






👉 这是一个或许对你有用的社群
🐱 一对一交流/面试小册/简历优化/求职解惑,欢迎加入「芋道快速开发平台」知识星球。下面是星球提供的部分资料:
《项目实战(视频)》:从书中学,往事中“练”
《互联网高频面试题》:面朝简历学习,春暖花开
《架构 x 系统设计》:摧枯拉朽,掌控面试高频场景题
《精进 Java 学习指南》:系统学习,互联网主流技术栈
《必读 Java 源码专栏》:知其然,知其所以然
👉这是一个或许对你有用的开源项目
国产 Star 破 10w+ 的开源项目,前端包括管理后台 + 微信小程序,后端支持单体和微服务架构。
功能涵盖 RBAC 权限、SaaS 多租户、数据权限、商城、支付、工作流、大屏报表、微信公众号、ERP、CRM、AI 大模型等等功能:
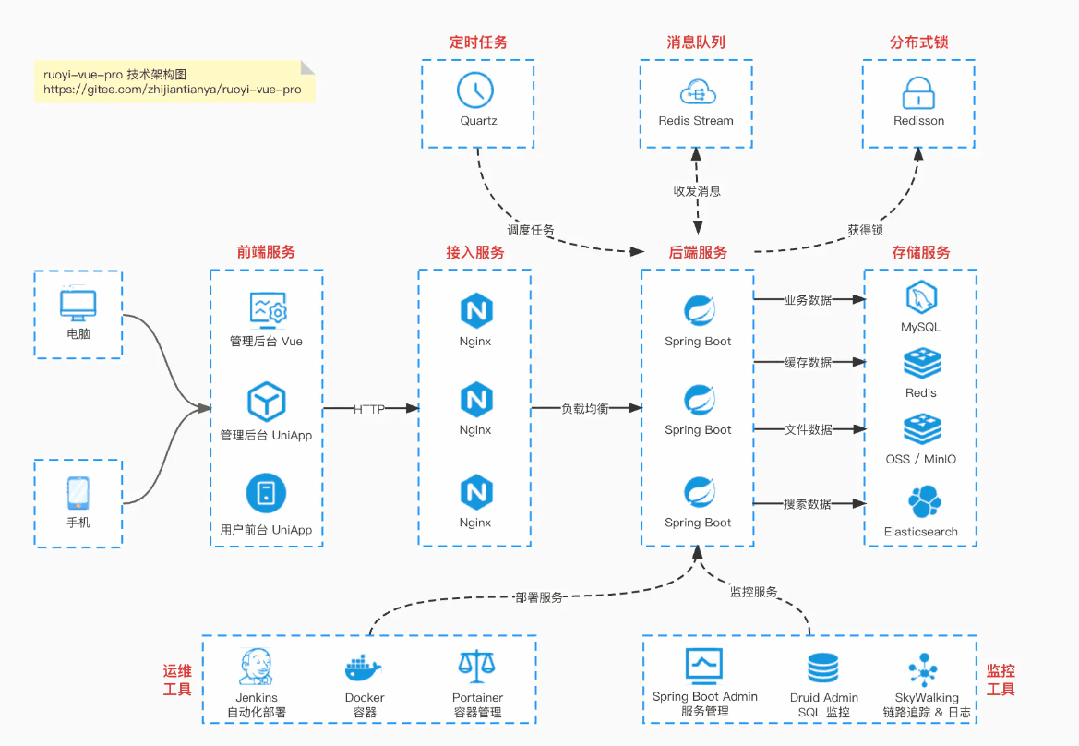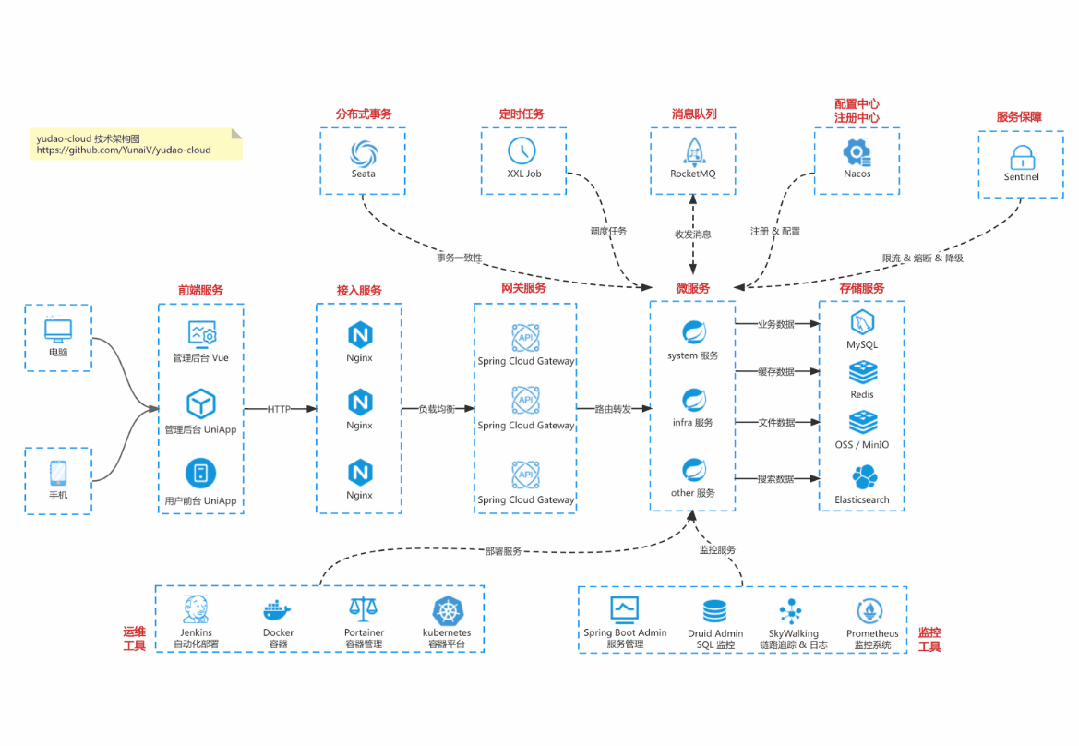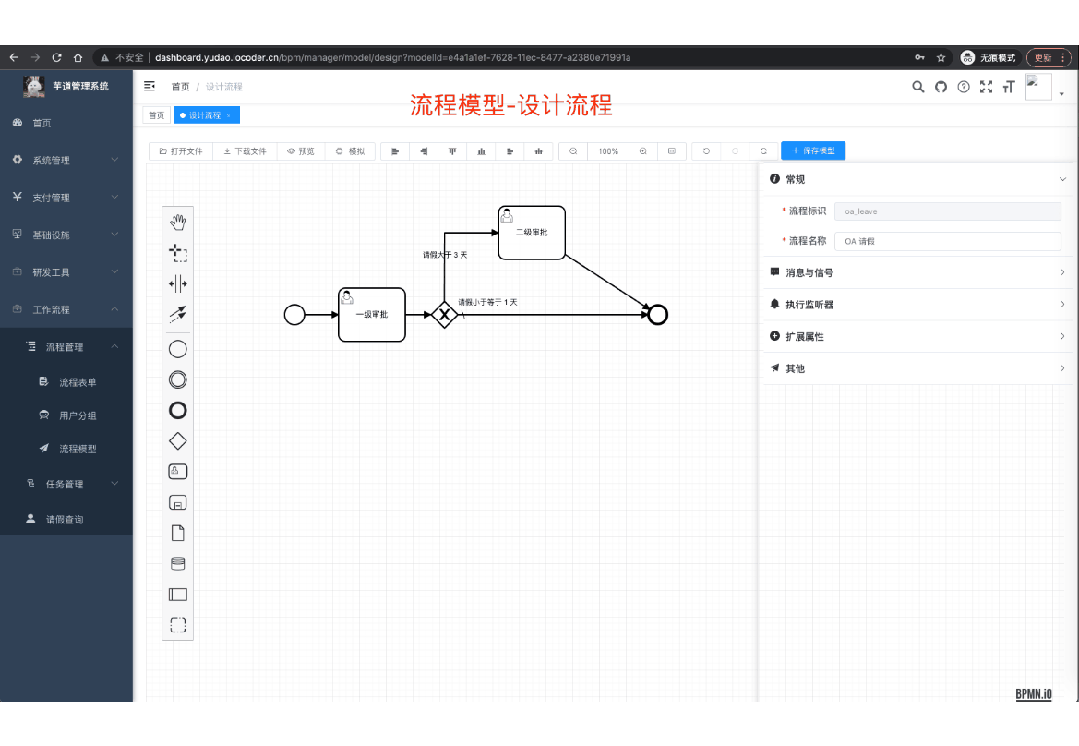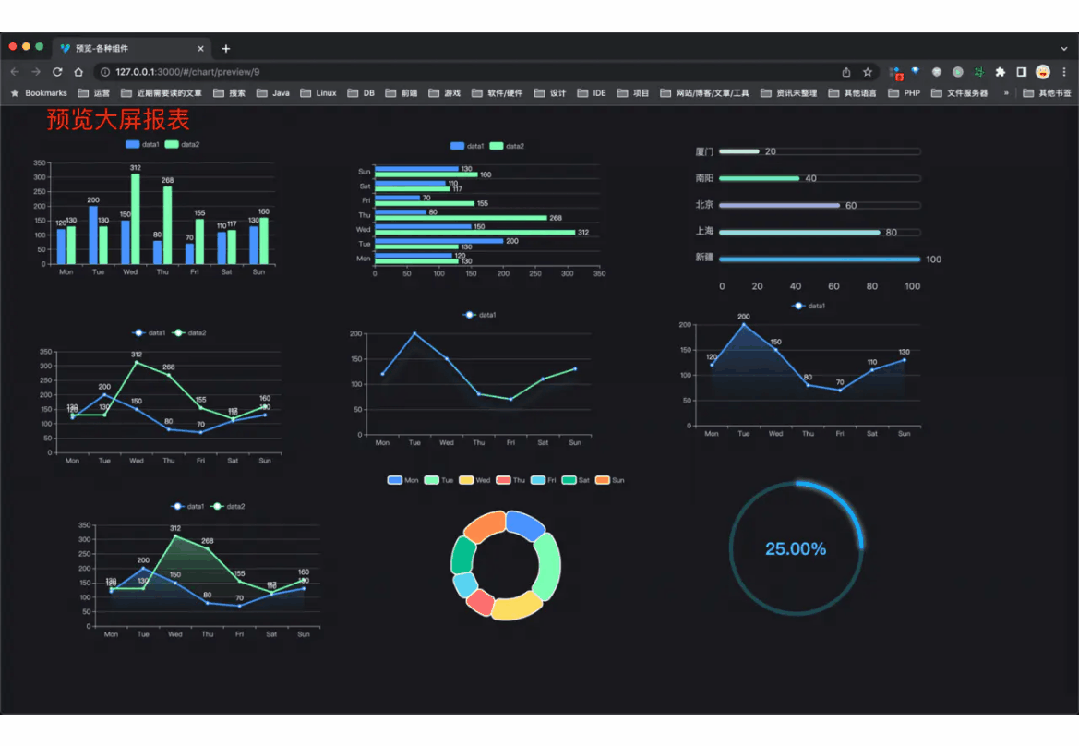
Boot 多模块架构:https://gitee.com/zhijiantianya/ruoyi-vue-pro
Cloud 微服务架构:https://gitee.com/zhijiantianya/yudao-cloud
视频教程:https://doc.iocoder.cn
