




 本文介绍了一个使用Python编写的贴吧爬虫程序,用户可以输入贴吧名、起始页和结束页,程序将在当前目录下创建相应的文件夹,并下载指定范围内的所有页面HTML内容,每个页面保存为独立的HTML文件。
本文介绍了一个使用Python编写的贴吧爬虫程序,用户可以输入贴吧名、起始页和结束页,程序将在当前目录下创建相应的文件夹,并下载指定范围内的所有页面HTML内容,每个页面保存为独立的HTML文件。
~~~ 1.1准备工作
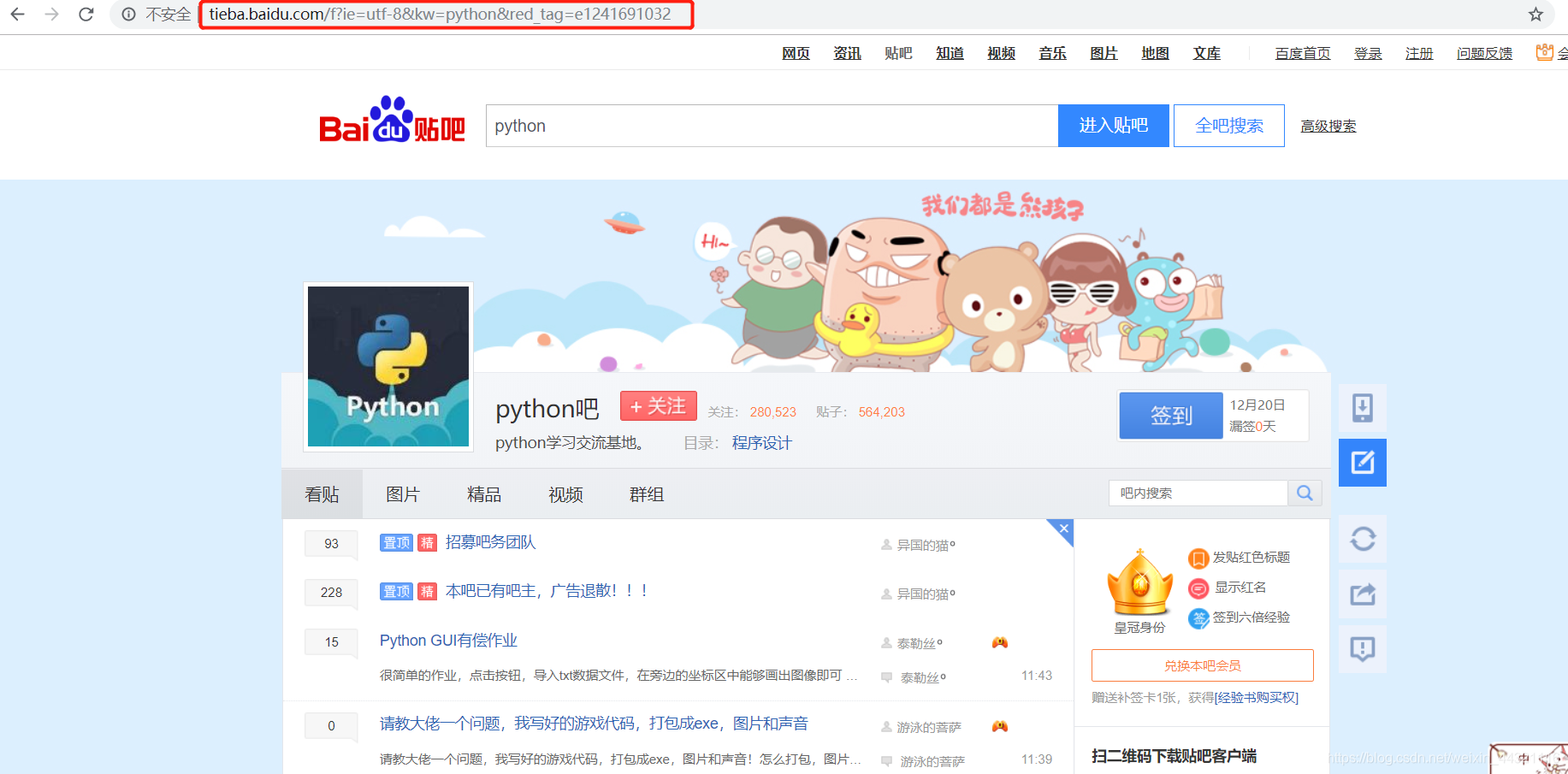
解读http://tieba.baidu.com/f?kw=python&ie=utf-8&pn=50
1 pn == 0
2 pn == 50
3 pn == 100
n pn == (n-1)*50
~~~ 1.2编写代码
import urllib.request
import urllib.parse
import os
"""需求:输入吧名,输入起始页,输入结束页,然后在当前文件夹中创建一个
以吧名为名称的文件夹,里面是每一页html内容,文件名是“吧名_页码.html”
"""
url_1 = 'http://tieba.baidu.com/f?ie=utf-8&'
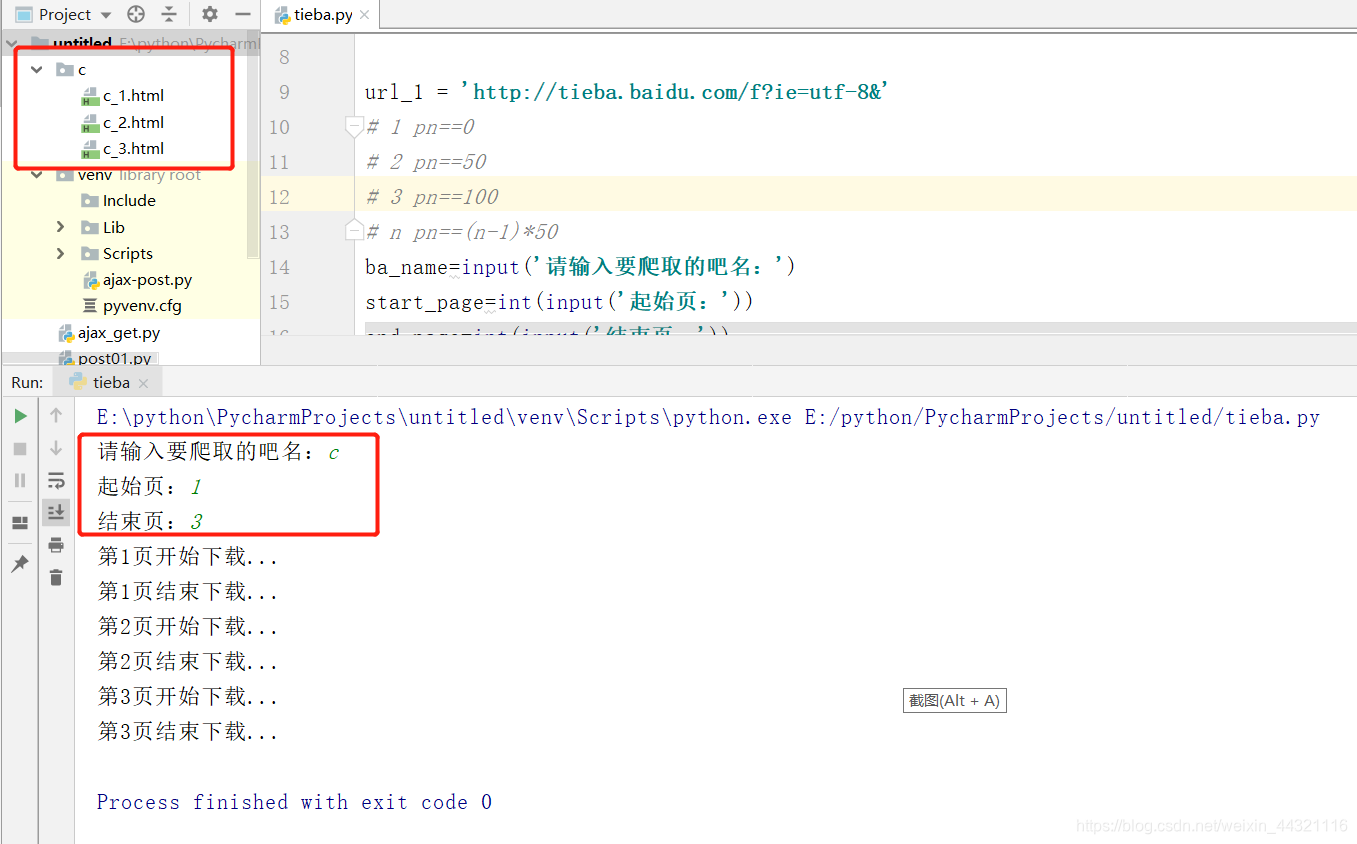
ba_name=input('请输入要爬取的吧名:')
start_page=int(input('起始页:'))
end_page=int(input('结束页:'))
# 创建文件夹,并判断文件夹是否存在
if not os.path.exists(ba_name):
os.mkdir(ba_name)
#循环,依次爬取每一页数据
for page in range(start_page,end_page+1):
#拼接url
data={
'kw':ba_name,
'pn':(page-1)*50
}
data=urllib.parse.urlencode(data)
#生成指定的url
url_t=url_1+data
#伪装头部
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',
}
#构建请求
request=urllib.request.Request(url=url_t,headers=headers)
# 发送请求
response=urllib.request.urlopen(request)
# 生成文件名
filename=ba_name+'_'+str(page)+'.html'
# 拼接文件路径
filepath=ba_name+'/'+filename
print('第%s页开始下载...'% page)
# 在文件中写内容
with open(filepath,'wb') as fp:
fp.write(response.read())
print('第%s页结束下载...'% page)

















 5854
5854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









