





DLFuzz: 深度学习系统的差分模糊测试
作者:
- Jianmin Guo
- Yu Jiang
- Yue Zhao
- Quan Chen
- Jiaguang Sun
摘要
深度学习(DL)系统越来越多地应用于安全关键领域,例如自动驾驶汽车。确保DL系统的可靠性和鲁棒性非常重要。现有的测试方法往往未能包含测试数据集中的稀有输入,且展现出低神经元覆盖率。
本文提出了DLFuzz,这是第一个引导DL系统暴露不正确行为的差分模糊测试框架。DLFuzz通过持续细微地突变输入,以最大化神经元覆盖率和原始输入与突变输入之间的预测差异,无需人工标注或引用具有相同功能的其他DL系统。我们在两个著名的数据集上进行了实验评估,以展示其效率。与最先进的DL白盒测试框架DeepXplore相比,DLFuzz无需额外寻找类似的DL系统进行交叉参考检查,但可以生成多338.59%的对抗输入,并且扰动减少了89.82%。平均神经元覆盖率提高了2.86%,同时节省了20.11%的时间开销。
引言
在过去的几年里,深度学习(DL)系统在广泛的应用中展示了其竞争力,如图像分类、自然语言处理,甚至是大脑回路重建。这些令人鼓舞的成果推动了DL系统在安全关键领域的广泛部署,如自动驾驶、无人机和机器人以及恶意软件检测,因此测试和提高DL系统的鲁棒性需求巨大。
对于DL测试,经典方法是收集足够的人工标注数据来评估DL系统的准确性。然而,测试输入空间过大,几乎不可能收集所有可能的输入来触发DL系统的每一个可行逻辑。研究表明,最先进的DL系统可以通过在测试输入上添加小的扰动来被欺骗。尽管DL系统在图像分类任务中表现出令人印象深刻的性能,但通过施加不可察觉的扰动,分类器仍然很容易被引导到错误的分类中。因此,DL测试非常具有挑战性,但对确保这些安全关键领域的正确性至关重要。
已有多种方法被提出以提高DL系统的测试效率。其中一些方法利用Z3等求解器,在DL模型的形式化约束下生成对抗输入。这些技术是准确的,但在白盒方式下非常重,且资源消耗较大。黑盒方法则利用启发式算法来突变输入,直到获得对抗输入。这些方法耗时且高度依赖于人工提供的真实标签。另一类对抗性深度学习方法通过对输入施加不可察觉的扰动来欺骗DL系统,虽然这些方法高效,但其神经元覆盖率较低。最近,DeepXplore被提出为最先进的白盒测试框架,它首次引入了神经元覆盖率作为测试指标。然而,DeepXplore需要多个功能相似的DL系统作为交叉参考,以避免人工检查。然而,交叉参考存在可扩展性问题,且难以找到类似的DL系统。
本文提出了DLFuzz,这是第一个差分模糊测试框架,旨在最大化神经元覆盖率,并为给定的DL系统生成更多的对抗输入,无需交叉引用其他相似的DL系统或人工标注。
首先,DLFuzz迭代选择值得激活的神经元,以覆盖更多逻辑,并通过施加细微的扰动突变测试输入,进而引导DL系统暴露不正确行为。在突变过程中,DLFuzz保留了那些在神经元覆盖率上有显著贡献的突变输入,用于后续的模糊测试。此外,细微的扰动是不可见的,确保原始输入和突变输入的预测结果相同。通过这种方式,DLFuzz能够获得稀有输入,并能够自动识别错误行为,当突变输入的预测结果与原始输入不同步时,即触发错误。
为了评估DLFuzz的效率,我们对六个DL系统进行了实验研究,这些系统训练于两个流行的数据集MNIST和ImageNet。与DeepXplore相比,DLFuzz不需要额外努力收集功能相似的DL系统进行交叉参考标签检查,但可以生成135%-584.62%的更多对抗输入,且扰动减少了79.56%-96.77%。此外,神经元覆盖率提高了1.10%-5.59%。在时间效率方面,DLFuzz平均节省了20.11%的时间开销,唯一的例外是在ImageNet上的一个案例,耗时比DeepXplore多59.42%。