【国内首批】支持 JDK 17/21 + SpringBoot 3.3、JDK 8/11 + Spring Boot 2.7 双版本
来源:juejin.cn/post/
7416902555187216435
相信很多小伙伴都知道 Redis 要尽量避免 大key 的读写, 网上也有很多文章在介绍如何拆分、如何解决大key问题,但如何找到大key这一问题很多文章都没有涉及。
在这篇文章里我将介绍一种完全无侵入(不改一行代码),轻量级但可以做到毫秒级实时发现大key的方案,你感兴趣吗?一起来看看吧!
背景
为什么要治理Redis大key?
频繁读写大key导致网络流量打满,影响其他正常请求!
频繁读大key导致客户端响应缓冲区积压占用Redis内存,达到
maxmemory阈值导致key被驱逐!导致
Redis Master阻塞不可用,引发意外的主从切换!处理解析大key导致客户端变慢!
传统发现Redis大key的方案有哪些?
了解了那么多大key产生的危害,可见大key必须消除,但如何做到呢?
以我们公司举例,之前我们通过每天凌晨定时给 Redis 做 RDB 快照分析找大key,但是这种方案存在很多问题,比如:
每天只统计一次,实时性较差。
会漏掉过期时间很短暂的 key。
结论:定时做RDB分析不是实时的,这种方案完全无法预防突发的大key查询!
那么该如何实时统计大key呢?以下是我列举的几个方案,都存在一些问题:

