



 本文探讨了K-means聚类算法的关键问题,包括如何确定K值、初始质心的选择方法及其对结果的影响,以及算法的收敛性。通过实例解析,帮助读者深入理解K-means的工作原理。
本文探讨了K-means聚类算法的关键问题,包括如何确定K值、初始质心的选择方法及其对结果的影响,以及算法的收敛性。通过实例解析,帮助读者深入理解K-means的工作原理。
K-means聚类过程图示
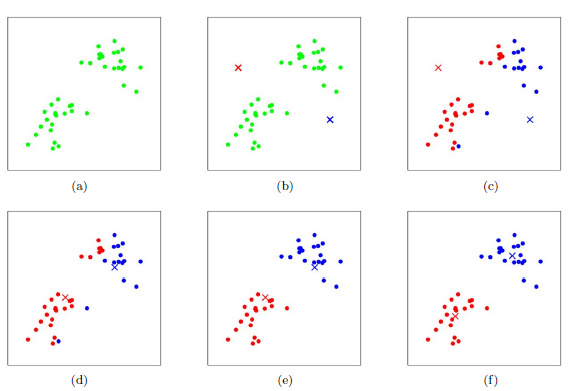
关于K-Means的几个问题
ßK值怎么定?
——主要取决于经验,通常的做法是多尝试几个K值,看分成几类的结果更好解释,更符合分析目的等。
ß初始的K个质心怎么选?
——最常用的方法是随机选,初始质心的选取对最终聚类结果有影响,因此算法一定要多执行几次,哪个结果更合理,就用哪个结果。 有一些优化的方法,例如:选择彼此距离最远的点。
ßK-Means会不会陷入一直选质心的过程?
——不会,K-Means一定会收敛,大致思路是利用SSE的概念(也就是误差平方和),可证明这个函数是可以最终收敛的函数。
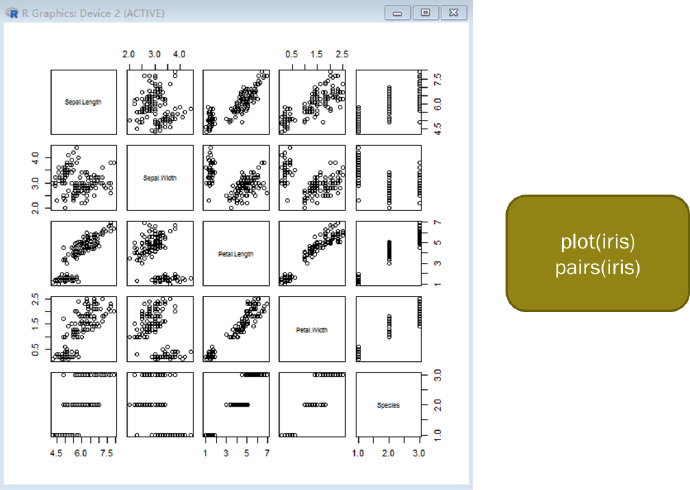
iris各列的散点图



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