动机
深度学习测试和传统软件测试之间存在巨大差距,这是由于深度神经网络(DNN)与软件程序的内部结构完全不同。研究人员已经做出了许多努力,尝试将软件测试应用于深度学习测试,包括白盒和黑盒两种方式。我们希望通过DLFuzz打破黑盒测试技术的资源消耗限制和白盒测试技术的交叉引用障碍,这是第一个利用不可察觉的扰动来确保输入与突变输入之间差异不可见的差分模糊测试框架。
模糊测试在软件测试中被认为是最有效的漏洞检测方法之一,展示了其捕获大量漏洞的能力。其核心思想是生成随机输入,以执行尽可能多的程序路径,进而使程序暴露出违反规定的行为或崩溃。模糊测试和DL测试的目标类似,都是为了实现更高的覆盖率以及获得更多异常行为。总体而言,我们将模糊测试中的关键阶段知识结合到DL测试中,具体如下:
- 优化目标:达到更高神经元覆盖率和暴露更多异常行为的目标可以视为一个联合优化问题。这个优化问题可以通过基于梯度的方法来实现。
- 种子维护:在模糊测试过程中,能够显著提高神经元覆盖率的突变输入被保留在种子列表中,以便在后续模糊测试中持续提高神经元覆盖率。
- 多样化的突变策略:我们设计了多种神经元选择策略,以选择那些可能覆盖更多逻辑并触发更多不正确输出的神经元。此外,已实践过多种测试输入的突变方法,并且这些方法易于集成。
3 DLFuzz方法
3.1 架构
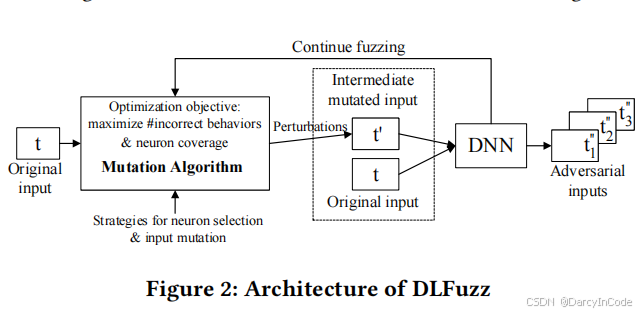
DLFuzz的整体架构如图2所示。本文中,我们实现了DLFuzz用于图像分类这一深度学习领域的流行任务,以展示其可行性和有效性。对于其他任务的适应性,如语音识别,其工作流程也是直接的,并遵循图2中的相同流程。
- 原始输入(t)是待分类的图像,DNN是一个正在测试的特定卷积神经网络(CNN),如VGG-16。
- 突变算法会对t应用微小的扰动,生成t’,其与t在视觉上无法区分。如果突变输入t’和原始输入t同时输入CNN,但被分类为不同的类别标签,我们将其视为不正确行为,并将t’作为一个对抗输入。
- 突变前后分类结果不一致,意味着至少有一个是错误的,因此不需要进行人工标注。相反,如果CNN对这两者的预测是相同类别标签,突变算法将继续突变t’,以测试CNN的鲁棒性。
3.2 算法
突变算法是DLFuzz的主要组件。它通过解决一个联合优化问题来完成,目标是最大化神经元覆盖率和错误行为的数量。基于更多的神经元覆盖可能触发更多逻辑和错误行为的证明,DLFuzz也采用与DeepXplore相同的神经元覆盖定义和计算方式。输出值大于设定阈值的神经元被视为已激活(已覆盖)。
突变算法的核心过程如算法1所示,包含三个关键组成部分:
算法1:突变算法

优化问题:DLFuzz通过自定义损失函数作为目标并通过梯度上升来最大化损失,其目标函数如算法1第9行所示,由两部分组成:
- 第一部分是原始类别标签与前k个类别标签之间的差异,最大化这部分引导输入越过原始类别的决策边界,进入其他类别的决策空间。
- 第二部分是目标神经元的激活,选择这些神经元是为了提高神经元覆盖率。
模糊测试过程:该过程揭示了算法1的整体工作流程。在给定测试输入x时,DLFuzz维护一个种子列表以保留那些有助于神经元覆盖的突变输入。DLFuzz通过迭代突变,不断生成新的对抗输入,并更新神经元覆盖率和L2距离。
- 突变过程中,DLFuzz使用多种处理方法生成扰动,并采用L2距离来衡量扰动的幅度,确保x与x’之间的距离不可察觉(小于0.02)。随着时间的推移,神经元覆盖率提升的门槛会逐渐降低。
神经元选择策略:为了最大化神经元覆盖率,DLFuzz提出了四种启发式策略来选择那些更有可能提高覆盖率的神经元:
- 策略1:选择过去测试中经常覆盖的神经元,类似于软件测试中经常或很少执行的代码片段更可能引入缺陷的经验。