那么有没有一个轻量级、开发成本较低且能实时发现Redis大key的方案呢?
当然是有的,接下来我将会介绍一种不需要修改客户端、服务端一行代码,同样实现大key实时发现功能的方案!
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/ruoyi-vue-pro
视频教程:https://doc.iocoder.cn/video/
不改一行代码的实现方案
本文代码都在这里了哦👉仓库地址:
https://github.com/hengyoush/redis-bigkey-detector
运行时采集-eBPF和uprobe介绍

那么有没有一种不需要修改客户端和服务端代码,而且实现更加轻量级的方案呢?
当然有,那就不得不说下当下非常火的 eBPF 技术!
eBPF(Extended Berkeley Packet Filter)可以简单理解为在Linux内核中动态插入“钩子”( hooks )的技术,无需修改内核代码或重启系统。
这些钩子可以捕获内核级别的数据,包括网络、文件系统、内存管理等关键事件。而对于 Redis 这种用户态程序,eBPF 同样提供了 uprobe 类型的程序,可以插入钩子到 Redis 内部,而不需要修改 Redis 本身的代码。
详细的eBPF入门介绍,戳这里:
https://ebpf.io/what-is-ebpf/
下面我们来看看一般 eBPF 程序的大体结构是什么样的,让你有一个初步的认识!
