







 本文详细解析了K-means聚类算法的实现过程,通过Python和sklearn库进行数据加载、模型训练及预测,展示了如何寻找数据集的中心点,并对数据进行聚类分析。
本文详细解析了K-means聚类算法的实现过程,通过Python和sklearn库进行数据加载、模型训练及预测,展示了如何寻找数据集的中心点,并对数据进行聚类分析。
#!/usr/bin/env Python3
-- coding: utf-8 --
@Software: PyCharm
@virtualenv:ai
@contact: 1040691703@qq.com
@Desc:对K-means.py 文件的解析
author = ‘未昔/AngelFate’
date = ‘2019/8/15 20:10’
import numpy as np
def kmeans_():
“”"
聚类,找出原始数据集的中心点
:return:
“”"
from sklearn.cluster import KMeans
X = np.loadtxt(‘test.txt’, dtype=float, delimiter=’,’)
kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
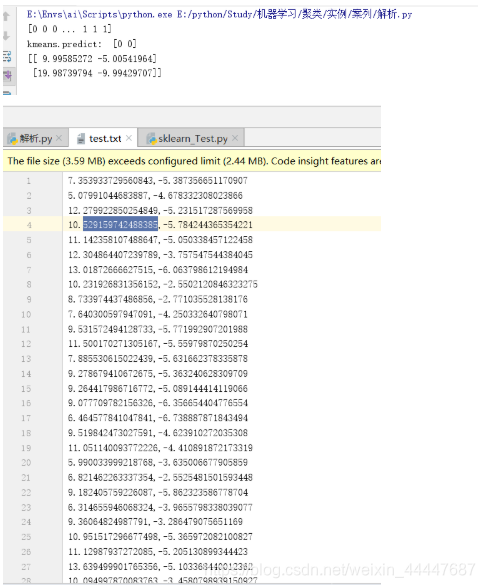
print(kmeans.labels_)
print('kmeans.predict: ',kmeans.predict([[0, 0], [12, 3]]))
#这个聚类中心点的值,和生成时用的正态分布的mean很接近.
print(kmeans.cluster_centers_)
if name == ‘main’:
 kmeans_()
kmeans_()


















 624
624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