- 策略2:选择过去测试中很少覆盖的神经元。
- 策略3:选择权重最大的神经元,假设这些神经元对其他神经元有更大的影响。
- 策略4:选择接近激活阈值的神经元,更容易通过微小变化激活/关闭这些神经元。
4 实验
4.1 实验设置
我们基于深度学习系统的常用框架(Tensorflow 1.2.1 和 Keras 2.1.3)实现了DLFuzz。Tensorflow和Keras提供了高效的梯度计算接口,并支持在每次预测后记录所有神经元的中间输出。我们在一台具有4核处理器(Intel i7-7700HQ @3.6GHz)、16GB内存、NVIDIA GTX 1070 GPU和Ubuntu 16.04.4操作系统的计算机上开发并评估了DLFuzz。
我们选择了两个数据集(MNIST和ImageNet)以及DeepXplore用于图像分类任务的对应卷积神经网络(CNN)来评估DLFuzz的性能。MNIST是一个包含60000张训练图像和10000张测试图像的大型手写数字数据库。ImageNet是一个包含超过1400万张用于物体识别的大型视觉数据库。与DeepXplore相同,DLFuzz在每个数据集上测试了三个预训练模型:MNIST上的LeNet-1、LeNet-4和LeNet-5,ImageNet上的VGG-16、VGG-19和ResNet50。为了确保公平性,我们也随机从每个数据集中选择了20张图像作为每个CNN的测试输入,与DeepXplore的选择方式相同。至于输入配置的超参数,我们尝试了许多可能的组合。如果没有特别说明,默认设置的超参数k、m、strategies和iter_times分别为4、10、“strategy 1”和3,这些参数在许多DNN上表现良好。
4.2 实验结果
表1展示了DLFuzz相对于DeepXplore的有效性。DLFuzz在提高神经元覆盖率、在相同时间内生成更多对抗输入并限制不可察觉的扰动方面表现出了优势。首先,如表的第三列所示,在测试的六个CNN中,DLFuzz平均比DeepXplore提高了1.10%到5.59%的神经元覆盖率。在最佳设置下,DLFuzz能够获得13.42%更高的神经元覆盖率。
表1:DLFuzz与DeepXplore的有效性比较
| 数据集 | 模型(#神经元) | NC 改进1 | L2 距离 | #对抗输入2 | 生成时间3 |
|---|---|---|---|---|---|
| MNIST | LeNet-1 (52) | 2.45% | 8.2637/0.2708 | 20/53 | 0.7078/0.5623 |
| MNIST | LeNet-4 (148) | 5.59% | 8.2637/0.2812 | 20/47 | 0.7078/0.6344 |
| MNIST | LeNet-5 (268) | 2.23% | 8.2637/0.2670 | 20/54 | 0.7078/0.5870 |
| ImageNet | VGG16 (14888) | 3.52% | 0.0817/0.0167 | 13/89 | 10.473/3.4537 |
| ImageNet | VGG19 (16168) | 2.28% | 0.0817/0.0154 | 13/81 | 10.473/3.6606 |
| ImageNet | ResNet50 (94056) | 1.10% | 0.0817/0.0097 | 13/72 | 10.473/16.6958 |
备注:表中的内容以a/b形式表示,其中a表示DeepXplore的结果,b表示DLFuzz的结果。
1 平均神经元覆盖率改进。
2 生成的对抗输入数量。
3 生成每个对抗输入的平均时间。