程序结构
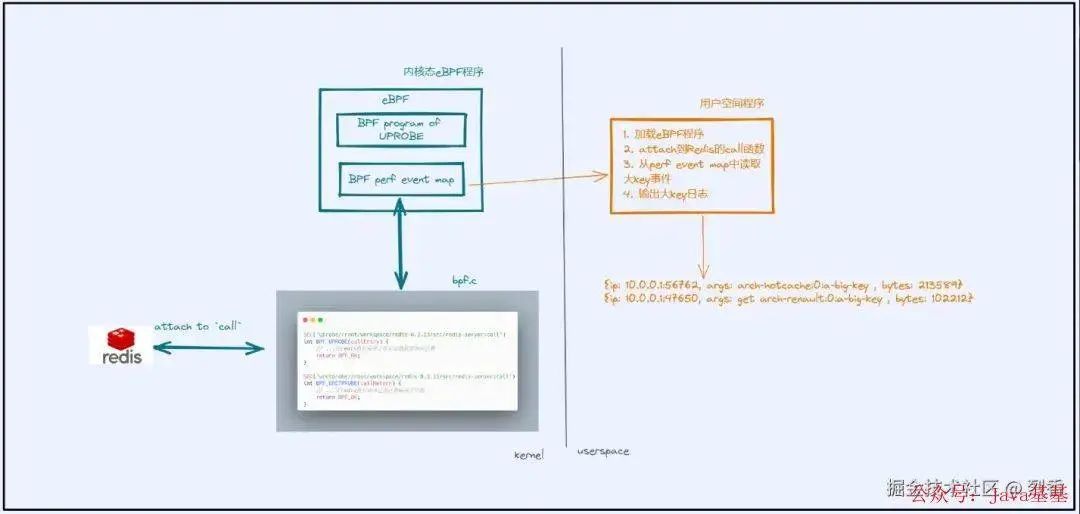
如上图所示,一个完整的 eBPF 程序可以分为两部分:内核部分和用户空间部分。
内核部分,负责收集数据上报给 用户空间部分 处理,eBPF Map 则作为 用户空间 和 内核空间 以及 不同 eBPF 程序之间数据交换的桥梁。
用户空间部分,则会将内核部分 attach 到对应的 hook 点 上(这个 hook 点可以是一个内核函数,也可以是一个网卡,取决于 eBPF 的程序类型是什么),然后进一步处理内核部分上报的数据。
内核部分
这篇文章中我们的内核部分的 eBPF 程序类型是 uprobe,会 attach 到 Redis 的内部函数里,它主要做两件事:
获取 Redis 执行命令的关键信息,包括:响应字节数、客户端ip、执行的命令等
判断响应字节数超过阈值后,说明发现了大key,将上述信息上报给用户空间部分进一步处理。
用户空间部分
用户空间部分主要负责加载 eBPF 程序到内核,然后读取从内核部分上报的大key信息,并且输出,这里我们简单输出到控制台。
获取三个关键信息!
如果要定位 大key 以及其产生的来源,至少需要知道哪些信息呢?
参考 Redis 慢日志,至少需要:客户端IP、命令参数、响应字节数 这三个信息:
127.0.0.1:6379> slowlog get
1) 1) (integer) 15
2) (integer) 1692413841
3) (integer) 90
4) 1) "CONFIG"
2) "SET"
3) "slowlog-log-filter"
4) "hmset hscan"
5) "172.17.0.1:51416"
6) ""
...
5) 1) (integer) 11
2) (integer) 1692412458
3) (integer) 7
4) 1) "slowlog"
2) "reset"
5) "172.17.0.1:51416"
6) ""确定了要采集的目标,接下来是写eBPF程序最关键的步骤: 确定采集位置
获取客户端IP
在 Redis 源码里探索,对于获取客户端信息和命令参数,我找到了一个非常合适的地方:call 函数:
void call(client *c, int flags) {
// ...
c->cmd->proc(c); // 这里是 Redis 执行各种命令的地方
// ...
}call 函数会在执行客户端命令的时候必定调用一次。
它有两个参数,其中第一个参数是 *client,client 结构体在Redis中代表一个客户端,而且 client 中就包含connection结构体,一个 connection 就代表和客户端的连接,可以获取和客户端连接的 socket fd:
struct connection {
// ...
int fd;
// ...
};我们在eBPF程序中很难从connection里直接获取 ip 字符串,只能获取 socket fd,但有了 socket fd,也能够获取到 ip,具体做法:
通过 PID 和 FD 获取 socket 的 inode(即 socketID)
读取
/proc/net/tcp文件,查找与socketID对应的 TCP 连接。匹配到后,解析 IP 和端口信息。
获取 命令参数
如何获取命令参数呢?实际上 client 结构体中也包含有参数相关信息:
typedef struct client {
int argc; /* Num of arguments of current command. */
robj **argv; /* Arguments of current command. */
} client;argc 是参数的数量,比如执行 get a命令,argc 就是 2,argv 则是具体的参数数组,每个参数用一个 *robj 表示,其底层使用 Redis 的 SDS 存储参数的字符串。
获取响应字节数
到这里我们又解决了如何获取参数的问题。
还有最后一个问题也是最关键的获取响应字节数量没有解决,这里也是比较难的一部分,我们首先要了解 Redis 是如何返回响应给客户端的。
Redis会将写入客户端的响应保存两个位置里:
一个是固定16K大小的字节数组中-即下面的 buf 字段。
一个链表,每个链表的元素代表一个字节数组,即 reply 字段。
typedef struct client {
list *reply; /* 字节数组链表(动态) */
int bufpos;
char *buf; /* 字节数组(静态) */
} client;Redis 写入响应时,首先写入到静态字节数组 buf 中,如果可用空间不足,再写入到字节数组链表中。
这里以 Get 命令为例:
int getGenericCommand(client *c) {
robj *o;
if ((o = lookupKeyReadOrReply(c,c->argv[1],shared.null[c->resp])) == NULL) // 查找key是否存在,如果不存在直接返回NULL
return C_OK;
if (checkType(c,o,OBJ_STRING)) {
return C_ERR;
}
addReplyBulk(c,o); // 如果找到了key在这里返回
return C_OK;
}lookupKeyReadOrReply: 首先根据 key 查找,如果不存在直接在这个函数里返回NULL
checkType: 如果找到了判断 Key 类型是否是 string
addReplyBulk: 真正返回响应。
接着看 addReplyBulk:
void addReplyBulk(client *c, robj *obj) {
addReplyBulkLen(c,obj);
addReply(c,obj);
addReplyProto(c,"\r\n",2);
}按照 Redis 的 Resp 协议,这里的三个_addReply* 函数作用分别是:写入返回响应的len、value和最后的\r\n(表示结束)。
如果再继续跟踪,最后它们都会调用到 _addReplyToBufferOrList 函数,
void _addReplyToBufferOrList(client *c, const char *s, size_t len) {
// ...
