Tsipras"]
patterns = [nlp.make_doc(term) for term in terms]
matcher.add("politiciansList", patterns)
doc = nlp("3 EU leaders met in Berlin. German chancellor Angela Merkel first welcomed the US president Donald Trump. The following day Alexis Tsipras joined them in Brandenburg.")
matches = matcher(doc)
for mid, start, end in matches:
print(start, end, doc[start:end])
# output:
# 9 11 Angela Merkel
# 16 18 Donald Trump
# 22 24 Alexis Tsipras
实际例子:从文本中提取账户
doc = nlp("My IBAN number is BE71 0961 2345 6769, please send the money there.")
doc1 = nlp("My IBAN number is FR76 3000 6000 0112 3456 7890 189, please send the money there.")
pattern = [{"SHAPE": "XXdd"},
{"TEXT": {"REGEX": "\d{1,4}"}, "OP":"+"}]
matcher = Matcher(nlp.vocab)
matcher.add("ibanNum", [pattern])
for mid, start, end in matcher(doc):
print(start, end, doc[start:end])
for mid, start, end in matcher(doc1):
print(start, end, doc1[start:end])
电话号码同理,都是基于正则表达式提取信息。
基于规则的NER
SpaCy支持在NER的pipeline中融合预定义的词典和基于统计特征的模型。NER的规则分为:
- Phrase patterns
- Token patterns
这些规则都可以写成JSONL的形式储存起来。
官方文档认为在NER部分前加入EntityRuler可以更好地提高准确率。
当短语量超过一万个时,可以参考这部分文档
官方文档还给了几个例子:
- 如果需要提取人名的职称(xxx同志、xxx主席),比起重复训练整个模型,我们可以用
@Language.component("expand_person_entites")对预训练模型提取出的span做一些调整。https://spacy.io/usage/rule-based-matching#models-rules-ner
基于规则的Span提取
Span的定义
SpanRuler可以提高SpanCatgorizer和EntityRecognizer的准确率。
分词(Tokenization)
分词是第一步,也是重要的一步,因为后续的所有操作(实体命名等)都是基于分词的结果。
分词是把一个句子分成最小的语法单元。
SpaCy的分词不基于统计模型而是基于特定语言的语法规则。
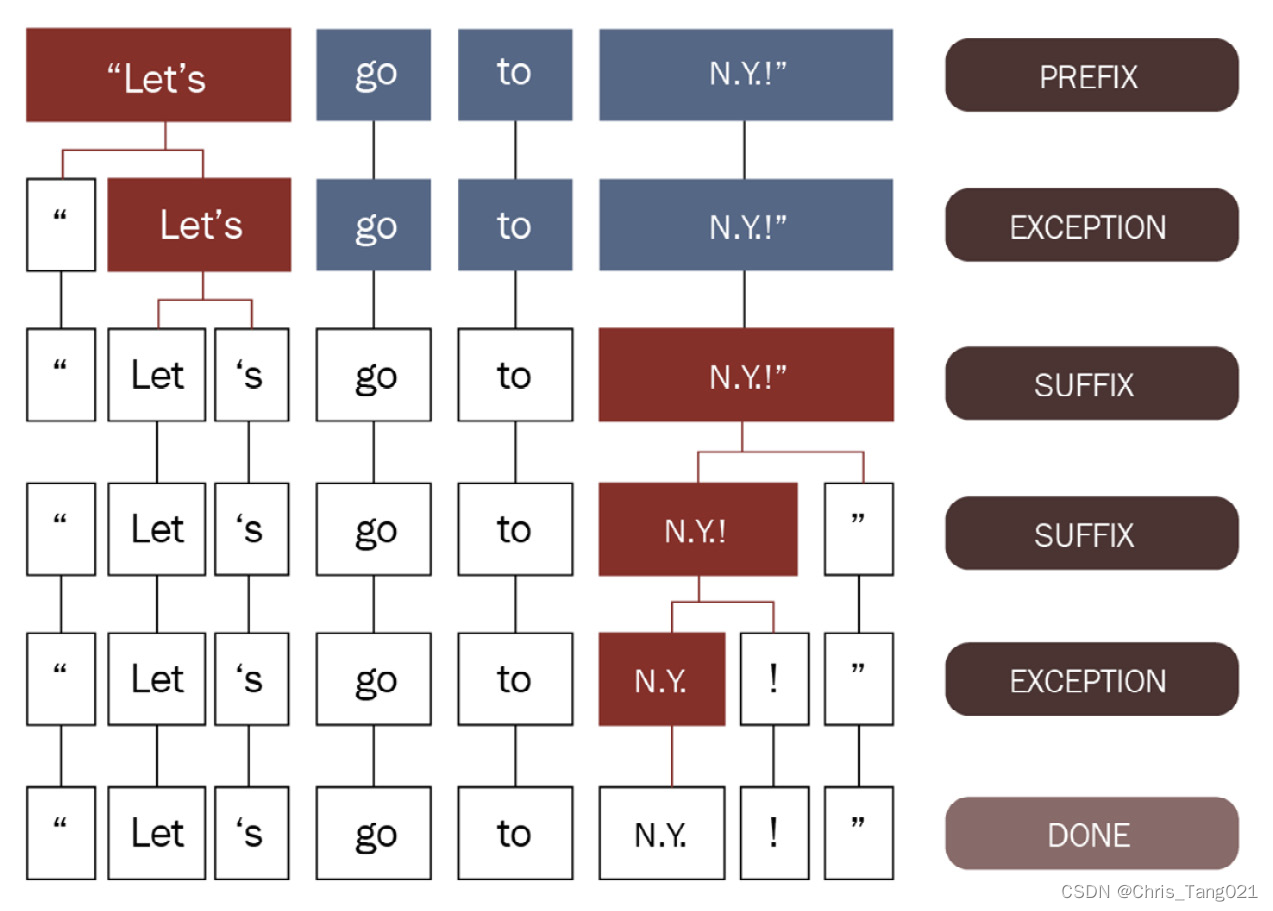
向SpaCy分词工具中添加新词
可以向SpaCy分词规则中添加专业词汇
doc = nlp("lemme that")
print([w.text for w in doc]) # ['lemme', 'that']
# now add special cases
special_case = [{ORTH: "lem"}, {ORTH: "me"}]
nlp.tokenizer.add_special_case("lemme", special_case)
print([w.text for w in nlp("lemme that")]) # ['lem', 'me', 'that']
自定义分词工具
def custom_tokenizer(text):
tokens = []
# your existing code to fill the list with tokens
......
