







 本文详细介绍如何在Hadoop环境中搭建Spark集群,包括主机选择、hosts文件配置、Java环境设置、Spark下载与配置、环境变量设置、Master与Slave节点配置,以及集群启动与验证步骤。
本文详细介绍如何在Hadoop环境中搭建Spark集群,包括主机选择、hosts文件配置、Java环境设置、Spark下载与配置、环境变量设置、Master与Slave节点配置,以及集群启动与验证步骤。
Spark集群环境搭建
本例中的主机均采用Hadoop配置中的主机。
Hadoop集群配置请参看链接:Hadoop集群配置
一、安装spark前的准备
1.选定主机
一台主机作为Master,另外一台主机作为Slave1节点
2.配置hosts文件
192.168.1.115 Master
192.168.1.129 Slave1
3.配置java环境
二、安装sprak
1.下载spark
官网[添加链接描(http://spark.apache.org/)
进入到/usr/local目录下
$ sudo wegt http://spark.apache.org/
$ sudo mv spark-2.1.0-bin-hadoop-2.1 spark
$ sudo chown -R hadoop:hadoop ./spark #hadoop是当前登录linux系统的用户名
2.配置环境变量
$ sudo vim ~/.bashrc
在里面加入
export SPARK_HOME=/usr/local/spark
export PATH=
P
A
T
H
:
PATH:
PATH:SPARK_HOME/bin:$SPARK_HOME/sbin
运行source命令使配置生效
$ source ~/.bashrc
3.spark文件配置
(1)在Master节点上面执行
$ cd /usr/local/spark/conf
$ sudo cp slaves.template slaves
$ sudo vim slaves
把里面的localhost替换成Slave1
(2)配置spark-env.sh文件
$ sudo cp spark-env.sh-example spark-env.sh
$ sudo vim spark-env.sh
在里面添加以下内容
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_IP=192.168.1.115
(192.168.1.115应该替换成你相应的ip地址)
4.配置Slave1节点
首先在Master节点执行如下命令,将Master节点上的/usr/local/spark文件夹复制到各个Slave下面
$ cd /usr/local
$ tar -zcf ~/spark.master.tar.gz ./spark
$ cd ~
$ sudo scp ./spark.master.tar.gz Slave1:/home/hadoop
接下来在Slave1节点执行以下命令
$ sudo rm -rf /usr/local/spark/
$ sudo tar -zxvf ~/spark.master.tar.gz -C /usr/local
$ sudo chown -R hadoop /usr/local/spark
三、启动Spark集群
1.启动Hadoop集群
在Master节点执行如下命令:
$ cd /usr/local/hadoop
$ sbin/start-all.sh
2.启动Master节点
$ cd /usr/local/spark
$ sbin/start-master.sh
3.启动Slave节点
$ sbin/start-slaves.sh
4.在Master主机上打开浏览器,访问http://master:8080,就可以看见spark独立集群管理器的集群信息。
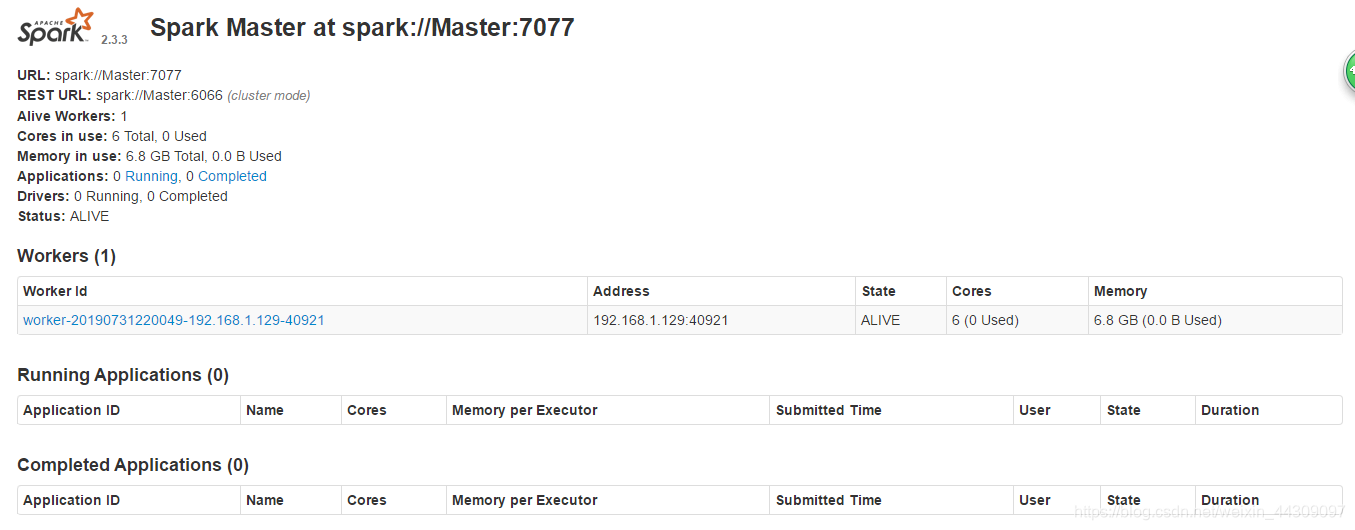
5.关闭spark集群
$ sbin/stop-master.sh
$ sbin/stop-slaves.sh
$ cd /usr/local/hadoop/
$ sbin/stop-all.sh
第七天:Spark集群环境搭建
最新推荐文章于 2022-01-14 13:24:55 发布

















 7297
7297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