size_t reply_len = _addReplyToBuffer(c,s,len);
if (len > reply_len) _addReplyProtoToList(c,c->reply,s+reply_len,len-reply_len);
}可以看到这里确实是先将响应加入到静态的 buf,如果写不下了,再加入到动态的 reply 中。
💡:所以理论上我们可以在
_addReplyToBufferOrList采集,累加_addReplyToBufferOrList函数的 len 参数,就能得到一次命令返回给客户端的总字节大小。
初版实现
结合以上采集位置,我们可以总结出第一版实现方案:
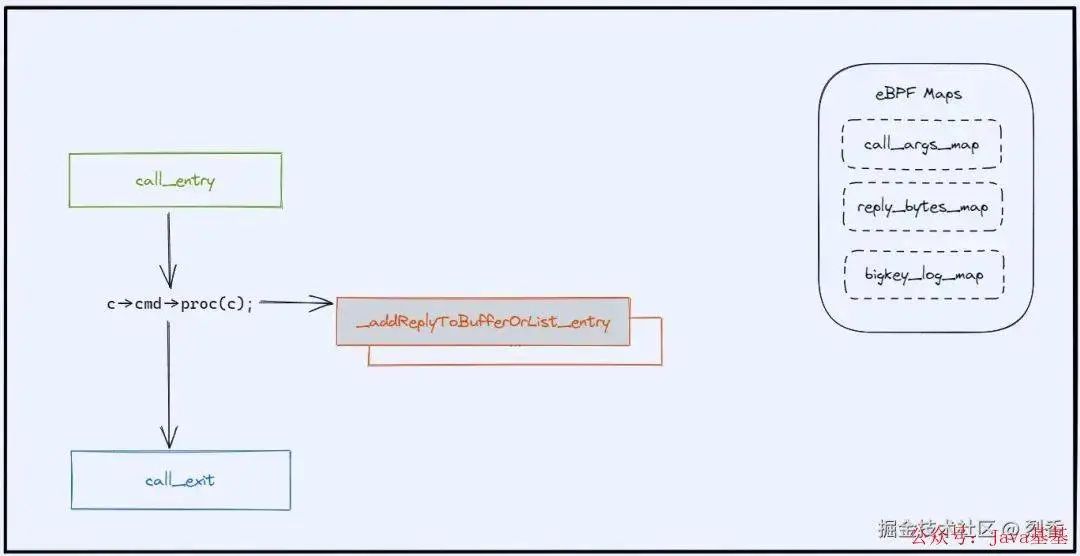
需要采集三个位置:
call_entry: 进入 call 函数的地方,程序类型为 uprobe,这里会将 call 函数的第一个参数 client 存储起来,传递给下面的 call_exit 使用。
_addReplyToBufferOrList_entry: 进入 _addReplyToBufferOrList 函数的地方,程序类型为 uprobe,用于累加计算响应字节数量。
call_exit: call 函数返回的地方,程序类型为 uretprobe,uretprobe 类型的程序无法拿到call 函数的参数,所以需要 call_entry 来辅助传递 client 参数。这里是我们主要的逻辑部分,主要包含两部分:
获取第二步计算的最终的响应字节大小。
如果超过了阈值,则从 client 参数中获取命令参数和客户端
socket fd,传递给用户空间程序告诉它我们找到了一次大key请求。
同时也使用到三个eBPF Map,下面分别介绍它们的作用:
call_args_map: 用于在 call_entry 中存储 call 函数的参数即 client。
reply_bytes_map: 用于在
_addReplyToBufferOrList_entry中累加字节数量。bigkey_log_map: 用于上报大key事件给用户空间。
代码实例
开始写代码吧!下面我截取一些关键的代码。
call_entry
作用:进入这里说明是一次新的 Redis 命令执行,所以首先清理 reply_bytes_map,重新开始计数,另外从参数中获取 client 存到 call_args_map 里传递给 call_exit。
SEC("uprobe//root/workspace/redis-6.2.13/src/redis-server:call")
int BPF_UPROBE(callEntry) {
u32 key = 0;
u64* reply_bytes = bpf_map_lookup_elem(&reply_bytes_map, &key);
bpf_map_delete_elem(&reply_bytes_map, &key); // 清理 `reply_bytes_map`,重新开始计数
struct client_t* client = PT_REGS_PARM1(ctx);
if (client) {
// 获取 `client` 存到 `call_args_map` 里传递给 `call_exit`
bpf_map_update_elem(&call_args_map, &key, &client, BPF_ANY);
}
return BPF_OK;
}_addReplyToBufferOrList_entry
作用:累加响应字节数。
具体实现:获取 _addReplyToBufferOrList 的第三个参数 len,并且从 reply_bytes_map 获取之前的累加值,将最终累加值更新到 reply_bytes_map 中。
SEC("uprobe//root/workspace/redis-6.2.13/src/redis-server:_addReplyToBufferOrList")
int BPF_UPROBE(_addReplyToBufferOrList_entry) {
size_t len = (size_t)PT_REGS_PARM3(ctx); // 获取第三个参数 len
u32 key = 0;
u64 sum = len;
u64* reply_bytes = bpf_map_lookup_elem(&reply_bytes_map, &key);
if (reply_bytes) {
sum += *reply_bytes; // 累加
}
bpf_map_update_elem(&reply_bytes_map, &key, &sum, BPF_ANY);
return BPF_OK;
}call_exit
这部分代码较长,让我来一一解释:
1、首先从 reply_bytes_map 拿到这次命令响应的总字节数,如果没有超过 BIGKEY_THRESHOLD_BYTES,说明不是大key,直接返回,否则继续下一步