# with this:
return Doc(nlp.vocab, tokens)
nlp.tokenizer = custom_tokenizer # 替换分词工具
上述的tokenizer是接收纯文本输出Doc对象的函数。
意图识别
动词是句子中重要的部分,及物动词会有影响的对象。对象又分为直接对象和简介对象,如下例:
He loved his cat. He loved who? - his cat (直接对象)
He gave me his book. He gave his book to whom? - me (间接对象)
这样的动词-对象组合可以帮助我们识别“意图”。Intent Recognition经常被用在对话机器人中。
SpaCy在进行依存语法解析后,我们可以识别出其中的动宾关系。【图】比如dobj就是直接宾语。
Find a flight from Washington to SF.
更复杂一些的句子拥有多个对象:
Show all flights and fares from Denver to SF.
这个时候flights 和 fares是conj关系:
import spacy
nlp = spacy.load("en_core_web_md")
doc = nlp("show all flights and fares from denver to san francisco")
for token in doc:
if token.dep_ == "dobj":
dobj = token.text
conj = [t.text for t in token.conjuncts]
verb = donj.head
print(verb, dobj, conj)
show flights ['fares']
再复杂一下,动词和对象可能没有直接的语法关联,比如
I want to make a reservation for a flight.
doc = nlp("i want to make a reservation for a flight")
dObj =None
tVerb = None
# Extract the direct object and its transitive verb
for token in doc:
If token.dep_ == "dobj":
dObj = token
tVerb = token.head
# Extract the helper verb
intentVerb = None
verbList = ["want", "like", "need", "order"]
if tVerb.text in verbList:
intentVerb = tVerb
else:
if tVerb.head.dep_ == "ROOT":
helperVerb = tVerb.head
# Extract the object of the intent
intentObj = None
objList = ["flight", "meal", "booking"]
if dObj.text in objList:
intentObj = dObj
else:
for child in dObj.children:
if child.dep_ == "prep":
intentObj = list(child.children)[0]
break
elif child.dep_ == "compound":
intentObj = child
break
print(intentVerb.text + intentObj.text.capitalize()) # wantFlight
SpaCy的词向量
训练词向量有很多算法和工具:
- word2vec
- Glove
- fastText
SpaCy提供一些预训练的词向量:
en_core_web_md有20000词的300维词向量en_core_web_gl有685000词的300维词向量
import spacy
nlp = spacy.load("en_core_web_md")
doc = nlp("I ate a banana.")
doc[3].vector
doc = nlp("You went there afskfsd.")
for token in doc:
token.is_oov, token.has_vector
# (False, True)
# (False, True)
# (False, True)
# (True, False)
# (False, True)
词向量要注意有没有OOV.
HashEmbedCNN
SpaCy标准的token2vec是基于MultiHashEmbd + MaxoutWindowEncoder.
MultiHashEmbd使用Hash Embedding, 可以表达token的一些lexical attribute比如NORM, PREFIX, SUFFIX 和 SHAPE. 通过多种属性,可以表达词的subword features.
想使用基于Transformer,可以使用zh_core_web_trf预训练模型。
自定定义SpaCy的Pipeline
- 准备标注数据
- 将标注数据处理成SpaCy定义的格式(JSONL等)
- 停用不需要更新的部分,只保留需要更新的部分
- 开始训练
other_pipes = [pipe for pipe in nlp.pipe_names if pipe != 'ner']
nlp.disable_pipes(*other_pipes)
...
for i in range(25):
random.shuffle(train_set)
for text, annotation in train_set:
doc = nlp.make_doc(text)
example = Example.from_dict(doc, annotation)
nlp.update([example], sgd=optimizer)
SpaCy的NER模型是一个神经网络的模型
参考资料:
- Duygu Altinok. (2021). Mastering spaCy. Packt Publishing.
- https://stackoverflow.com/a/53596275/11180198
- SpaCy官方文档

















 238
238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