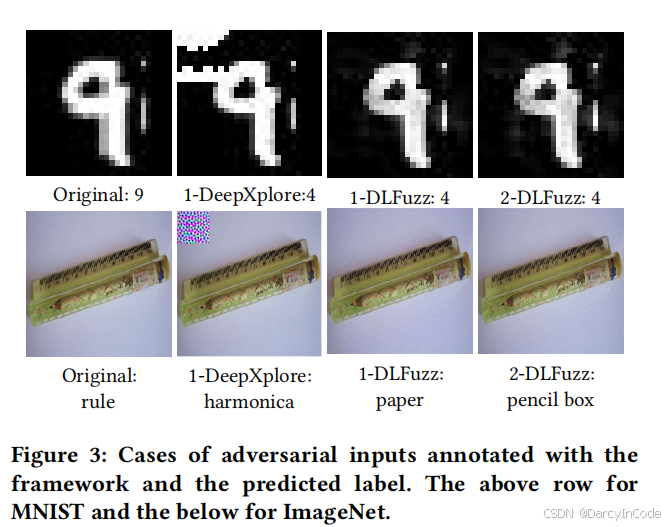
图3:注释了框架和预测标签的对抗输入案例。上方是MNIST,下面是ImageNet的结果。
接下来,由DLFuzz生成的对抗输入具有更小的扰动。如图3所示,DeepXplore生成的扰动是可见的,而DLFuzz生成的扰动是不可见且无法察觉的。通过这种方式,DLFuzz在突变前后提供了更强的图像身份一致性保证。正如表1的第四和第五列所示,DLFuzz平均生成了338.59%更多的对抗输入,且扰动减少了89.82%。此外,DLFuzz在这些DL系统上生成每个对抗输入的时间平均缩短了20.11%。一个例外是,对于ResNet50,DLFuzz生成对抗输入所需时间比DeepXplore更长,这是因为在测试具有大量神经元(94056)的DL系统时,神经元选择所需时间更长。
我们还在两个CNN上尝试了所有提出的神经元选择策略,并在图4中描绘了结果。所有策略都显示出比DeepXplore更有助于提高神经元覆盖率,并且它们之间的性能相似。看起来“策略1”表现略好一些。此外,为了证明DLFuzz的实际应用性,我们将114个对抗图像纳入到三个MNIST CNN的训练集中,并重新训练它们,看看是否能够提高其准确性。最终,我们在5个训练周期内将准确性提高了最多1.8%。如果在重新训练过程中包含更多的对抗输入,预计会有更多的提升。
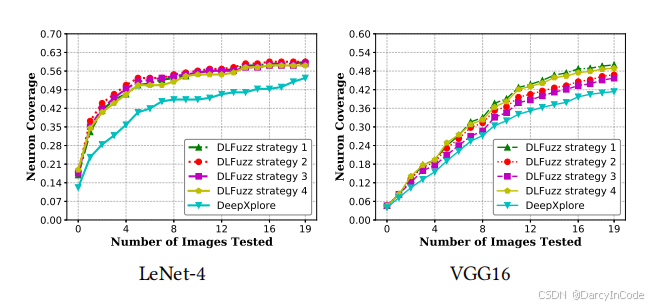
图4:当在DLFuzz中应用不同策略时,随着测试图片数量的增加,神经元覆盖率的变化。
4.3 讨论
模糊测试应用于DL测试的适用性:DLFuzz的有效性表明,将模糊测试的知识应用于DL测试是可行的,并且可以大大提高现有DL测试技术(如DeepXplore)的性能。优化问题的基于梯度的解决方案确保了框架的易部署性和高效性。种子维护机制提供了多样化的方向和更大的空间来提高神经元覆盖率。如图3所示,DLFuzz还能够为一个输入获得增量的对抗输入。结合神经元选择的各种策略证明了它们在找到有助于提高神经元覆盖率的神经元方面表现良好。
无需人工操作:为了确认,我们检查了DLFuzz生成的所有366个对抗输入,尽管DLFuzz通过设定的阈值保持了非常小的L2距离。我们没有发现任何在突变后已经改变其身份的对抗输入。这些对抗输入与原始输入几乎完全相同,并且扰动是不可察觉的。
未来工作:受DLFuzz在图像分类任务中令人印象深刻的效果的鼓舞,我们将继续研究DLFuzz在深度学习领域其他流行任务(如语音识别)中的应用。将针对相应任务的输入突变的特定约束添加到通用工作流程中。此外,一些领域知识可以被利用来提供更高效的突变操作并提高DLFuzz的效率。
5 结论
我们设计并实现了DLFuzz,作为一个深度学习系统的有效模糊测试框架。DLFuzz首次将模糊测试的基本思想与DL测试结合起来,并展示了其效率。与DeepXplore相比,DLFuzz在相同数量的输入下平均获得了2.86%更高的神经元覆盖率,并生成了338.59%更多的对抗样本,同时扰动减少了89.82%。DLFuzz还克服了DeepXplore依赖多个具有类似功能的DL系统的问题。此外,DLFuzz通过将这些对抗输入纳入重新训练中,展示了其实用性,并稳步提高了DL系统的准确性。首批结果展示了DLFuzz在早期暴露DL系统错误行为并确保其可靠性和鲁棒性的潜在应用。
神经元覆盖策略效果:图4展示了不同策略在DLFuzz中的神经元覆盖率,所有策略都比DeepXplore表现更好,策略1表现略优。


















 9554
9554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