2、从 call_args_map 中拿到在 call_entry 中暂存的 client, 然后:
从 client 获取
socket fd从 client 中获取命令参数
3、至此三个关键信息全部拿到,使用 bigkey_log_map 上报大key日志到用户空间。
SEC("uretprobe//root/workspace/redis-6.2.13/src/redis-server:call")
int BPF_URETPROBE(call_exit) {
u32 key = 0;
u64 *p_bytes = bpf_map_lookup_elem(&reply_bytes_map, &key);
u64 bytes = *p_bytes;
if (bytes > BIGKEY_THRESHOLD_BYTES) {
int err;
struct client_t** p_client = bpf_map_lookup_elem(&call_args_map, &key);
struct client_t* client = *p_client;
int zero = 0;
struct bigkey_log* evt = bpf_map_lookup_elem(&bigkey_log_stack_map, &zero);
evt->arg_len = 0;
evt->fd = 0;
// 1. 获取 client fd
u32 fd = 0;
get_client_fd(client, &fd);
evt->fd = fd;
// 2. 获取 cmd args
struct robj **argv = _U(client, original_argv) ? _U(client, original_argv) : _U(client, argv);
uint8_t argc = _U(client, original_argv) ? _U(client, original_argc) : _U(client, argc);
argc = argc > MAX_ARGS_LEN ? MAX_ARGS_LEN:argc;
for (uint8_t idx = 0; idx < argc; idx++) {
// 获取命令每一个参数,这一部分我省略了
}
// 输出最终的大key事件日志到用户空间
bpf_perf_event_output(ctx, &bigkey_log_map, BPF_F_CURRENT_CPU, evt, sizeof(struct bigkey_log));
}
return BPF_OK;
}用户空间程序
和内核态程序相比,用户空间可以选择的语言更加广泛了,这里我选择的是go,借助于github.com/cilium/ebpf这个库可以很方便的开发eBPF用户态程序。
用户空间程序就比较简单了(这里我只节选处理大key日志的部分),下面介绍下其大体流程:
在用户空间从 bigkey_log_map 读取的是字节数组,先将其转换为 golang 里的 BigkeyLog 结构体。
解析参数,将其转换为字符串并且用空格分隔。
根据 fd 和 redis 的 进程id 获取远程客户端IP。
输出结果到控制台。
func handleEvent(record []byte) error {
event := bpf.AgentBigkeyLog{}
err := binary.Read(bytes.NewBuffer(record), binary.LittleEndian, &event) // @1 转换为BigkeyLog结构体
if err != nil {
return err
}
entry := SlowLogEntry{}
entry.bytes = uint(event.BytesLen) // @2 解析参数
argsString := ""
for i := 0; i < int(event.ArgLen); i++ {
each := event.BigkeyArgs[i]
if each.Encoding == encoding_raw || each.Encoding == encoding_embstr {
argBytes := each.Arg0[0:each.Len]
argBytes = append(argBytes, 0)
argStr := Int8ToStr(argBytes)
argsString += argStr
argsString += " "
}
}
entry.ip = getRemoteIp(int(event.Fd))// @3 解析fd
entry.args = argsString
log.Printf("%s", entry.String()) // @4 输出结果
return nil
}效果展示!
代码写完了,接下来看看效果!
这里我修改了大key阈值(
BIGKEY_THRESHOLD_BYTES)为一个较小的值比如1024,这样方便我们后续的测试。
通过编译构建上面我们写的代码我们得到一个二进制文件:redis-bigkey,然后开始测试吧!
启动Redis服务端: 在一个 shell 启动 Redis服务端,获取其 pid,我测试的时候 pid 是 1940701
启动redis-bigkey: 打开另外一个 shell,启动 redis-bigkey:
root@VM-4-9-ubuntu:~/workspace/redis-bigkey# ./redis-bigkey 1940701
2024/09/21 11:31:09 Waiting for events...可以看到"Waiting for events..." 说明我们的 redis-bigkey 正在等待内核空间的事件到来。
启动Redis客户端: 再打开一个 shell,访问这个刚刚启动的 Redis,使用命令 COMMAND DOCS(这个命令返回的字节数较多),然后在 redis-bigkey 的 shell 里会打印:
2024/09/21 11:31:09 ip: 127.0.0.1:56762, args: COMMAND DOCS , bytes: 213589大功告成!我们成功的打印了 大key 的客户端、命令参数以及字节数大小!
这里的字节数量213589是不是准的呢?
你可以通过 tcpdump 验证,不过既然这篇文章的主题是 eBPF,可以使用 eBPF 相关工具来验证!😀
这里我使用 kyanos :一个基于 eBPF 的强大好用的网络问题诊断工具,使用它的 watch 命令可以观测各种协议的请求响应:
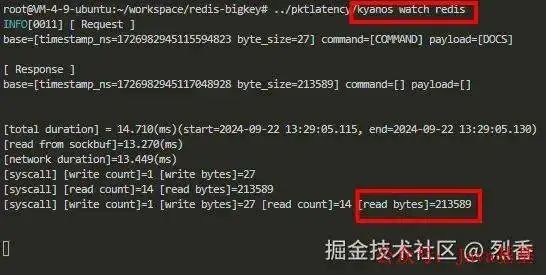
用kyanos可以看到响应字节确实是213589,没有问题!
性能问题?
功能上差不多了,再看看性能,我使用 redis-benchmark 来做一个简单的测试,使用命令:redis-benchmark -n 10000 hgetall myhash。
myhash 是一个预先设置好的 hash key,共100个 field。
首先在没有启动 redis-bigkey 的情况下测试
Summary:
throughput summary: 27322.40 requests per second
latency summary (msec):
avg min p50 p95 p99 max
1.027 0.624 0.999 1.215 1.575 4.399然后启动 redis-bigkey 再进行测试:
Summary:
throughput summary: 269.04 requests per second
latency summary (msec):
avg min p50 p95 p99 max
185.228 22.880 183.679 198.655 217.215 300.031令人惊讶😱!平均耗时达到了185ms,是原先的185倍!性能降级如此严重看来是没法用了...等等为什么会这么慢呢?
为什么会这么慢?
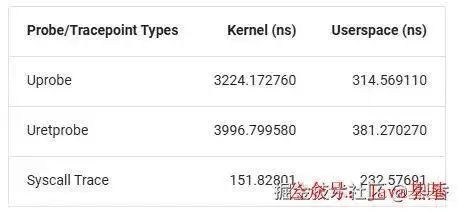
Uprobe 虽然是一种强大的用户级动态追踪机制,但这种技术的实现是通过在指定的位置设置断点,例如在 x86 架构上使用 int3 指令,当执行流到达这一点时,程序会陷入内核,触发一个事件,随后执行预定义的探针函数,完成后返回用户态继续执行。
但是,由于 eBPF 虚拟机在内核态执行,当前的 Uprobe 实现在内核中引入两次上下文切换,造成了显著的性能开销,特别是在延迟敏感的应用中这种开销会严重影响性能。和 Kprobe 相比,Uprobe 的开销接近十倍。
原来如此!原因在于 _addReplyToBufferOrList_entry 触发次数太多了,对于像这种100个 field 的 hash,可能要调用 _addReplyToBufferOrList 几百次,每次都会引发上下文切换,所以有没有办法优化呢?
第二版实现
如果我们观察_addReplyToBufferOrList 方法的内部,可以看到两种情况:
size_t _addReplyToBuffer(client *c, const char *s, size_t len) {
// ...
c->bufpos+=reply_len; // 写入到静态 buf 中,bufpos增加了
// ...
return reply_len;
}
void _addReplyProtoToList(client *c, list *reply_list, const char *s, size_t len) {
if (tail) {
tail->used += copy; // 最后一个list元素的used增加了
}
if (len) {
// 一个 list 元素,创建一个新节点在链表上
listAddNodeTail(reply_list, tail);
tail->used = len;
}
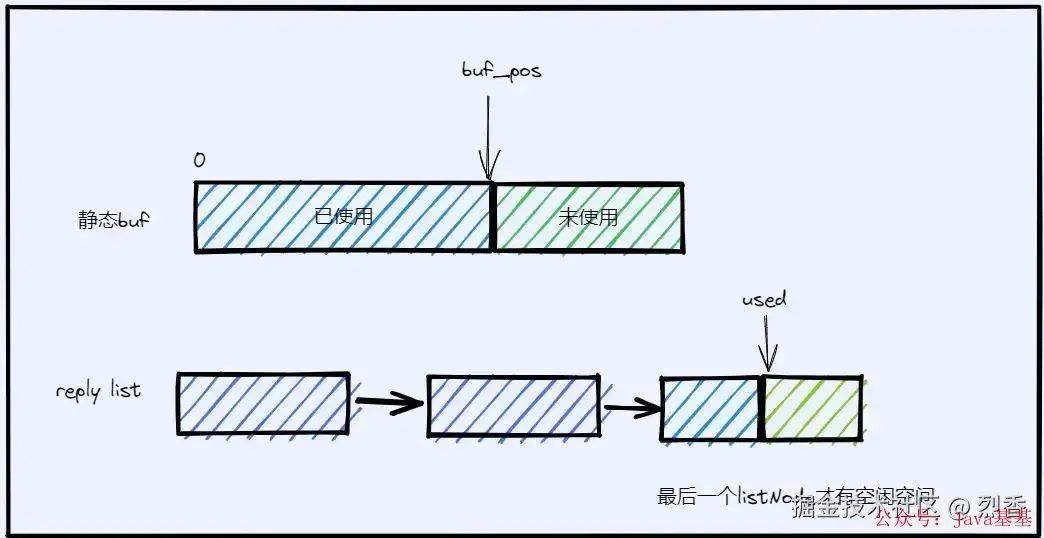
}写入到静态 buf 中,那么 buf_pos 会增加。
写入到动态的 reply list 中,那么 list 元素(每个 list 元素就是一个字节数组)内部的 used 会增加,如果一个 list 元素装不下,还会在 list 后面新增一个元素,这样 list 的长度会增加。
所以只需要在 call 函数执行前记录静态 buf 的 buf_pos,和 reply list 的长度以及最后一个元素内部的 used,然后和 call 函数结束的时候相减,就能得到响应的字节数!如下图所示:
代码实例
_addReplyToBufferOrList_entry
删掉!不需要 _addReplyToBufferOrList_entry 来累加字节数了!
call_entry
首先读取 buf_pos,然后获取当前 list 最后一个 node 的 index,和最后一个 node 内部的 used 变量。
static __always_inline void fillPosData(struct client_data_pos* arg, struct client_t* client) {
// 首先读取buf_pos
int bufpos = 0;
bpf_probe_read_user(&bufpos, sizeof(bufpos), (void*)client + BUFPOS_OFFSET);
arg->buf_bos = bufpos;
// 处理reply链表
struct list *reply;
bpf_probe_read_user(&reply, sizeof(reply), (void*)client + REPLY_OFFSET);
unsigned long listlen = _U(reply, len);
struct listNode *tail = _U(reply, tail);
void *lastValue = _U(tail, value);
int curListIndex, listOffset;
if (listlen && lastValue) {
struct clientReplyBlock* block = (struct clientReplyBlock*)lastValue;
// 获取最后一个node的index
curListIndex =listlen - 1;
// 获取最后一个node内部的used变量
listOffset = _U(block, used);
} else {
curListIndex = 0;
listOffset = 0;
}
arg->client = client;
arg->list_idx = curListIndex;
arg->list_offset = listOffset;
}call_exit
在 call_exit 中,获取当前的 buf_pos 等上述参数,然后遍历 reply_list,将动态 list 中缓冲区大小加起来,就是最终的响应字节数。
int BPF_URETPROBE(call_exit) {
// ...
fillPosData(&after, client);
listIter iter;
listNode *curr;
clientReplyBlock *o;
struct list *reply;
bpf_probe_read_user(&reply, sizeof(reply), (void*)client + REPLY_OFFSET);
listRewind(reply, &iter);
for (;loops <= 65 && (curr = listNext(&iter)) != NULL; loops++) {
size_t written;
o = _U(curr, value);
size_t used = _U(o,used);
if (i == arg->list_idx) {
written = used - arg->list_offset;
} else {
written =used;
}
bytes += written;
i++;
}
// ...
}后面的代码和第一版相同,都是从 client 中获取客户端 fd 和命令参数等,就不重复了。
性能比较
优化前
Summary:
throughput summary: 269.04 requests per second
latency summary (msec):
avg min p50 p95 p99 max
185.228 22.880 183.679 198.655 217.215 300.031优化后
Summary:
throughput summary: 23255.81 requests per second
latency summary (msec):
avg min p50 p95 p99 max
1.765 0.760 1.727 2.543 2.759 5.415优化效果
优化之后和优化前相比平均耗时从 185ms => 1.765ms,减少了 99%!
P99 线从 217.215ms => 2.759ms,减少了 98.8%!
和基线相比仍然有一定差距,该如何优化呢?
参考 bpftime 项目:
https://eunomia.dev/zh/bpftime/
它可以在在用户态运行 uprobe 程序而不需要上下文切换,性能和内核态的 uprobe相比提高了10倍!
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/yudao-cloud
视频教程:https://doc.iocoder.cn/video/
结语
这篇文章中我们讨论了如何使用 eBPF 实现 Redis 大key实时发现的方法,可以看到 eBPF 还是一个非常强大的工具👍, 而我们今天展示的 uprobe 用法只是其中的冰山一角,大家如果感兴趣可以到eBPF - https://ebpf.io/官网上查看自己感兴趣的项目。
欢迎加入我的知识星球,全面提升技术能力。
👉 加入方式,“长按”或“扫描”下方二维码噢:

星球的内容包括:项目实战、面试招聘、源码解析、学习路线。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









